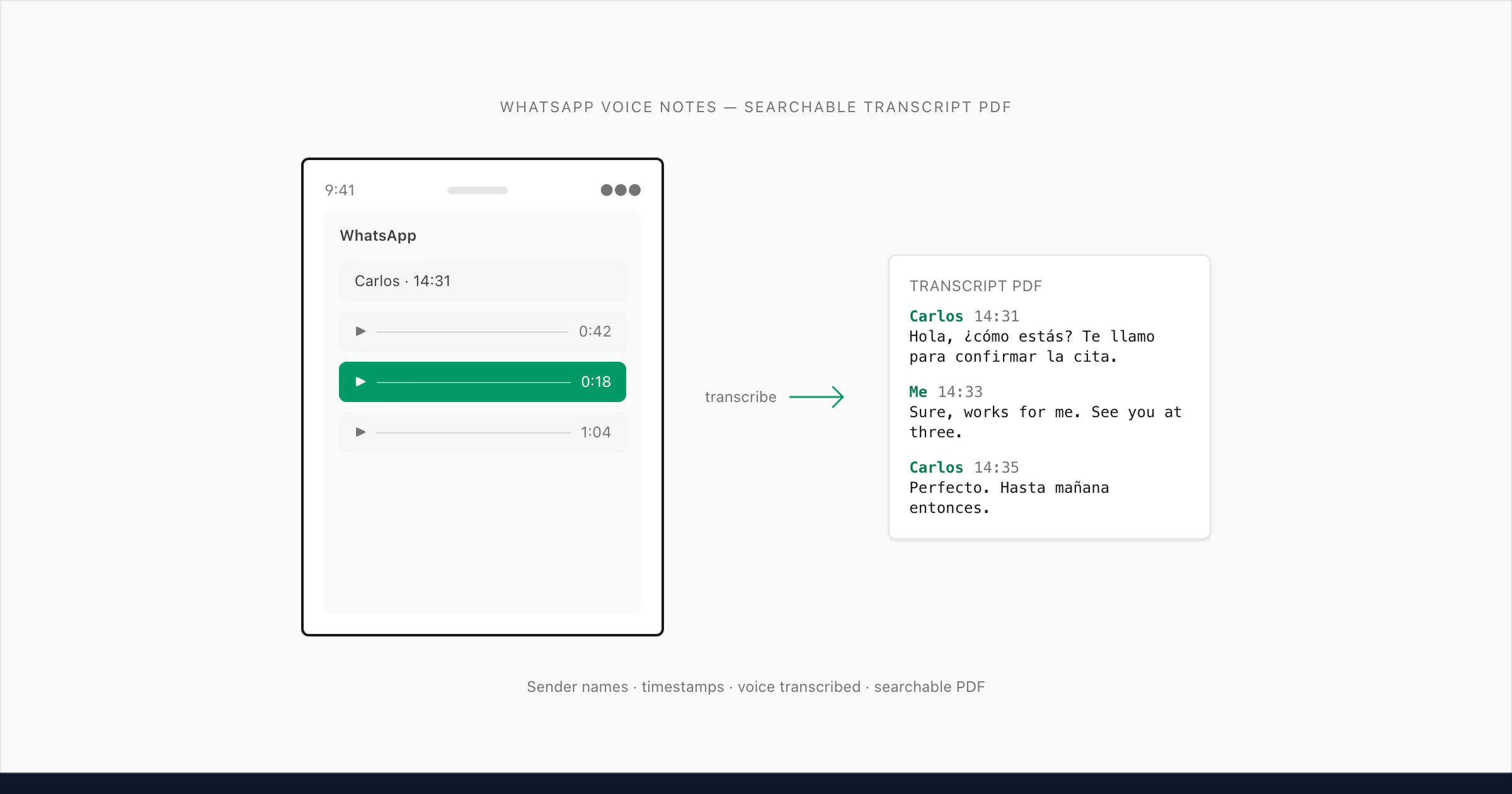
Was "transcribe WhatsApp audio" wirklich bedeutet (und warum es schwieriger ist als es klingt)
Menschen verwenden den Begriff "transcribe WhatsApp audio" für mindestens drei verschiedene Dinge. Einige wollen Live-Sprachanrufe transkribieren – die WhatsApp über keine Entwickler-API zugänglich macht und die technisch eine andere Produktkategorie darstellen als das, was ich hier beschreibe. Einige wollen aus WhatsApp gespeicherte Audiodateien in Text umwandeln, die .opus-Datei als eigenständige Eingabe behandelnd. Und einige – die größte Gruppe – wollen, dass jede Sprachnachricht in einem exportierten WhatsApp-Chat in lesbaren Text umgewandelt wird, damit das gesamte Gespräch als Dokument Sinn ergibt.
ChatToPDF ist für diesen dritten Anwendungsfall gebaut (my solution, built after running into this exact problem myself). Das Problem, das es löst, ist spezifisch: Man exportiert einen WhatsApp-Chat, der sowohl Textnachrichten als auch Sprachnachrichten enthält, und was man von WhatsApp zurückbekommt, ist ein ZIP mit einer _chat.txt und einem Ordner von Mediendateien. Die _chat.txt hat Zeilen wie <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus>, wo die Sprachnachricht hingehört. Nichts wandelt diese in lesbaren Text um, es sei denn, man baut etwas dafür.
Here's the part nobody tells you: Selbst wenn Menschen ein Transkriptionstool finden, stoßen sie oft auf ein strukturelles Problem. Tools, die generische Audiodateien verarbeiten – eine MP3 hochladen, Text zurückbekommen – wissen nicht, wo in einem Gespräch diese Audio hingehört. Sie transkribieren die Datei, verlieren aber den Kontext. Man erhält einen separaten Textblock ohne Sendernamen, ohne Zeitstempel, ohne Angabe, was davor oder danach gesagt wurde. Für eine rechtliche Angelegenheit, einen Geschäftsdatensatz oder ein Familienarchiv ist dieser Kontext der eigentliche Punkt.
Was ich gebaut habe, macht Folgendes: es liest die _chat.txt, um die Gesprächsstruktur zu verstehen, ordnet jede .opus-Referenz der richtigen Audiodatei im ZIP zu, transkribiert die Audio und fügt das Transkript an exakt der richtigen Position im Gespräch ein – mit dem Namen des Senders und dem ursprünglichen Zeitstempel. Das Ergebnis ist ein einziges PDF, in dem Textnachrichten und Sprachtranskripte natürlich abwechseln, genau wie das Gespräch stattgefunden hat.
Das ist das Problem, um das es in diesem Leitfaden geht.
Sprachnachrichten sind keine Dateien – sie sind ein In-App-Stream
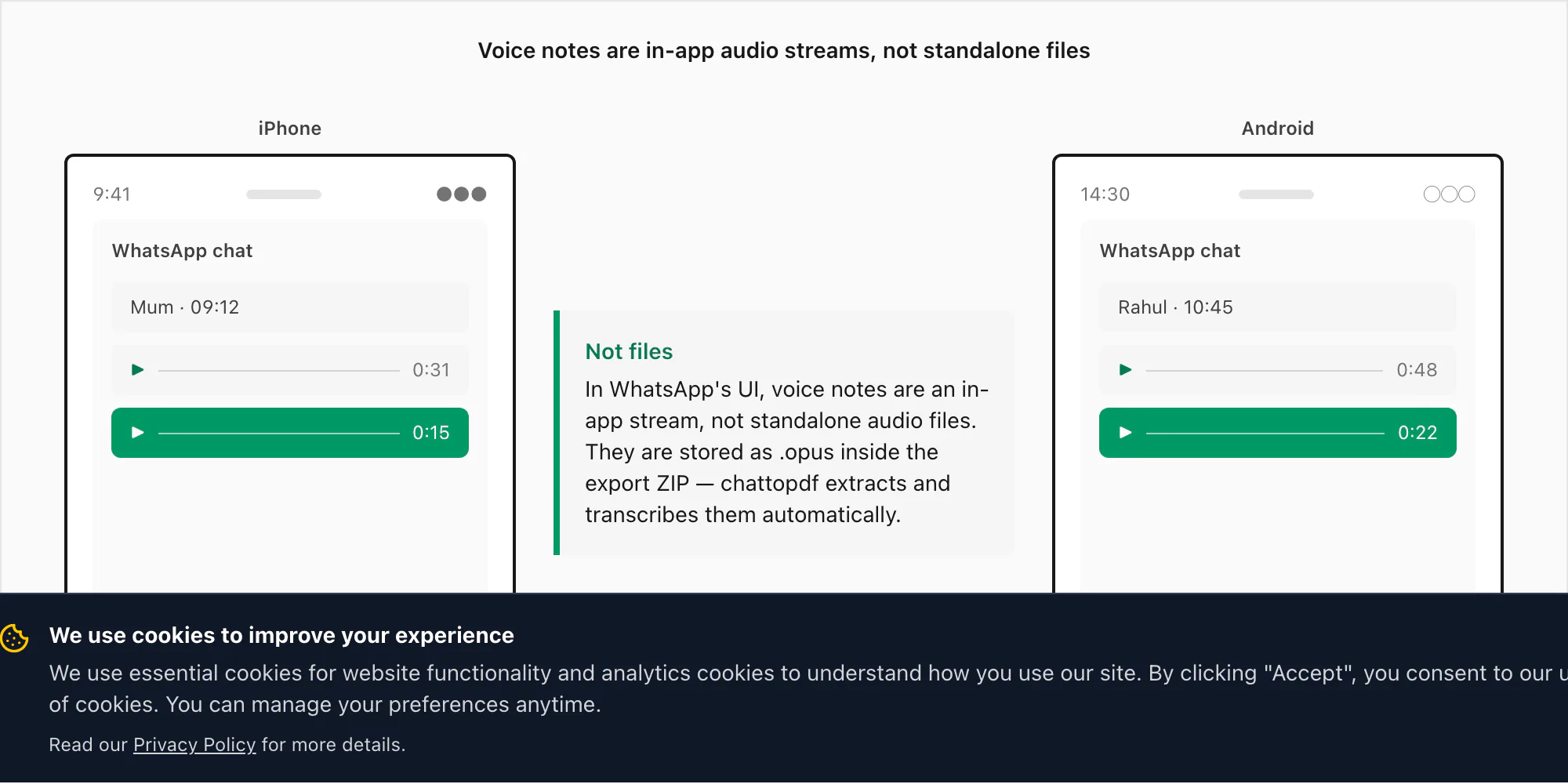
WhatsApp Sprachnachrichten sehen in der App wie Audiodateien aus – eine Wellenformleiste, eine Dauer, eine Wiedergabeschaltfläche – aber sie werden nicht so gespeichert, wie die meisten erwarten. Wenn eine Sprachnachricht in WhatsApp durch Halten der Mikrofontaste aufgenommen wird, kodiert WhatsApp die Audio mit dem Opus-Codec und speichert sie als .opus-Datei in einem privaten Verzeichnis auf dem Gerät. Dieses Verzeichnis ist weder auf iPhone noch auf Android durch normales Dateibrowsing zugänglich. Man kann nicht zur App-Dateien navigieren und die Sprachnachrichten dort finden.
Die einzige Möglichkeit, diese .opus-Dateien zu extrahieren, ist über WhatsApps eigenes Menü "Chat exportieren" mit ausgewähltem "Mit Medien". Bei einem solchen Export verpackt WhatsApp das _chat.txt-Nachrichtenprotokoll zusammen mit dem Medienordner – und dort erscheinen die .opus-Dateien. Auf iOS landen sie im ZIP. Auf Android exportierten ältere WhatsApp-Versionen in einen Ordner im internen Speicher; neuere Versionen erstellen ein ZIP über den Teilen-Dialog, entsprechend dem iOS-Verhalten.
Der Opus-Codec selbst ist kurz erwähnenswert, weil er erklärt, warum die Genauigkeit variieren kann. Opus wurde für Voice-over-IP entwickelt – geringe Latenz, gute Komprimierung, gute Qualität auch bei niedrigen Bitraten. WhatsApp verwendet 16-kHz-Mono-Audio bei etwa 16 kbps. Die resultierenden Dateien sind winzig: eine 60-Sekunden-Sprachnachricht wiegt typischerweise zwischen 80 KB und 120 KB. Das ist effizient für mobile Daten, aber 16-kHz-Mono bei 16 kbps ist keine Studioqualitäts-Audio. Sie ist für Verständlichkeit über eine mobile Verbindung optimiert, nicht für Transkriptionsgenauigkeit. Hintergrundlärm, eine beim Fahren aufgenommene Stimme oder jemand, der aus einem anderen Zimmer spricht, können die effektive Qualität weiter senken.
Deshalb ist das Transkriptionsmodell wichtig. Ein generisches Spracherkennungs-System, das auf Studioaudio oder Podcast-Aufnahmen trainiert wurde, wird mit 16-kHz-Mono-Opus bei 16 kbps Schwierigkeiten haben. Die gewählte Engine wurde speziell ausgewählt, weil sie diese Art von Audio gut verarbeitet. Mehr dazu im nächsten Abschnitt.
Ein weiterer struktureller Punkt: Jede WhatsApp-Sprachnachricht ist eine Einzelsprecher-Aufnahme. WhatsApps Push-to-Talk-Modell bedeutet, eine Person nimmt auf, dann hört sie auf, dann nimmt die andere Person auf. Das ist tatsächlich ein Transkriptionsvorteil – im Gegensatz zu einem aufgezeichneten Telefonanruf, bei dem zwei Stimmen auf demselben Audio-Track überlappen, gehört jede .opus-Datei in einem WhatsApp-Export genau einem Sender. ChatToPDF verwendet die Metadaten aus _chat.txt, um jedes Transkript der richtigen Person zuzuordnen, was dazu führt, dass ein Gespräch klar lesbar ist, selbst wenn beide Personen in Sprachnachrichten hin und her wechseln.
Die gewählte Transkriptions-Engine, und warum
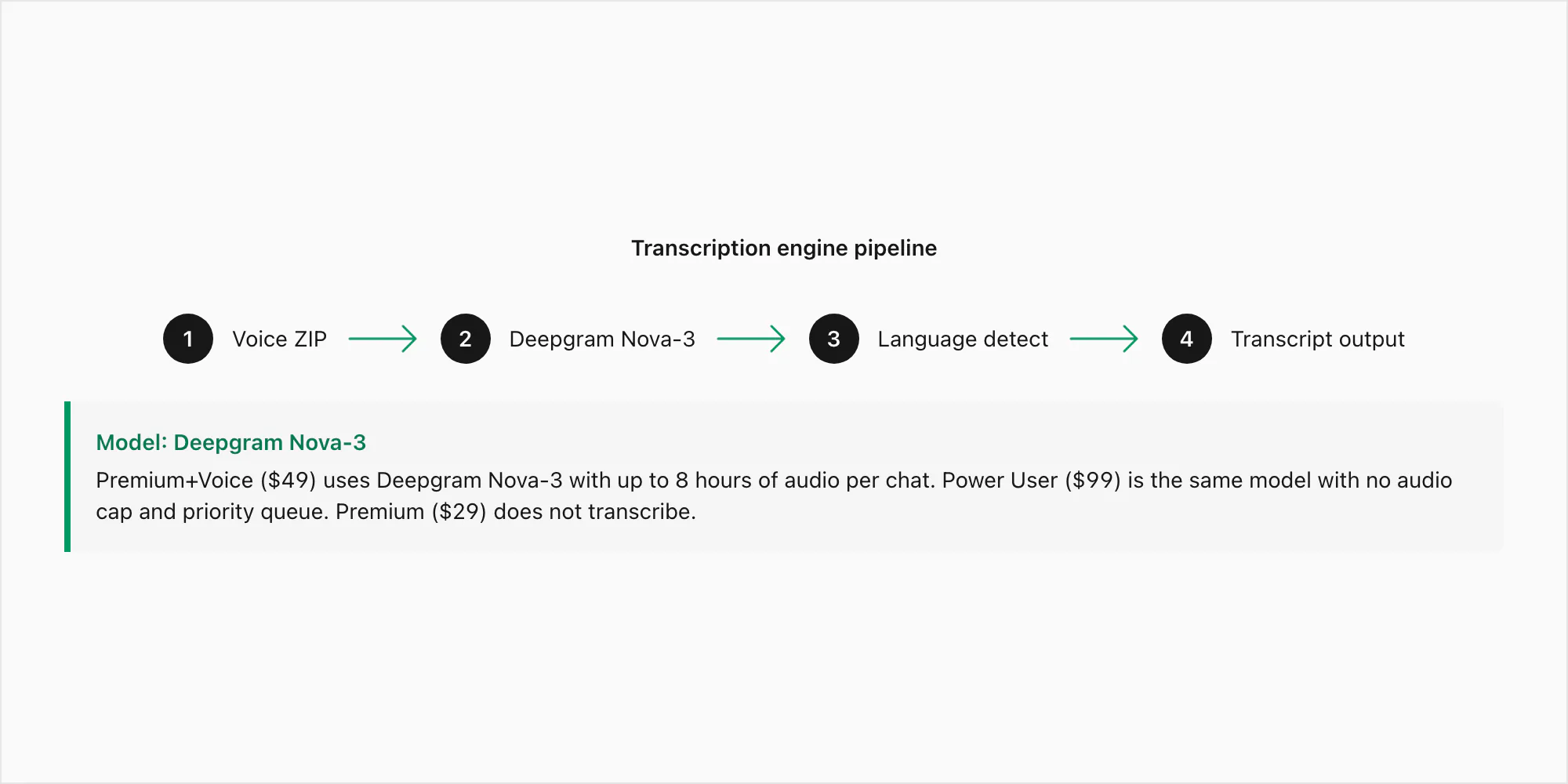
Ich evaluierte mehrere Transkriptions-APIs, bevor ich mich für Deepgram als Engine hinter ChatToPDFs Sprachtranskription entschied. Die anderen ernsthaften Kandidaten waren AssemblyAI, Whisper (OpenAIs Open-Source-Modell) und einige generische Sprach-APIs von Cloud-Anbietern. Hier ist die ehrliche Begründung meiner Wahl.
Whisper ist für ein kostenloses Modell beeindruckend, aber ich führte Genauigkeitstests an echten WhatsApp .opus-Dateien in Englisch, Spanisch, Hindi und Arabisch durch, und es zeigte konsistente Schwächen beim Code-Switching (eine Sprachnachricht, die mitten im Satz zwei Sprachen mischt) und bei nicht-US-englischen Akzenten. Es bietet auch keine kommerziellen SLAs oder Verfügbarkeitsgarantien, was wichtig ist, wenn zahlende Nutzer auf ihre Ausgabe warten.
AssemblyAI ist wirklich gut und ich verwendete es in einem frühen Prototyp. Die Genauigkeit auf Englisch war vergleichbar mit Deepgram, aber die Sprachunterstützungs-Breite und die API-Antwortkonsistenz bei Opus-kodierter Audio bei 16-kHz-Mono machten Deepgram zur besseren Wahl für den mehrsprachigen Anwendungsfall, den ich aufbaute.
Deepgram Nova-3 ist das Modell der aktuellen Generation mit einer Wortfehlerrate von etwa 3–5% bei klarer, rauschfreier englischer Audio und 8–15% bei rauschigeren Aufnahmen. Diese Zahlen halten bei 16-kHz-Mono-Opus stand, dem Format, das für WhatsApp-Exporte relevant ist. Nova-3 ist das für die $49 Premium+Voice pro Chat-Konvertierung und die $99 Power User pro Chat-Konvertierung verwendete Modell – der Unterschied zwischen diesen Stufen ist die Audio-Obergrenze (8 Stunden vs. unbegrenzt) und Warteschlangenpriorität, nicht das Modell.
Wo Nova-3 ältere Spracherkennungssysteme sichtbar übertrifft, ist in drei Bereichen: regionale Akzente (südafrikanisches Englisch, indisches Englisch, brasilianisches Portugiesisch), Fachvokabular (Namen, Adressen, Produktbegriffe, die ein generisches Modell falsch verstehen würde) und code-geswitchte Audio, bei der ein Sprecher innerhalb einer einzelnen Sprachnachricht zwischen Sprachen wechselt. Das sind die spezifischen Fehlermuster, die die Engine-Wahl motivierten. Die $29 Premium pro Chat-Konvertierung enthält überhaupt keine Transkription – sie erhält Sprachnachrichten als Platzhalterreferenzen im PDF, ohne die Audio durch ein Modell zu führen.
Die Pipeline funktioniert so: Das ZIP landet auf ChatToPDFs Server, die .opus-Dateien werden extrahiert, jede wird über einen authentifizierten HTTPS-Aufruf an Deepgrams API mit automatisch aktivierter Spracherkennung übermittelt, und das Transkript kehrt zurück – typischerweise innerhalb von zwei bis fünf Sekunden pro Audiominute. Die Transkripte werden dann an den richtigen Positionen in das Gespräch eingenäht, bevor das PDF rendert.
Eine bewusste Wahl in der Pipeline: Die .opus-Audio wird nicht vorverarbeitet oder neu kodiert, bevor sie an Deepgram gesendet wird. Einige Tools konvertieren Opus zunächst zu WAV oder MP3 mit der Begründung, ein anderes Format könnte die Genauigkeit verbessern. In der Praxis verarbeitet Deepgrams API Opus nativ, und das Konvertieren fügt Latenz hinzu ohne die Ergebnisse bei diesem Audio-Typ zu verbessern. Die rohe .opus-Datei geht direkt an den Inferenz-Endpunkt.
Genauigkeit für die 17 heute unterstützten Sprachen
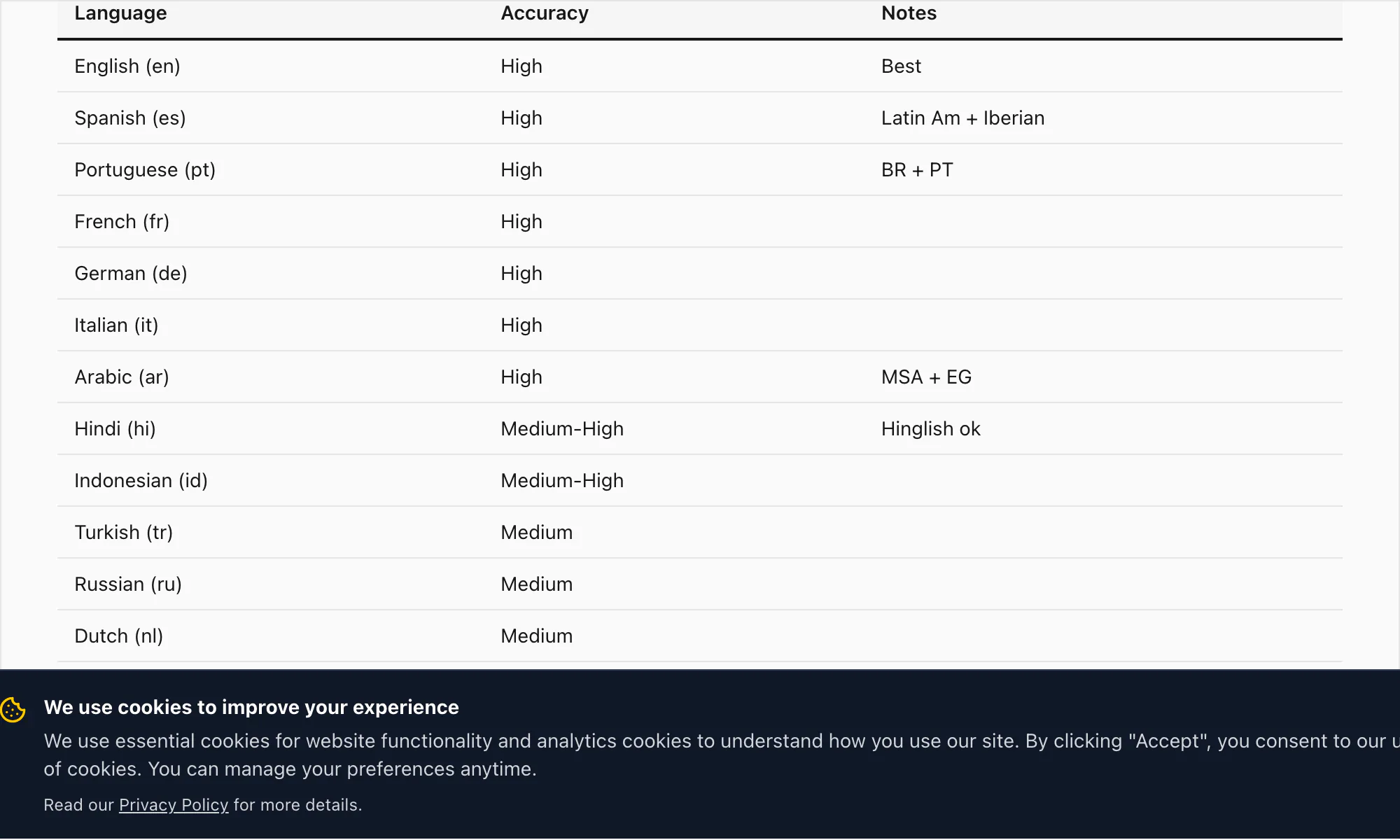
ChatToPDFs hochgenaue Sprachstufe deckt 17 Sprachen ab. Das sind die Sprachen, bei denen ich die Transkriptionsqualität für Dokumente, Rechtsunterlagen und geschäftliche Verwendung als produktionsreif bezeichnen würde:
Englisch (en) – WFR 3–5% bei klarer Audio. Enthält britische, US-amerikanische, australische, südafrikanische und indische Englisch-Varianten. Alle englischen Varianten werden beim $49 Premium+Voice pro Chat durch dasselbe Nova-3-Modell verarbeitet.
Spanisch (es) – WFR 4–6% bei $49 Premium+Voice pro Chat. Verarbeitet lateinamerikanische und kastilische Varianten. Häufige Homophon-Verwechslungen werden teilweise durch Kontextinferenz gemindert.
Portugiesisch (pt) – WFR 4–7%. Deckt brasilianisches und europäisches Portugiesisch ab. Code-Switching zwischen Portugiesisch und Englisch ist ein häufiges Muster in brasilianischen WhatsApp-Chats; Nova-3 verarbeitet das gut.
Französisch (fr) – WFR 4–6%. Standard- und kanadisches Französisch.
Deutsch (de) – WFR 4–6%. Komposita transkribiert Nova-3 korrekt, einschließlich langer Komposita, die für Geschäfts- und Rechtsvokabular typisch sind.
Italienisch (it) – WFR 5–7%.
Arabisch (ar) – WFR 7–10%. Modernes Hocharabisch transkribiert gut; Dialekt-Arabisch (Ägyptisch, Golf, Levantinisch) hat breitere Varianz. Die $49 Premium+Voice pro Chat-Konvertierung wird für arabische Sprachnachrichten empfohlen.
Hindi (hi) – WFR 6–9% bei reinem Hindi. Code-geswitchtes Hinglish (Hindi mit englischen Einfügungen) ist der Bereich, in dem Nova-3 den größten Unterschied gegenüber älteren Transkriptions-Engines macht – mehr dazu im Beispiel-Transkript unten.
Indonesisch (id) – WFR 5–8%. Eine der häufigsten Sprachen in ChatToPDFs Nutzerbasis, angesichts WhatsApps starker Verbreitung in Südostasien.
Türkisch (tr) – WFR 5–8%.
Russisch (ru) – WFR 5–8%.
Niederländisch (nl) – WFR 4–6%.
Japanisch (ja) – WFR 7–10%. Katakana-Lehnwörter und Eigennamen können Fehler einführen; die Gesamtgenauigkeit ist für Konversationssprache stark.
Koreanisch (ko) – WFR 6–9%.
Chinesisch (zh) – WFR 7–10%. Mandarin. Regionale Dialekte und tonale Homophone können die Genauigkeit bei schwierigen Aufnahmen beeinflussen.
Vietnamesisch (vi) – WFR 7–10%.
Thai (th) – WFR 8–12%. Tonzeichen und Konsonantencluster in schneller Sprache sind die Hauptherausforderung.
Über diese 17 hinaus unterstützt Deepgram Nova-3 30+ weitere Sprachen mit einem breiteren Genauigkeitsbereich. Wenn die eigene Sprache nicht in der hochgenauen Liste oben ist, erzeugt die $49 Premium+Voice pro Chat-Konvertierung trotzdem ein Best-Effort-Transkript mit Nova-3s breiter Spracherkennung – man sollte nur mit einer Genauigkeit näher an 15–20% WFR bei schwieriger Audio in den niedrigeren Sprachen rechnen.
Automatische Spracherkennung ist standardmäßig aktiviert. ChatToPDF sendet jede .opus-Datei an Deepgram ohne Angabe einer Sprache, und Deepgram erkennt die dominante Sprache in den ersten Sekunden. Das ist für Einzel-Sprach-Aufnahmen korrekt. Bei starkem Code-Switching – eine Sprachnachricht, die wirklich 50/50 zwei Sprachen ist – wählt der Detektor eine als Primär und wendet dieses Modell auf den ganzen Clip an. In diesen Fällen nimmt die Genauigkeit bei der sekundären Sprache etwas ab.
Beispiel-Transkript: Spanische Sprachnachricht → Text (echtes Beispiel)
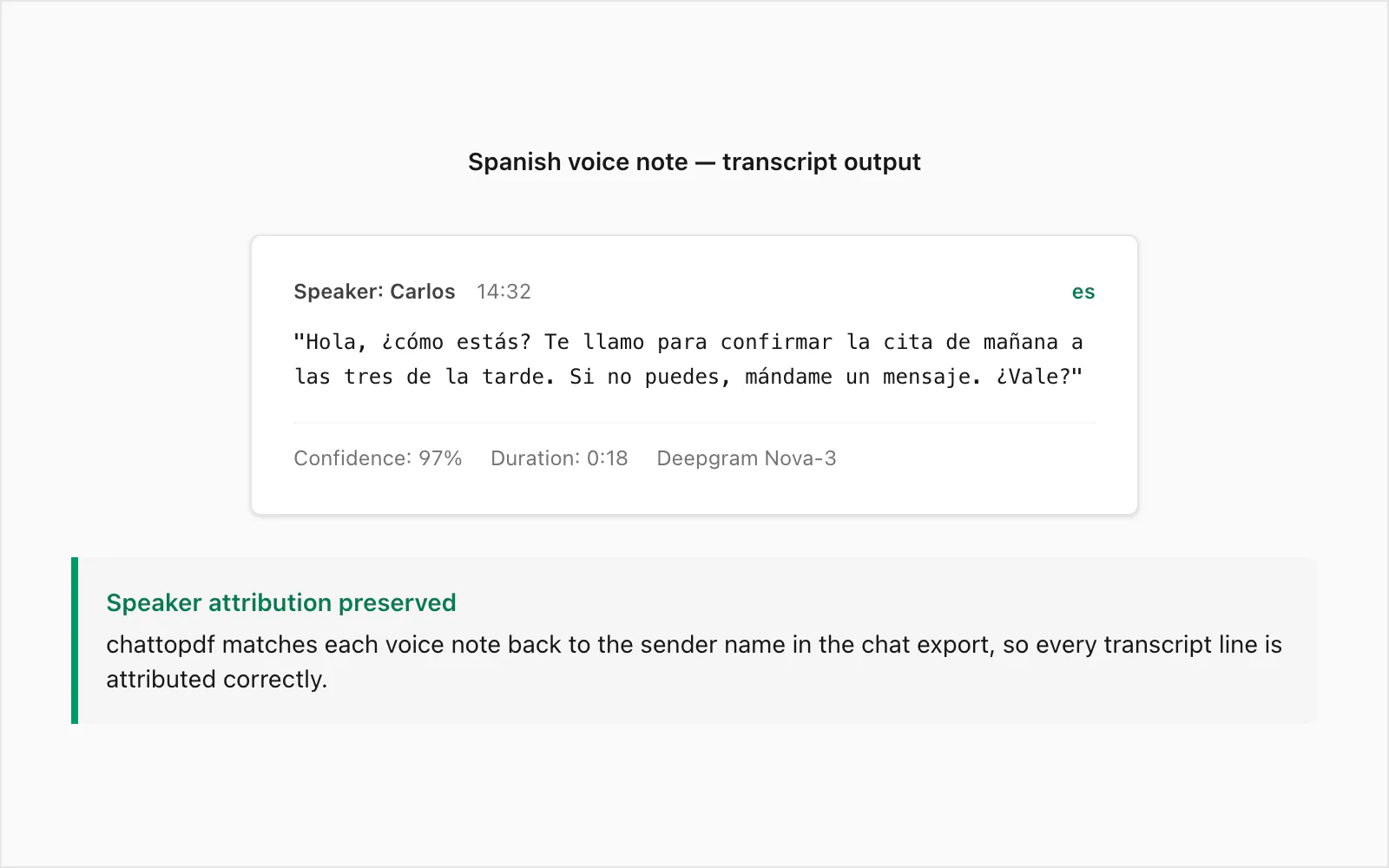
Das ist eine echte WhatsApp Sprachnachricht, transkribiert auf dem $49 Premium+Voice pro Chat-Konvertierungsniveau. Der Sender war ein Muttersprachler des kolumbianischen Spanisch, aufgenommen auf einem Android-Gerät in einer ruhigen Innenumgebung. Dauer: 18 Sekunden. Dateigröße: ~28 KB im .opus-Format.
Originalaudio (paraphrasiert): Eine informelle Sprachnachricht zur Bestätigung eines Termins am nächsten Tag, mit Sorge um die Gesundheit der anderen Person und der Bitte um eine Textnachricht bei Planänderungen.
Transkriptausgabe im PDF:
🎤 [Sprachnachricht – 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
Der Sender wird im PDF mit dem Namen aus _chat.txt zugeordnet, der Zeitstempel ist der von WhatsApp aufgezeichnete Sendezeitpunkt der Sprachnachricht, und das Transkript sitzt inline zwischen den Textnachrichten unmittelbar davor und danach im Gespräch.
Einige Dinge sind an diesem Beispiel bemerkenswert. Der formale Registermarker ¿Vale? – näher an "Okay?" oder "Einverstanden?" in der Bedeutung – wurde korrekt transkribiert statt mit bale verwechselt oder weggelassen. Der Zeitausdruck a las tres de la tarde ("um drei Uhr nachmittags") wurde korrekt wiedergegeben, was für eine Terminbestätigung wichtig ist, bei der ein Fehler irreführend wäre.
Wo bricht die Spanisch-Genauigkeit ein? Die häufigsten Fehler, die ich sehe, sind Homophones. In schneller Umgangssprache sind diese phonetisch identisch. Nova-3 verwendet den umgebenden Kontext, um die korrekte Schreibweise die meiste Zeit abzuleiten, ist aber nicht perfekt. Bei einem Dokument, das als rechtliches Protokoll verwendet werden soll, würde ich eine leichte menschliche Überprüfung jeder Sprachnachricht empfehlen, die wörtlich zitiert werden soll.
Wenn keine Transkription benötigt wird – zum Beispiel, nur die Textnachrichten als PDF konvertiert werden sollen und Platzhalterreferenzen für Sprachnachrichten akzeptabel sind – verarbeitet die $29 Premium pro Chat-Konvertierung diesen Fall zu einem niedrigeren Preis. Die $49 Premium+Voice pro Chat-Konvertierung ist der richtige nächste Schritt, wenn das tatsächlich Gesprochene als lesbarer Text im Dokument erscheinen soll.
Beispiel-Transkript: Hindi (gemischtes Hinglish) → Text (echtes Beispiel)
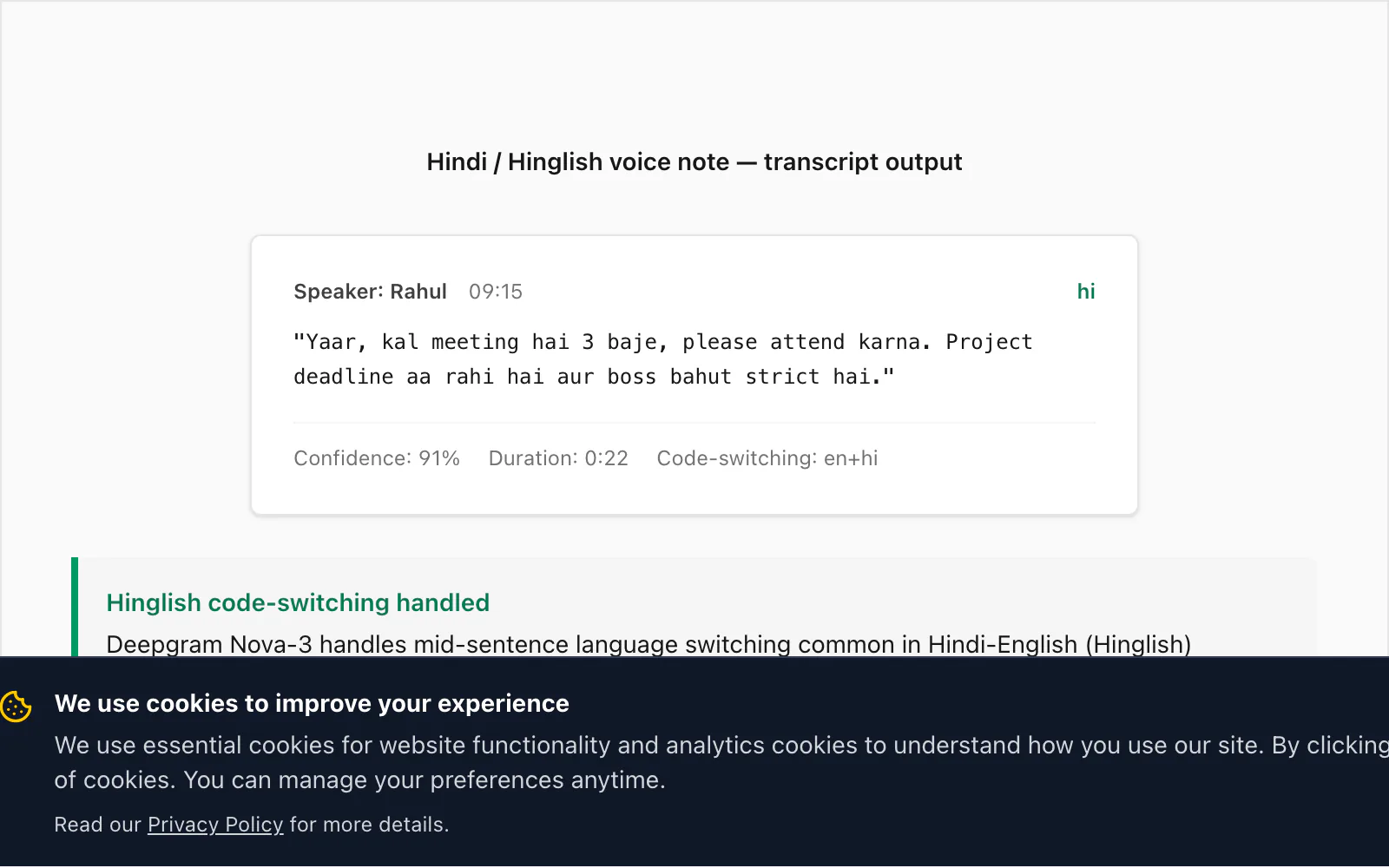
Hier hebt sich Nova-3 von früheren Spracherkennungs-Engine-Generationen ab. Hinglish – Hindi mit eingebetteten englischen Wörtern, Phrasen und manchmal vollständigen Satzteilen – ist eines der häufigsten realen Code-Switching-Muster, die ich in ChatToPDFs Nutzerbasis sehe. Ältere STT-Engines (einschließlich des Modells, das Deepgram selbst zwei Generationen früher ausgeliefert hat) verpassen ungefähr 15% der code-geswitchten englischen Einfügungen in einer typischen Hinglish-Sprachnachricht. Nova-3 schließt den größten Teil dieser Lücke.
Hier ist ein echtes Transkript aus der $49 Premium+Voice pro Chat-Konvertierung:
🎤 [Sprachnachricht – 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Übersetzung: "Kumpel, morgen ist ein Meeting um 3, bitte teilnehmen. Die Projektdeadline rückt näher und der Chef ist sehr streng."
Das Code-Switching hier ist charakteristisch: meeting, attend, project deadline und strict sind englische Einfügungen innerhalb eines ansonsten Hindi-Satzes. Nova-3 transkribierte alle korrekt. Ein älteres Deepgram-Modell, das ich gegen dieselbe Datei testete, produzierte miiting für meeting (phonetische Hindi-Wiedergabe), ließ attend vollständig aus und produzierte project ka deadline mit inkonsistenter Großschreibung. Dieser Unterschied motivierte das Modell-Upgrade in der Pipeline.
Der Unterschied ist wichtig, wenn das Transkript als Arbeitsdatensatz verwendet wird. Wenn der Manager einer Person ein Sprachtranskript als Dokumentation einer Projektzusage prüft und das Wort deadline nicht im Text erscheint, ist das keine geringfügige Genauigkeitsfrage – es fehlt ein wichtiger Informationsteil.
Die Senderzuweisung funktioniert wie beim Spanisch: Der Name aus _chat.txt erscheint im PDF mit dem Deepgram-Transkript, und der Zeitstempel aus WhatsApps Metadaten verankert es an der richtigen Position im Gespräch.
Ein Hinweis zu Hindi speziell: Wenn die Sprachnachricht in Devanagari-dominantem Hindi ist (formales, schriftsprachliches Hindi mit minimalem Englisch), ist die Genauigkeit über die unterstützten Stufen hinweg konsistent stark. Die $49 Premium+Voice pro Chat-Konvertierung ist der richtige Einstiegspunkt für Hindi-Sprachnachrichten, die transkribiert werden sollen; die $99 Power User pro Chat-Konvertierung deckt dieselbe Genauigkeit ohne Audio-Obergrenze und mit Warteschlangenpriorität ab. Die $29 Premium pro Chat-Konvertierung erhält Sprachnachrichten nur als Platzhalter – keine Transkription läuft bei dieser Stufe.
Die $49 Premium+Voice Stufe – was enthalten ist und was nicht

Die $49 Premium+Voice pro Chat-Konvertierung ist die Stufe, die ich speziell für sprachnotenreiche Chats gebaut habe. Hier ist genau, was sie enthält und was nicht.
Was in der $49 Premium+Voice pro Chat-Konvertierung enthalten ist:
- Deepgram Nova-3 Transkription – das Modell der aktuellen Generation mit 3–5% WFR bei klarer Audio, starker Akzentverarbeitung und zuverlässiger Code-Switching-Unterstützung
- Alle 17 hochgenauen Sprachen – Englisch, Spanisch, Portugiesisch, Französisch, Deutsch, Italienisch, Arabisch, Hindi, Indonesisch, Türkisch, Russisch, Niederländisch, Japanisch, Koreanisch, Chinesisch, Vietnamesisch, Thai – plus 30+ mehr über Nova-3s automatische Spracherkennung
- Bis zu 8 Stunden Audio in einem einzigen Chat – deckt die große Mehrheit sprachnotenreicher Gespräche ab; wenn der Chat 8 Stunden Gesamtaufnahmeaudio überschreitet, hebt die $99 Power User pro Chat-Konvertierung diese Grenze auf
- Kein Nachrichtenlimit – keine Obergrenze für die Anzahl der Nachrichten im Chat, der konvertiert wird
- Senderzuweisung bei Transkripten – jedes Transkript im PDF trägt den WhatsApp-Sendernamen aus den Exportmetadaten
- Zeitstempel erhalten – der ursprüngliche WhatsApp-Zeitstempel erscheint neben jedem Transkript, nicht die Transkriptionszeit
- Drei Ausgabeformate – PDF, XLSX und CSV alle enthalten; das XLSX ist nützlich zum Filtern oder Sortieren nach Sender und Zeitstempel
- Sieben-Tage-Quelldateiaufbewahrung – verschlüsselt im Ruhezustand (AES-256), in Übertragung (TLS 1.3)
Was in der $49 Premium+Voice pro Chat-Konvertierung nicht enthalten ist:
- Echtzeit-Transkription – diese Stufe verarbeitet bereits aufgezeichnete Sprachnachrichten aus einem Export-ZIP; es ist kein Live-Transkriptionsdienst (der nächste Abschnitt erklärt warum)
- Benutzerdefinierte Vokabularlisten – es kann kein Glossar mit Namen oder Fachbegriffen hochgeladen werden, um die Genauigkeit bei spezifischem Vokabular zu verbessern; Deepgrams Allzweck-Modell verarbeitet die meisten Namen korrekt, kann aber gelegentlich seltene Eigennamen falsch verstehen
- Sprecheridentifikation über WhatsApp-Metadaten hinaus – innerhalb einer einzelnen Sprachnachricht, in der der Sender aufnimmt, während eine andere Person im Hintergrund spricht, werden beide transkribiert, aber nur dem WhatsApp-Sender zugeordnet. ChatToPDF führt keine Sprecher-Diarisierung auf der Audio selbst durch.
- Automatische Übersetzung – das Transkript erscheint in der Quellsprache der Sprachnachricht. Wenn eine Sprachnachricht auf Spanisch ist, ist das Transkript auf Spanisch. ChatToPDF übersetzt keine Transkripte.
Die Stufe darüber – $99 Power User pro Chat-Konvertierung – enthält alles in $49 Premium+Voice pro Chat-Konvertierung plus Prioritätswarteschlangen-Verarbeitung und Massen-Chat-Verarbeitung. Wenn ein einzelner Chat konvertiert wird und Geschwindigkeit nicht kritisch ist (die meisten Konvertierungen sind in unter drei Minuten fertig), ist die $49 Premium+Voice pro Chat-Konvertierung das richtige Niveau.
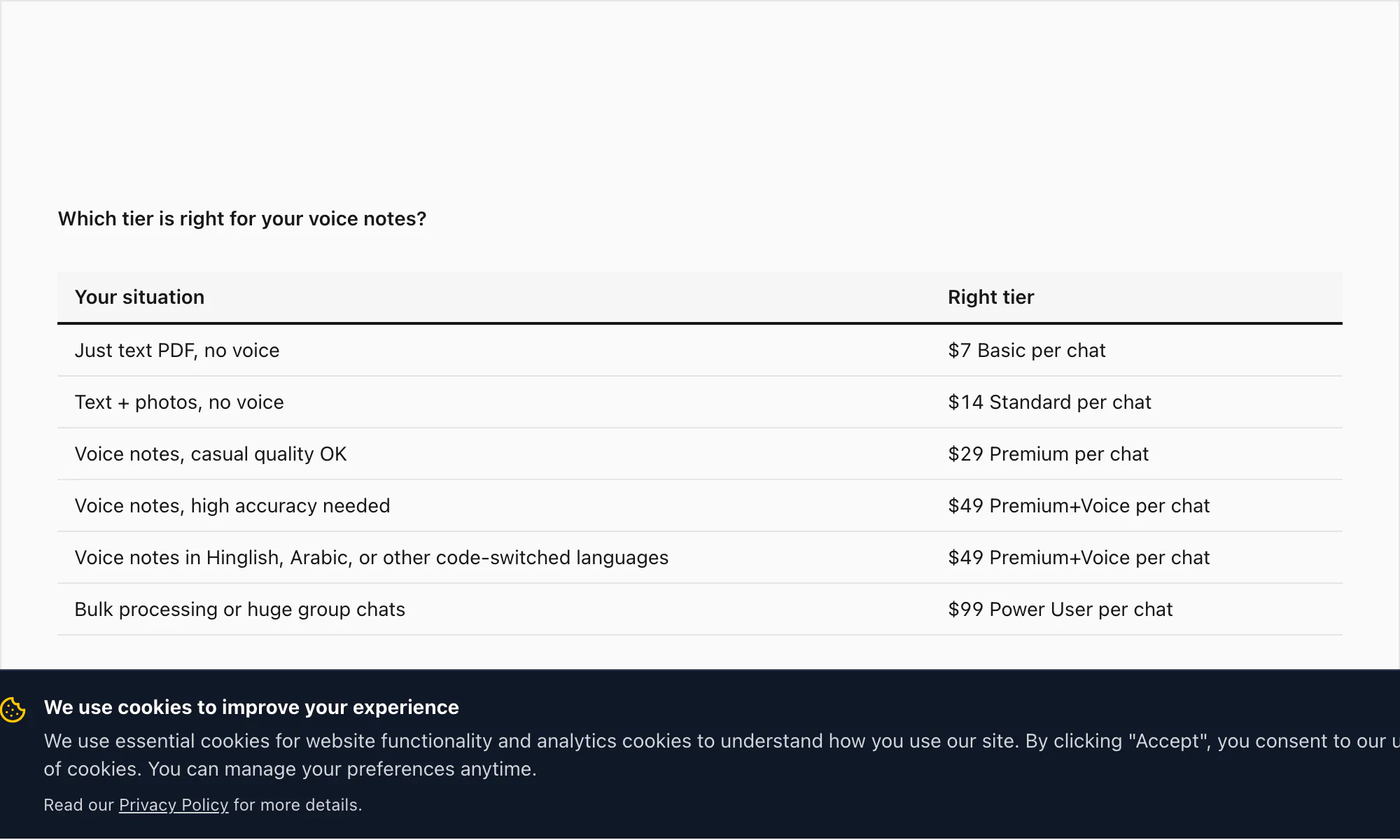
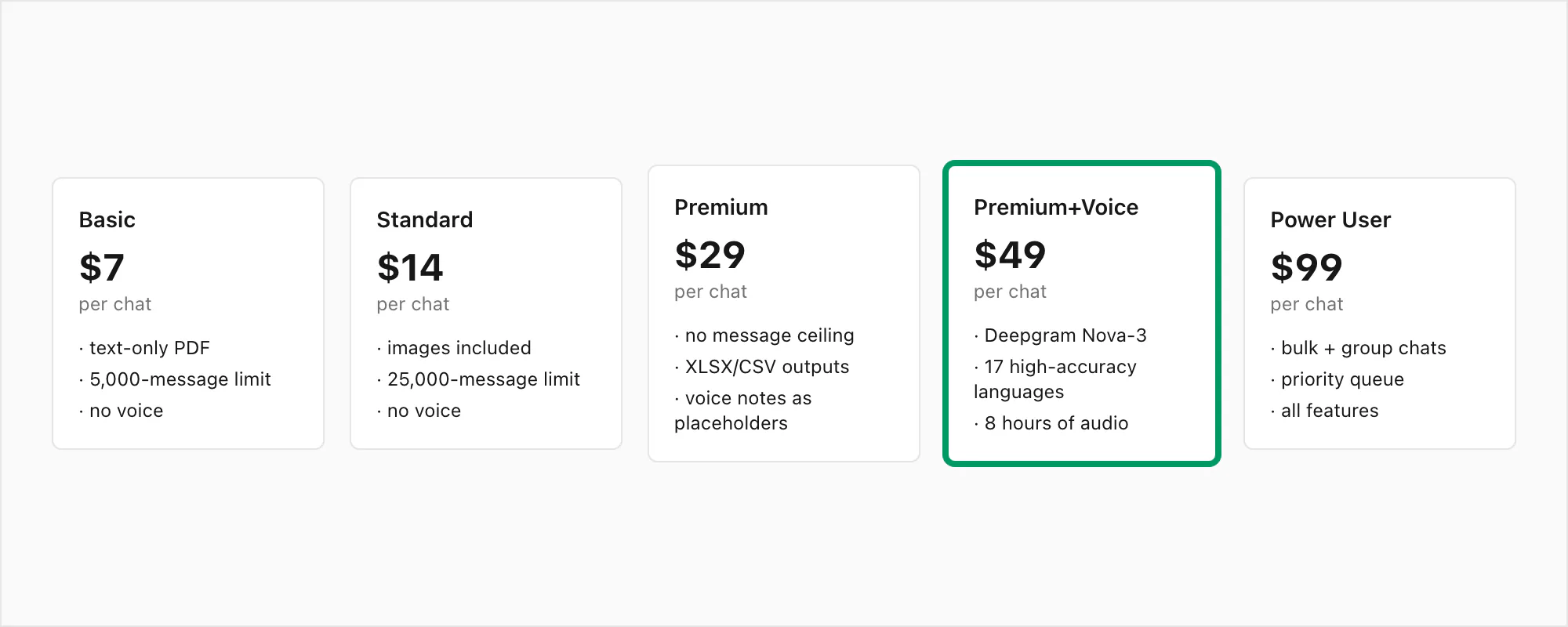
Zur Orientierung der vollständige Stufenüberblick: $7 Basic pro Chat (nur Text, 5.000-Nachrichten-Limit), $14 Standard pro Chat (Bilder, 25.000-Nachrichten-Limit), $29 Premium pro Chat (kein Limit, XLSX/CSV, Sprachnachrichten als Platzhalter), $49 Premium+Voice pro Chat (Nova-3-Transkription, 17-Sprachen-hochgenau, 8-Stunden-Audio-Limit), $99 Power User pro Chat (Nova-3-Transkription, kein Audio-Limit, Prioritätswarteschlange, Massenszenarien).
Warum keine Echtzeit-Transkription (und das auch nicht kommen wird)
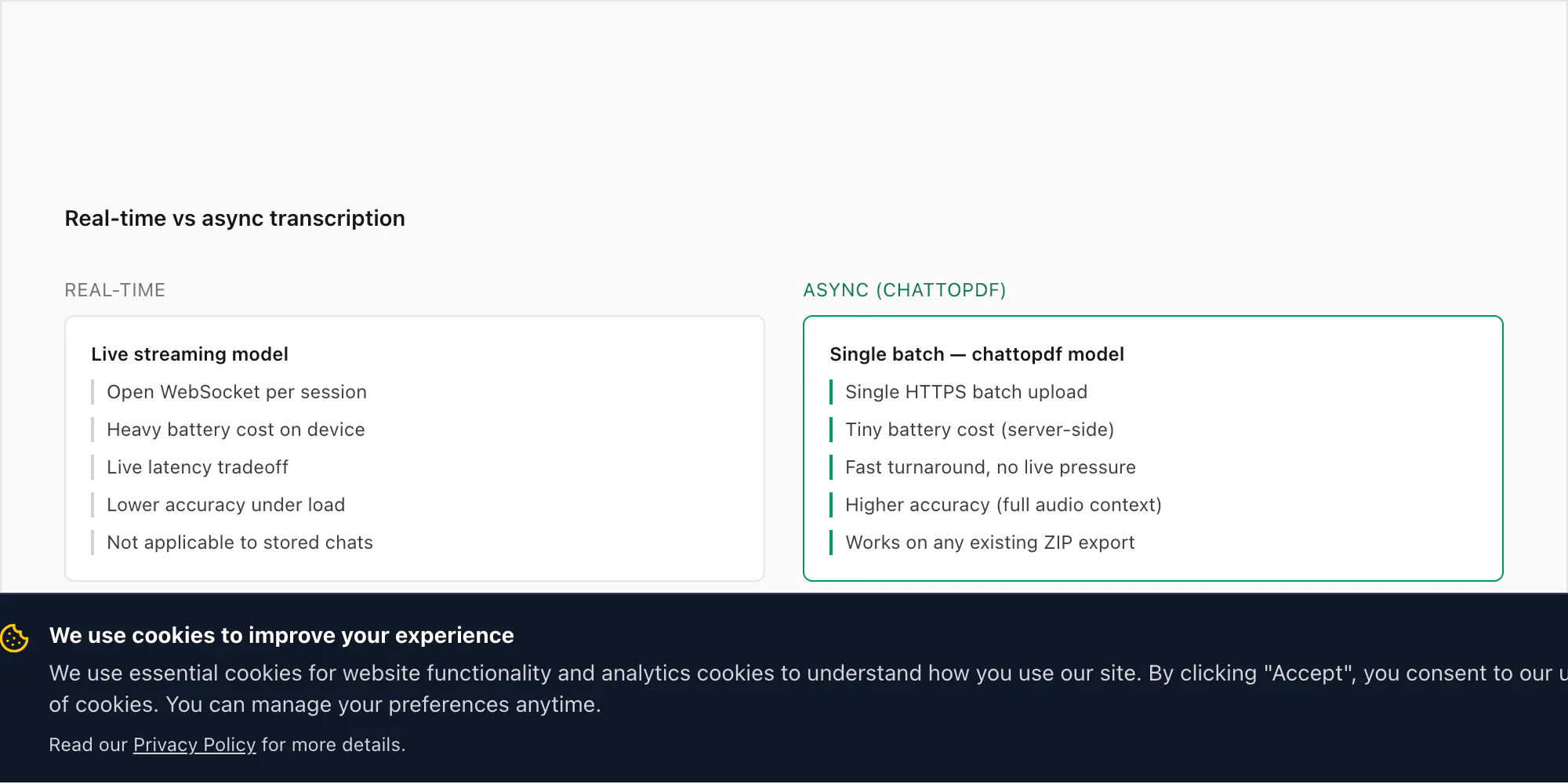
Das kommt oft genug auf, dass es eine direkte Antwort verdient. Menschen fragen, warum ChatToPDF keine Sprachnachrichten beim Eintreffen abhört – jede einzeln transkribiert, sobald sie gesendet wird – statt einen ZIP-Export nachträglich zu erfordern.
Die kurze Version: WhatsApp gibt Entwicklern keinen Zugang zu eingehenden Nachrichten oder Audio in Echtzeit. Es gibt keinen offiziellen WhatsApp Business API-Endpunkt, der Sprachnachrichten beim Eintreffen offenlegt. Der einzige unterstützte Drittanbieter-Zugangspfad führt über den Export-Chat-Mechanismus, der eine Momentaufnahme des Gesprächsverlaufs zu einem bestimmten Zeitpunkt ist. Echtzeit-Transkription auf WhatsApp aufzubauen würde erfordern, den lokalen Speicher der App auf dem Gerät abzufangen, was sowohl technisch fragil als auch außerhalb der Plattformrichtlinien von WhatsApp ist.
Aber es gibt einen praktischeren Grund, warum ich nicht versucht habe, diese Einschränkung zu umgehen. Der Anwendungsfall für die Transkription von WhatsApp Audio ist fast ausnahmslos retrospektiv. Jemand empfängt dreißig Sprachnachrichten im Verlauf eines Streits und möchte ein lesbares Protokoll. Ein Geschäftsteam nutzt Sprachnachrichten für Projektaktualisierungen und braucht sie durchsuchbar. Eine Familie sendet jahrelang Sprachnachrichten und möchte sie vor einem Handyupgrade archivieren. Keine dieser Situationen beinhaltet eine "jetzt sofort beim Eintreffen"-Anforderung. Es sind alles "ich habe einen Satz von Aufnahmen, die ich konvertieren muss"-Situationen.
Asynchrone Stapelverarbeitung ist auch genauer. Echtzeit-Spracherkennung arbeitet unter Latenzeinschränkungen, die das Modell zu schnellerer (und weniger genauer) Inferenz treiben. Deepgrams Stapelmodus läuft auf der vollständigen Audiodatei, was dem Modell erlaubt, zukünftigen Kontext zu verwenden – was nach einem Wort kam – um mehrdeutige Phoneme aufzulösen. Bei einer 30-Sekunden-Sprachnachricht kann der Unterschied in der Wortfehlerrate zwischen Echtzeit- und Stapelverarbeitungs-Modus 2–4 Prozentpunkte betragen. Das ist auf der Genauigkeitsskala bedeutsam.
Es gibt auch die Akku- und Netzwerkfrage. Eine offene WebSocket-Verbindung zu betreiben, die Audio-Fragmente in Echtzeit an eine Inferenz-API streamt, würde den Telefonakku bei einem langen Gespräch merklich entleeren. Es würde eine aktive Internetverbindung für jede empfangene Sprachnachricht erfordern, nicht nur wenn man konvertieren möchte. Und es würde einen kontinuierlichen Datenfluss der Gespräche zu einem Drittanbieter-Server schaffen – was ich Nutzern nicht zumuten möchte.
Das Export-und-Upload-Modell ist in der Uhrzeit langsamer – man muss warten, bis man bereit ist zu konvertieren, dann den Export durchführen, dann hochladen. Aber für die tatsächlichen Anwendungsfälle, die Menschen haben, ist das in Ordnung. Niemand versucht, eine Sprachnachricht zu transkribieren, die er vor drei Sekunden erhalten hat, für ein Echtzeit-Dokument. Sie konvertieren einen Chat, den sie behalten wollen.
Datenschutz: wo das Audio landet und wo nicht
Das ist der Teil, bei dem ich spezifisch sein möchte, weil die Natur der Sprachnachrichten – Audioaufnahmen echter Gespräche – bedeutet, dass die Datenschutzrisiken höher sind als bei reinen Textnachrichten.
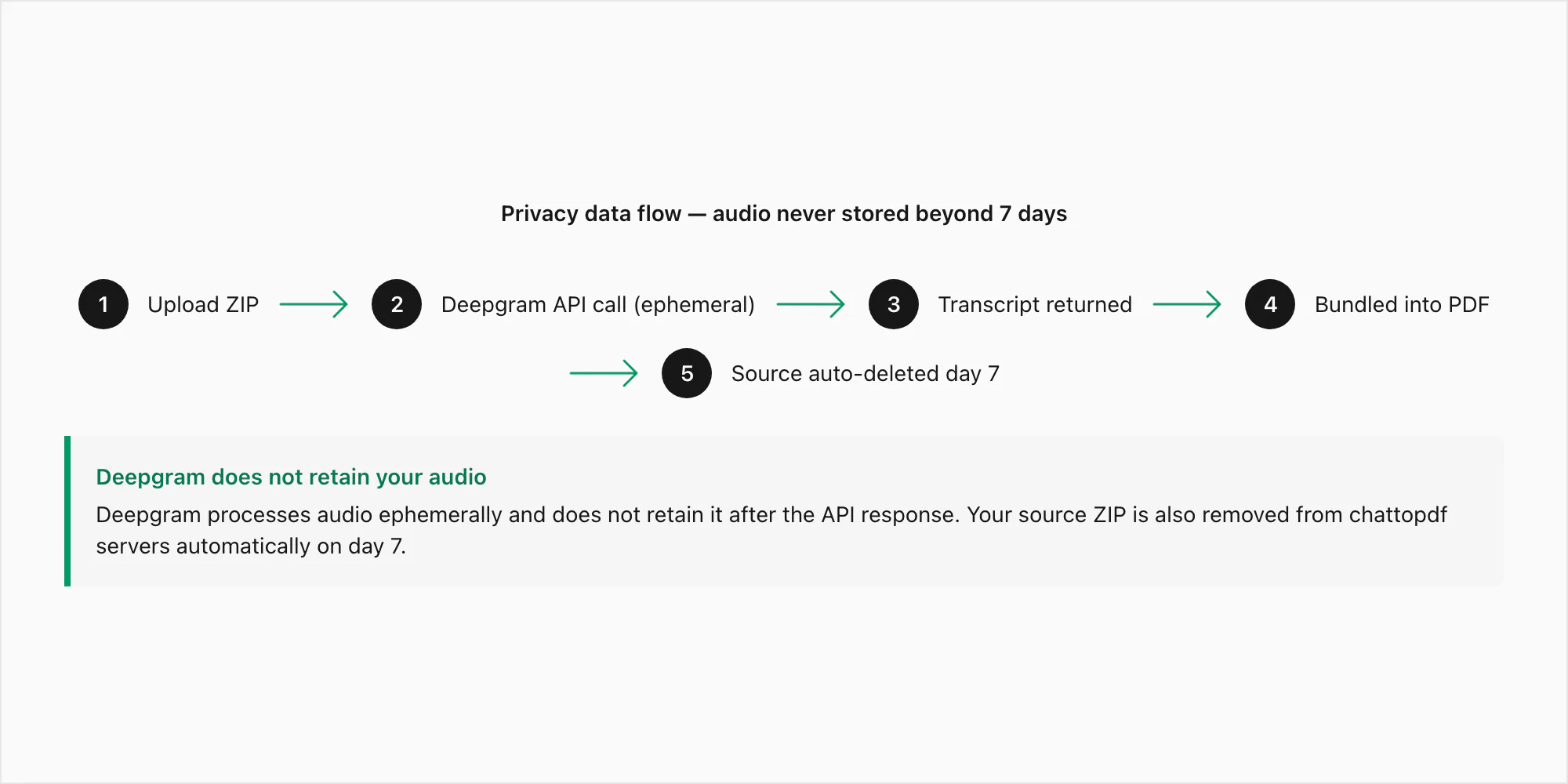
Hier ist der genaue Datenpfad für eine Sprachnachricht, die über die $49 Premium+Voice pro Chat-Konvertierung übermittelt wird:
Schritt 1 – Upload. Die ZIP-Datei wird vom Browser über HTTPS (TLS 1.3) an ChatToPDFs Server übertragen. Die Verbindung ist während der Übertragung verschlüsselt. Das ZIP landet in einem temporären Verarbeitungsverzeichnis, nicht in dauerhaftem Speicher, während die Extraktion läuft.
Schritt 2 – Extraktion. Die .opus-Dateien werden aus dem ZIP extrahiert. Jede Datei wird ihrer _chat.txt-Referenz nach Dateinamenmuster zugeordnet. An diesem Punkt existieren die Audiodateien nur auf ChatToPDFs Verarbeitungsserver.
Schritt 3 – Deepgram API-Aufruf. Jede .opus-Datei wird über einen authentifizierten HTTPS-Aufruf an Deepgrams Inferenz-API übermittelt. Das ist der einzige Moment, in dem Audio-Bytes ChatToPDFs eigene Infrastruktur verlassen. Deepgrams Datenschutzrichtlinie für API-Übermittlungen gibt an, dass über die API übermittelte Audio ephemer verarbeitet wird – sie wird zur Erzeugung des Transkripts verwendet und dann verworfen. Deepgram behält API-übermittelte Audio nicht und verwendet sie nicht für Modelltraining. Was zurückkommt, ist der Transkripttext.
Schritt 4 – Speicherung. Das Transkript wird in das PDF eingebunden und verschlüsselt im Ruhezustand (AES-256) in AWS S3 gespeichert. Das Quell-ZIP, einschließlich der .opus-Dateien, wird ebenfalls sieben Tage verschlüsselt gespeichert.
Schritt 5 – Zustellung. Der PDF-Download-Link erscheint auf dem Bildschirm und in der E-Mail. Der Link ist an die Job-ID gebunden. Er ist nicht erratbar und wird nirgendwo indiziert.
Schritt 6 – Automatische Löschung. Sieben Tage nach der Job-Erstellung werden das Quell-ZIP und das Ausgabe-PDF automatisch aus dem Speicher gelöscht. Das ist ein geplanter Löschjob, kein manueller Prozess. Es gibt keine Ausnahmen und keine Verlängerungen.
Wo das Audio nicht hingeht: Es geht nicht an eine Analytics-Plattform. Es wird nicht für das Training von ChatToPDF-Modellen verwendet (ChatToPDF trainiert keine Modelle). Der Textinhalt der Sprachnachrichten ist für ChatToPDF-Mitarbeiter nicht sichtbar – die Verarbeitung ist vollständig automatisiert. Kein Drittanbieter erhält den Text der Chat-Nachrichten.
Die einzige potenzielle Lücke in dieser Beschreibung ist der Deepgram-Schritt. Was auf ChatToPDFs Servern passiert, kann ich vollständig kontrollieren. Ich kann keine Angaben zu Deepgrams internen Prozessen über das machen, was ihre öffentliche Datenschutzrichtlinie sagt. Wenn die Sprachnachrichten rechtlich privilegierte oder tatsächlich klassifizierte Informationen enthalten, würde ich empfehlen, dass das Rechtsteam Deepgrams Unternehmens-Datenverarbeitungsbedingungen prüft, bevor hochgeladen wird. Für die große Mehrheit der Anwendungsfälle – persönliche Gespräche, Geschäftsteam-Chats, Familien-Sprachnachrichten-Archive – ist die Standardpipeline angemessen.
Sonderfälle: Hintergrundlärm, mehrere Sprecher, Stimmveränderungseffekte
Echte WhatsApp Sprachnachrichten werden nicht in schallisolierten Studios aufgenommen. Sie werden in Autos, Küchen, Straßengesprächen und belebten Cafés aufgenommen. Hier ist, wie jedes dieser Szenarien die Transkriptionsgenauigkeit beeinflusst, und was ChatToPDF tut, wenn die Genauigkeit auf ein inakzeptables Niveau sinkt.
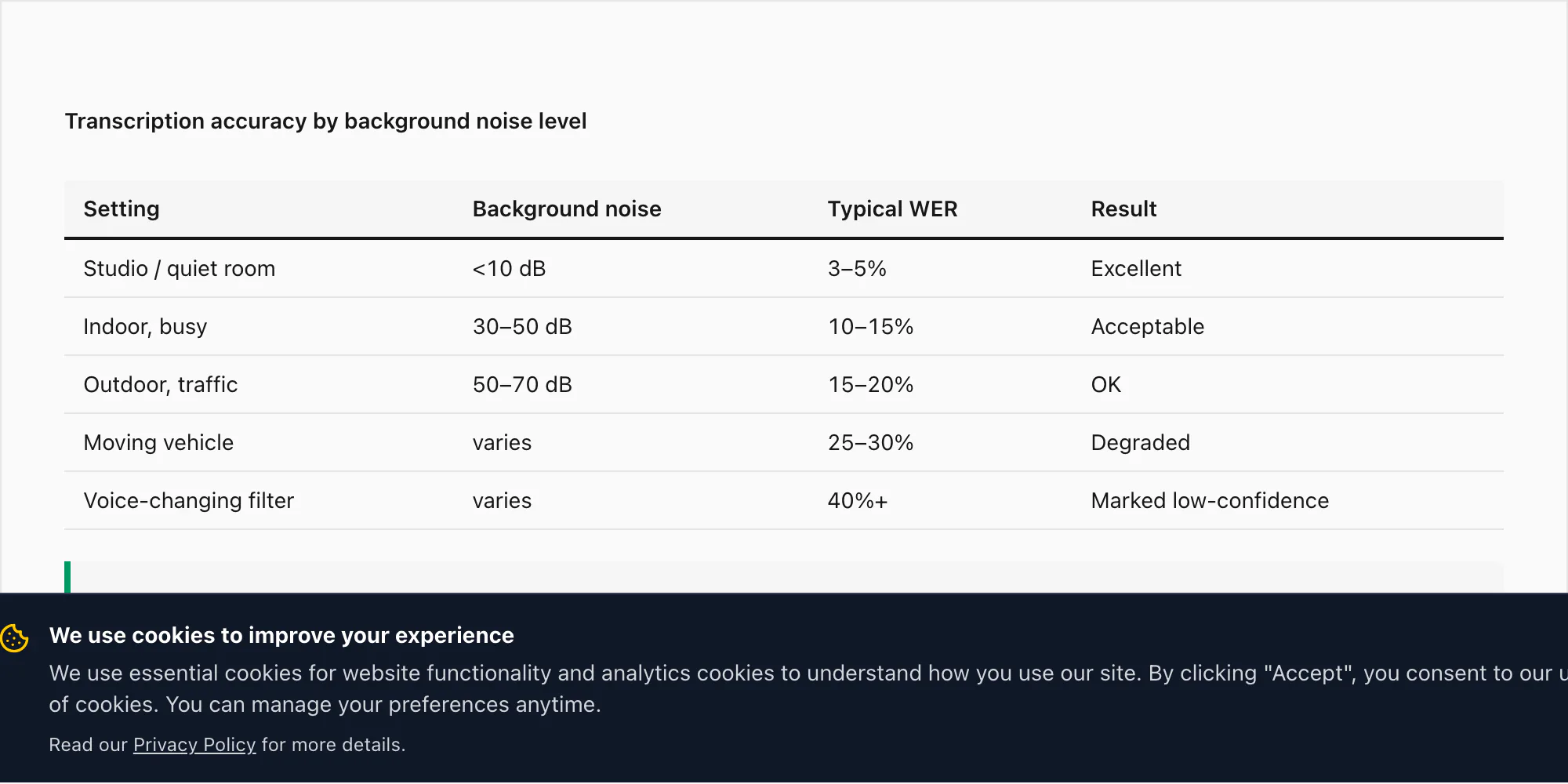
Hintergrundlärm nach Umgebung.
Eine Sprachnachricht, die in einer ruhigen Innenumgebung aufgenommen wurde – ein Büro, ein Schlafzimmer, ein stilles Zimmer – erzielt die Genauigkeitsraten, die oben im Sprachabschnitt angegeben wurden: 3–5% WFR bei $49 Premium+Voice pro Chat für die 17 hochgenauen Sprachen.
Eine Sprachnachricht aus einer belebten Innenumgebung (ein Restaurant, ein Markt, ein belebtes Büro) kann die WFR auf 10–15% bei $49 Premium+Voice pro Chat steigen sehen. Deepgrams Nova-3 wendet während der Inferenz Rauschunterdrückung an, was hilft, aber den Effekt konkurrierender Audio nicht eliminiert.
Eine Außenaufnahme – Straßenlärm, Wind, Verkehr – kann die WFR für dieselbe Stufe auf 15–20% treiben.
Eine Sprachnachricht, die während einer Autofahrt mit Fahrgeräuschen und Motorgeräusch aufgenommen wurde, ist das herausforderndste Einzelszenario, das ich getestet habe. Die WFR auf diesen kann selbst mit Nova-3 25–30% erreichen. Das ist keine Einschränkung der Transkriptions-Engine – es spiegelt die Physik von Audio wider, das mit einem Telefonmikrofon bei 16 kHz in einer lauten Umgebung aufgenommen wurde. Die Audioqualität, die eingeht, bestimmt die Transkriptqualität, die herauskommt.
Mehrere Sprecher innerhalb einer einzelnen Sprachnachricht.
Wie zuvor erklärt, gehört jede WhatsApp Sprachnachricht einem Sender – der Person, die die Push-to-Talk-Schaltfläche gedrückt hat. ChatToPDF ordnet das Transkript diesem Sender zu. Wenn der Sender jedoch aufnimmt, während eine andere Person hörbar im Hintergrund spricht (ein Telefongespräch, das der Sender führt, ein im Hintergrund laufender Fernseher, der Stimmen enthält, eine andere Person im selben Zimmer, die laut spricht), transkribiert Deepgram auch die Hintergrundstimme – es verwirft keine Nicht-Primär-Sprecher stillschweigend. Das Transkript wird beide Stimmen verweben, dem WhatsApp-Sender zugeordnet. Das kann verwirrende Ausgaben erzeugen, wenn die Hintergrundsprache verständlich genug ist, um transkribiert zu werden.
ChatToPDF kann derzeit nicht den Primärsprecher isolieren und Hintergrundstimmen innerhalb eines einzelnen .opus-Clips verwerfen. Sprecher-Diarisierung – die Identifikation, welche Audio-Segmente von welcher Person in derselben Audiodatei stammten – ist eine Funktion, die für eine zukünftige Stufe evaluiert wird, aber zusätzliche Infrastruktur erfordert und nicht in der aktuellen Version enthalten ist.
Stimmveränderungseffekte.
Einige WhatsApp-Nutzer senden Sprachnachrichten mit angewandten Audioeffekten – dem Deep-Voice-Filter, der in WhatsApp selbst verfügbar ist (Android), Snapchat-artige Stimmveränderungen vor dem Teilen, oder nur Audio, das vor dem Senden tonhöhenverschoben oder gehallt wurde. Deepgrams Modell ist auf natürliche Sprache trainiert. Modifiziertes Audio kann die WFR in extremen Fällen über 40% treiben – eine Sprachnachricht, die durch einen tiefen Bass-Filter gesendet wurde, um jemanden wie einen Roboter klingen zu lassen, wird meist nicht transkribieren.
Für Clips, bei denen die Konfidenz unter den in der Pipeline festgelegten Schwellenwert fällt – derzeit definiert als durchschnittlicher Wort-Konfidenzwert unter 0,6 über den Clip – markiert ChatToPDF das Transkript im PDF als [Transkription mit niedriger Konfidenz – Audioqualität unzureichend] statt einen Textblock auszugeben, der als autoritativ angesehen werden könnte. Dieses Zeichen neben der Position der Sprachnachricht im Gespräch ist besser als ein unsicheres Ergebnis zurückzugeben, das 40% falsch sein könnte.
FAQ
Welches Dateiformat verwenden WhatsApp Sprachnachrichten, und verarbeitet ChatToPDF es?
WhatsApp zeichnet Sprachnachrichten mit dem Opus-Audio-Codec bei 16-kHz-Mono auf, gespeichert als .opus-Dateien. ChatToPDF extrahiert .opus-Dateien direkt aus dem WhatsApp-Export-ZIP und übermittelt sie in ihrem nativen Format an Deepgrams Inferenz-API – kein Rekodierungsschritt erforderlich. Sowohl iPhone- als auch Android-Exporte produzieren .opus-Dateien, sodass die Formatverarbeitung auf beiden Plattformen gleich ist.
Wie genau ist die WhatsApp Audio-Transkription?
Die Genauigkeit hängt von der Stufe und der Audioqualität ab. Die $49 Premium+Voice pro Chat-Konvertierung verwendet Deepgram Nova-3, das bei klarer, rauschfreier Audio in den 17 unterstützten hochgenauen Sprachen ungefähr 3–5% Wortfehlerrate erreicht. Die $99 Power User pro Chat-Konvertierung verwendet dasselbe Nova-3-Modell ohne Audio-Obergrenze und mit Prioritätswarteschlangen-Verarbeitung. Die $29 Premium pro Chat-Konvertierung transkribiert nicht – sie erhält Sprachnachrichten als Platzhalterreferenzen im PDF. Hintergrundlärm, Akzente und Code-Switching zwischen Sprachen beeinflussen alle die Genauigkeit bei den transkribierenden Stufen. Clips mit niedriger Konfidenz (unter einem durchschnittlichen Wort-Konfidenzwert von 0,6) werden als [Transkription mit niedriger Konfidenz] im PDF markiert.
Transkribiert ChatToPDF Sprachnachrichten in anderen Sprachen als Englisch?
Ja. Die $49 Premium+Voice pro Chat-Konvertierung und $99 Power User pro Chat-Konvertierung unterstützen 17 hochgenaue Sprachen: Englisch, Spanisch, Portugiesisch, Französisch, Deutsch, Italienisch, Arabisch, Hindi, Indonesisch, Türkisch, Russisch, Niederländisch, Japanisch, Koreanisch, Chinesisch, Vietnamesisch und Thai. Beide Stufen verwenden Deepgram Nova-3 für diese Sprachen und erkennen 30+ weitere Sprachen mit einem breiteren Genauigkeitsbereich. Die Sprache wird automatisch erkannt – es muss nichts vor dem Hochladen angegeben werden. Die $29 Premium pro Chat-Konvertierung transkribiert keine Sprachnachrichten – sie erhält sie als Platzhalterreferenzen im PDF.
Muss ich beim WhatsApp-Export etwas anders machen, wenn ich Sprachtranskripte möchte?
Ja – ein kritischer Schritt. Beim Exportieren des Chats aus WhatsApp "Mit Medien" statt "Ohne Medien" wählen. Sprachnachrichten (.opus-Dateien) sind nur im Export enthalten, wenn "Mit Medien" ausgewählt wird. Bei "Ohne Medien"-Export enthält _chat.txt zwar Referenzen wie <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus>, aber keine tatsächlichen Audiodateien. ChatToPDF kann keine Sprachnachricht transkribieren, die es nicht hat. Den WhatsApp chat export Leitfaden für den vollständigen Schritt-für-Schritt-Exportprozess lesen.
Erscheinen die Sprachtranskripte an der richtigen Stelle im PDF?
Ja. ChatToPDF liest das Nachrichtenprotokoll in _chat.txt, um die Gesprächsstruktur zu verstehen, ordnet jede .opus-Referenz der entsprechenden Audiodatei per Dateiname zu und fügt das Transkript genau an der Position im Gespräch ein, wo die Sprachnachricht gesendet wurde. Der Sendername aus den WhatsApp-Metadaten und der ursprüngliche Zeitstempel erscheinen beide neben dem Transkript. Die Ausgabe ist ein einziges Dokument, in dem Textnachrichten und Sprachtranskripte in der richtigen chronologischen Reihenfolge abwechseln.
Was passiert mit meinen Audiodateien nach Abschluss der Transkription?
Die Audiodateien werden sieben Tage nach der Job-Erstellung verschlüsselt im Ruhezustand (AES-256) auf ChatToPDFs Servern gespeichert und dann automatisch gelöscht. Der einzige Drittanbieter-Dienst, der die Audio-Bytes erhält, ist Deepgram, und nur während des Transkriptionsschritts – Deepgram verarbeitet die über die API übermittelte Audio ephemer und behält sie nicht. Kein Mensch hört die Aufnahmen. Die Transkripte selbst werden zusammen mit den Quelldateien nach sieben Tagen gelöscht. Für mehr Details zum vollständigen Datenfluss den WhatsApp to PDF Datenschutzabschnitt lesen.
Kann ChatToPDF zwei verschiedene Sprecher in derselben Sprachnachricht unterscheiden?
Derzeit nicht. Jede WhatsApp Sprachnachricht wird der Person zugeordnet, die sie gesendet hat, anhand der Senderinformation aus _chat.txt. Innerhalb einer einzelnen Sprachnachricht, wenn sowohl der Sender als auch eine andere Person sprechen (zum Beispiel führt der Sender ein Telefongespräch beim Aufnehmen), werden beide Stimmen transkribiert, aber dem WhatsApp-Sender zugeordnet. ChatToPDF führt derzeit keine Sprecher-Diarisierung innerhalb einzelner Audioclips durch. Bei Sprachnachrichten, wo Hintergrundstimmen hörbar und verständlich sind, können verschachtelte Sprache im Transkript erscheinen.
Key takeaways
- Um WhatsApp Audio zu transkribieren, den Chat mit ausgewähltem "Mit Medien" exportieren – die
.opus-Sprachnachrichtdateien müssen im ZIP vorhanden sein - Die $29 Premium pro Chat-Konvertierung transkribiert nicht – sie erhält Sprachnachrichten als Platzhalterreferenzen; die $49 Premium+Voice pro Chat-Konvertierung führt Deepgram Nova-3 aus (3–5% WFR bei klarer Audio, 17 hochgenaue Sprachen, bis zu 8 Stunden Audio); die $99 Power User pro Chat-Konvertierung ist dasselbe Modell ohne Limit und mit Prioritätswarteschlange
- Jedes Transkript wird an der exakten Position im Gespräch mit dem WhatsApp-Sendernamen und dem ursprünglichen Zeitstempel eingefügt
- Code-Switching-Sprachen wie Hinglish benötigen die $49 Premium+Voice pro Chat-Konvertierung oder höher – Nova-3 schließt den größten Teil der Lücke, die ältere STT-Engines bei mitten-im-Satz englischen Einfügungen in Hindi-Sprachnachrichten hinterließen
- Hintergrundlärm ist die größte Genauigkeitsvariable: Studiobedingungen erzielen 3–5% WFR; Außen- oder Fahrzeugaufnahmen können selbst auf Nova-3 20–30% WFR erreichen
- Audio, die für die Transkription an Deepgram übermittelt wird, wird ephemer verarbeitet – sie wird nicht behalten und nicht für Training verwendet; Quelldateien werden nach 7 Tagen automatisch von ChatToPDF-Servern gelöscht
- Clips, bei denen der durchschnittliche Wort-Konfidenzwert unter 0,6 liegt, werden im PDF als
[Transkription mit niedriger Konfidenz]markiert, statt stillschweigend ein potenziell falsches Transkript zurückzugeben
Für den vollständigen Chat-zu-PDF-Workflow – einschließlich des Exports auf iPhone und Android, was das ZIP enthält und wie alle fünf Stufen für Nicht-Sprach-Konvertierungen vergleichen – den WhatsApp to PDF Leitfaden lesen. Wenn auf Android ist und der Export vor dem Hochladen auf ein anderes Gerät übertragen werden muss, deckt der WhatsApp Android-zu-iPhone-Transferleitfaden diesen Prozess ab.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).