To transcribe WhatsApp audio, export your chat with media included, upload the ZIP to ChatToPDF, and select the $49 Premium+Voice tier. Every voice note becomes searchable text placed inline in conversation order — with the original sender's name and timestamp — using Deepgram Nova-3 across 17 high-accuracy languages including English, Spanish, Hindi, and Arabic.
90-second tutorial · drop the WhatsApp zip, get a searchable PDF with every voice note transcribed.
Same flow, focused on the audio-to-text use case — every voice message rendered inline as readable text.
What "transcribe WhatsApp audio" actually means (and why it's harder than it sounds)
People use the phrase "transcribe WhatsApp audio" to mean at least three different things. Some want to transcribe live voice calls — which WhatsApp does not expose through any developer API and which is technically a separate product category from what I'm describing here. Some want to convert audio files they've saved from WhatsApp to text, treating the .opus file as a standalone input. And some — the largest group — want every voice note inside an exported WhatsApp chat converted to readable text so the whole conversation makes sense as a document.
ChatToPDF is built for that third use case. The problem it solves is specific: you export a WhatsApp chat that contains both text messages and voice notes, and what you get back from WhatsApp is a ZIP containing a _chat.txt and a folder of media files. The _chat.txt has lines like <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> where the voice note belongs. Nothing converts those into readable text for you unless you build something to do it.
Here's the part nobody tells you: even when people find a transcription tool, they often run into a structural problem. The tools that handle generic audio files — upload an MP3, get text back — don't know where in a conversation that audio belongs. They transcribe the file but lose the context. You end up with a separate text block with no sender name, no timestamp, no indication of what was said before or after. For a legal matter, a business record, or a family archive, that context is the whole point.
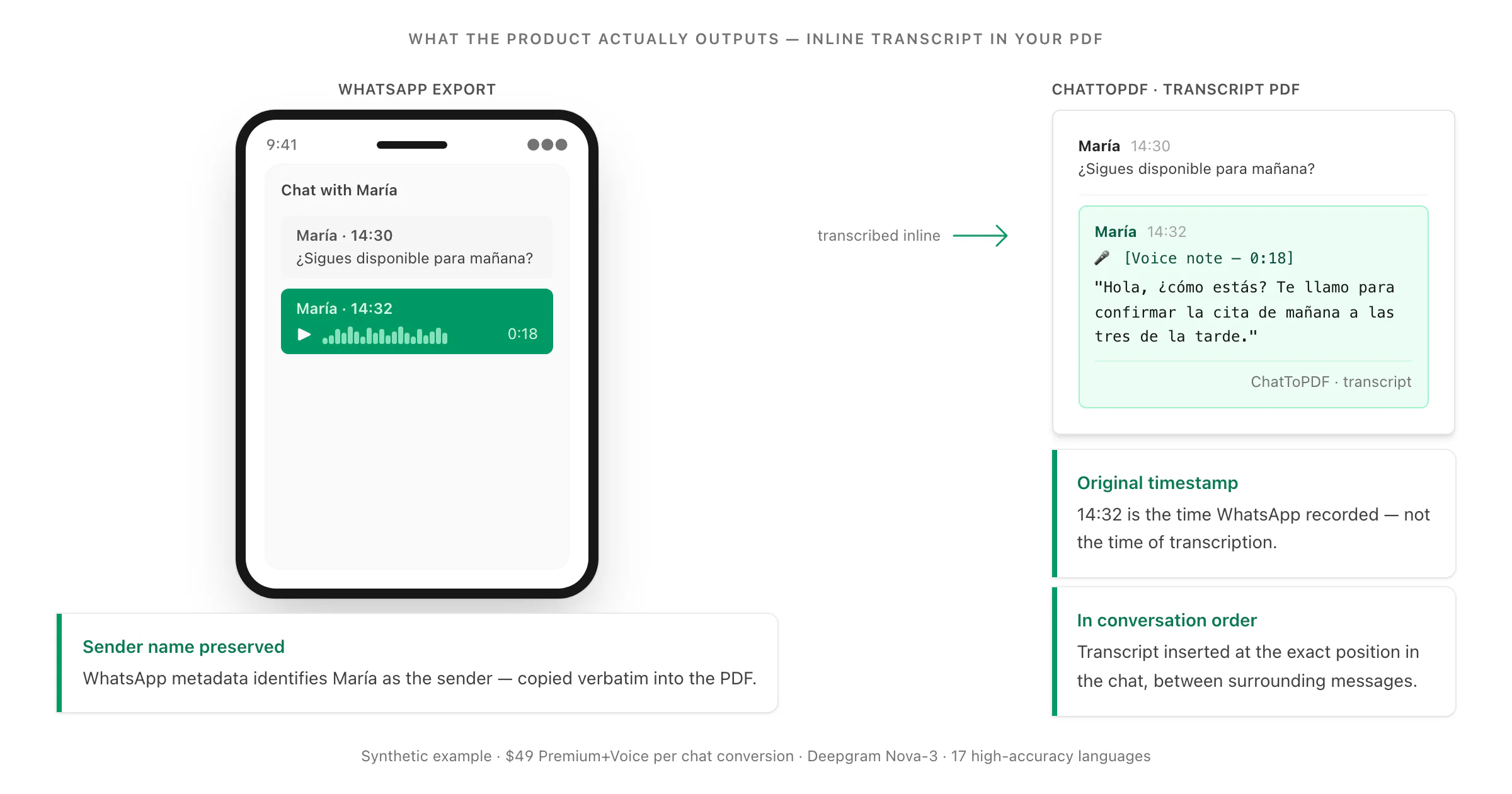
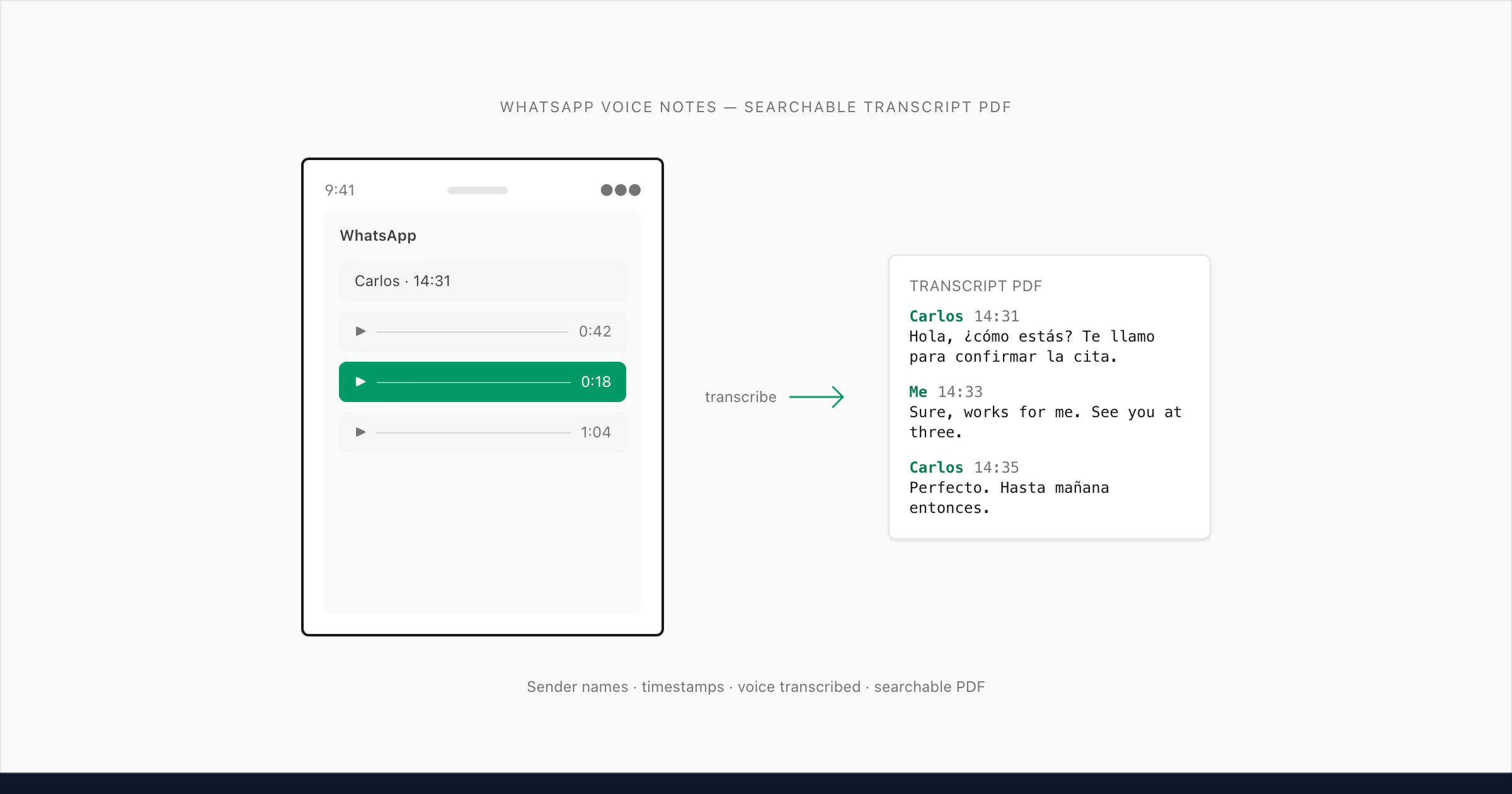
What I built does the following: it reads the _chat.txt to understand the conversation structure, matches each .opus reference to the correct audio file in the ZIP, transcribes the audio, and inserts the transcript back at exactly the right position in the conversation — with the sender's name and the original timestamp preserved. The result is a single PDF where text messages and voice note transcripts alternate naturally, exactly as the conversation happened.
That's the problem this guide is about.
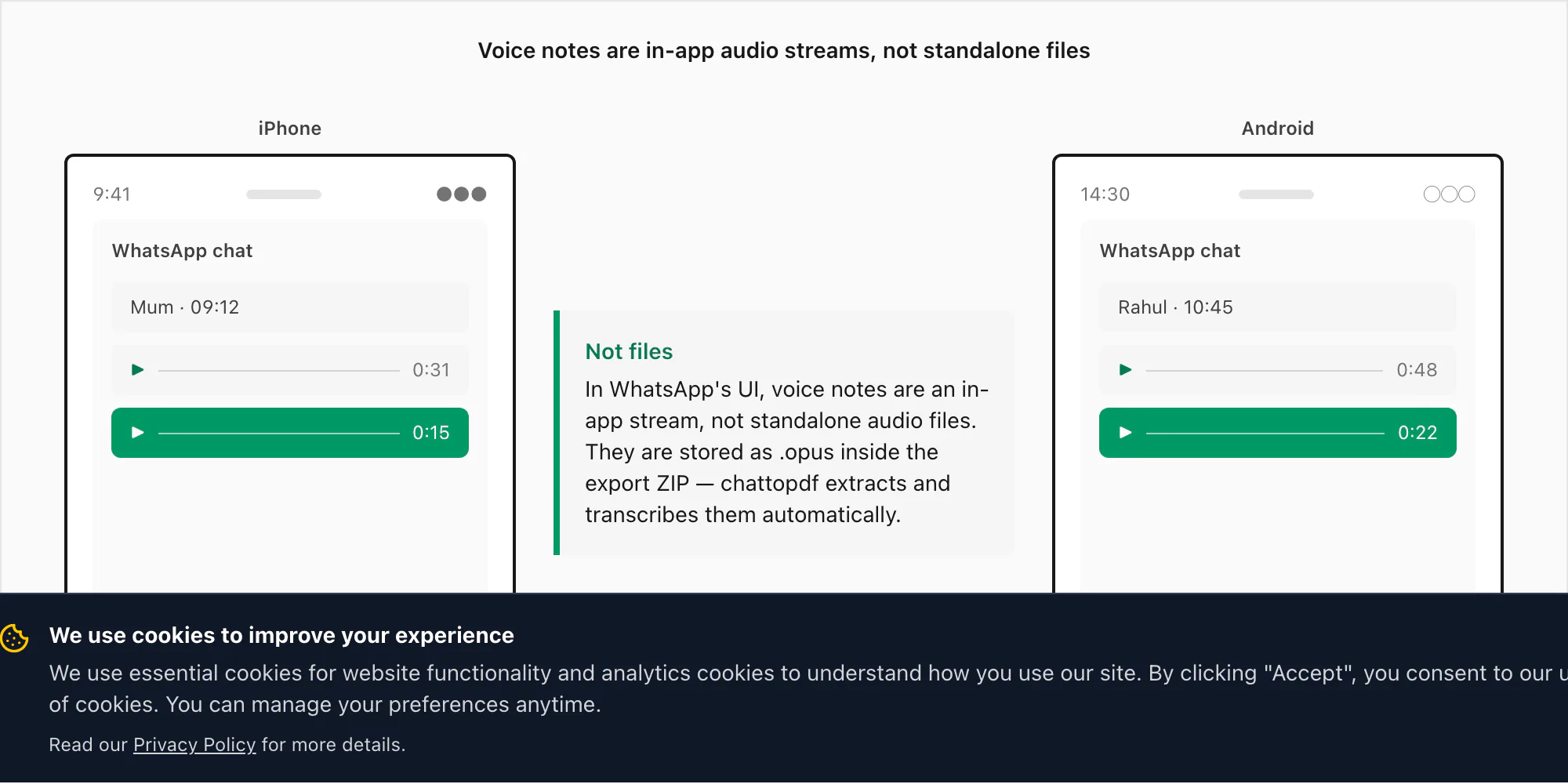
Voice notes are not files — they're an in-app stream
Voice notes are not a fringe feature. WhatsApp users send roughly 7 billion voice messages a day (Backlinko) across a base of about 3.3 billion monthly active users (DemandSage) — which WhatsApp has said makes it the largest voice-messaging platform in the world. (More in the full WhatsApp statistics breakdown.)
"WhatsApp users send over 7 billion voice messages a day." — WhatsApp
That volume is exactly why "I'll listen later" stops working once a chat has dozens of them. But getting those notes out as searchable text is harder than it looks, because of how WhatsApp stores them.
WhatsApp voice notes look like audio files inside the app — a waveform bar, a duration, a play button — but they aren't stored the way most people expect. When you record a voice note in WhatsApp by holding the microphone button, WhatsApp encodes the audio using the Opus codec and saves it as a .opus file in a private directory on your device. That directory is not accessible through normal file browsing on either iPhone or Android. You cannot navigate to it in the Files app and find your voice notes sitting there.
The only way to extract those .opus files is through WhatsApp's own Export Chat menu, with "Including Media" selected. When you export that way, WhatsApp packages the _chat.txt message log alongside the media folder — and that's where the .opus files appear. On iOS, they end up inside the ZIP. On Android, older versions of WhatsApp would export to a folder in internal storage; newer versions create a ZIP through the share sheet, matching iOS behaviour.
The Opus codec itself is worth understanding briefly because it explains why accuracy can vary. Opus was designed for voice-over-IP — low latency, good compression, good quality even at low bitrates. WhatsApp uses 16 kHz mono audio at around 16 kbps. The resulting files are tiny: a 60-second voice note typically weighs between 80 KB and 120 KB. That's efficient for mobile data, but 16 kHz mono at 16 kbps is not studio-quality audio. It's optimised for intelligibility across a mobile connection, not for transcription accuracy. Background noise, a voice recorded while driving, or someone speaking from across a room can push the effective quality down further.
- Opus codec
The audio codec WhatsApp uses to encode voice notes: 16 kHz sample rate, mono channel, approximately 16 kbps bitrate. Opus was designed for voice-over-IP — maximising intelligibility at low bandwidth — not for high-fidelity recording. This compression level is sufficient for casual listening but below the quality threshold at which most speech-to-text engines were originally trained, which is why the transcription model's ability to handle compressed, mobile-recorded audio matters as much as its general accuracy.
This is why the transcription model matters. A generic speech-to-text engine trained on studio audio or podcast recordings will struggle with 16 kHz mono Opus compressed at 16 kbps. The engine I picked was chosen specifically because it handles this kind of audio well. More on that in the next section.
One more structural point: each WhatsApp voice note is a single-sender recording. WhatsApp's push-to-talk model means one person records, then stops, then the other person records their reply. This is actually a transcription advantage — unlike a recorded phone call where two voices overlap on the same audio track, each .opus file in a WhatsApp export belongs to exactly one sender. ChatToPDF uses the metadata from _chat.txt to attribute each transcript to the correct person, which is how you get a conversation that reads clearly even when both people swap back and forth in voice notes.
The transcription engine I picked, and why
I evaluated several transcription APIs before settling on Deepgram as the engine behind ChatToPDF's voice transcription. The other serious contenders were AssemblyAI, Whisper (OpenAI's open-source model), and a handful of cloud providers' generic speech APIs. Here's the honest reasoning behind my choice.
Whisper is impressive for a free model, but I ran accuracy tests on a set of real WhatsApp .opus files across English, Spanish, Hindi, and Arabic, and it showed consistent weaknesses on code-switching (a voice note that mixes two languages mid-sentence) and on non-US English accents. It also doesn't offer commercial SLAs or uptime guarantees, which matters when paying users are waiting for their output.
AssemblyAI is genuinely good and I used it in an early prototype. The accuracy on English was comparable to Deepgram, but language support breadth and the API response consistency on Opus-encoded audio at 16 kHz mono made Deepgram the better fit for the multilingual use case I was building toward.
- Word error rate (WER)
The standard metric for measuring transcription accuracy: the percentage of words in the output that are wrong relative to a reference transcript, calculated as (substitutions + insertions + deletions) ÷ total reference words × 100. A WER of 5% means roughly 1 word in 20 is incorrect. Lower is better. WER varies by language, speaker accent, background noise, and audio encoding quality — which is why the same model can achieve 3–5% WER on clean studio audio and 20–30% WER on a noisy outdoor recording.
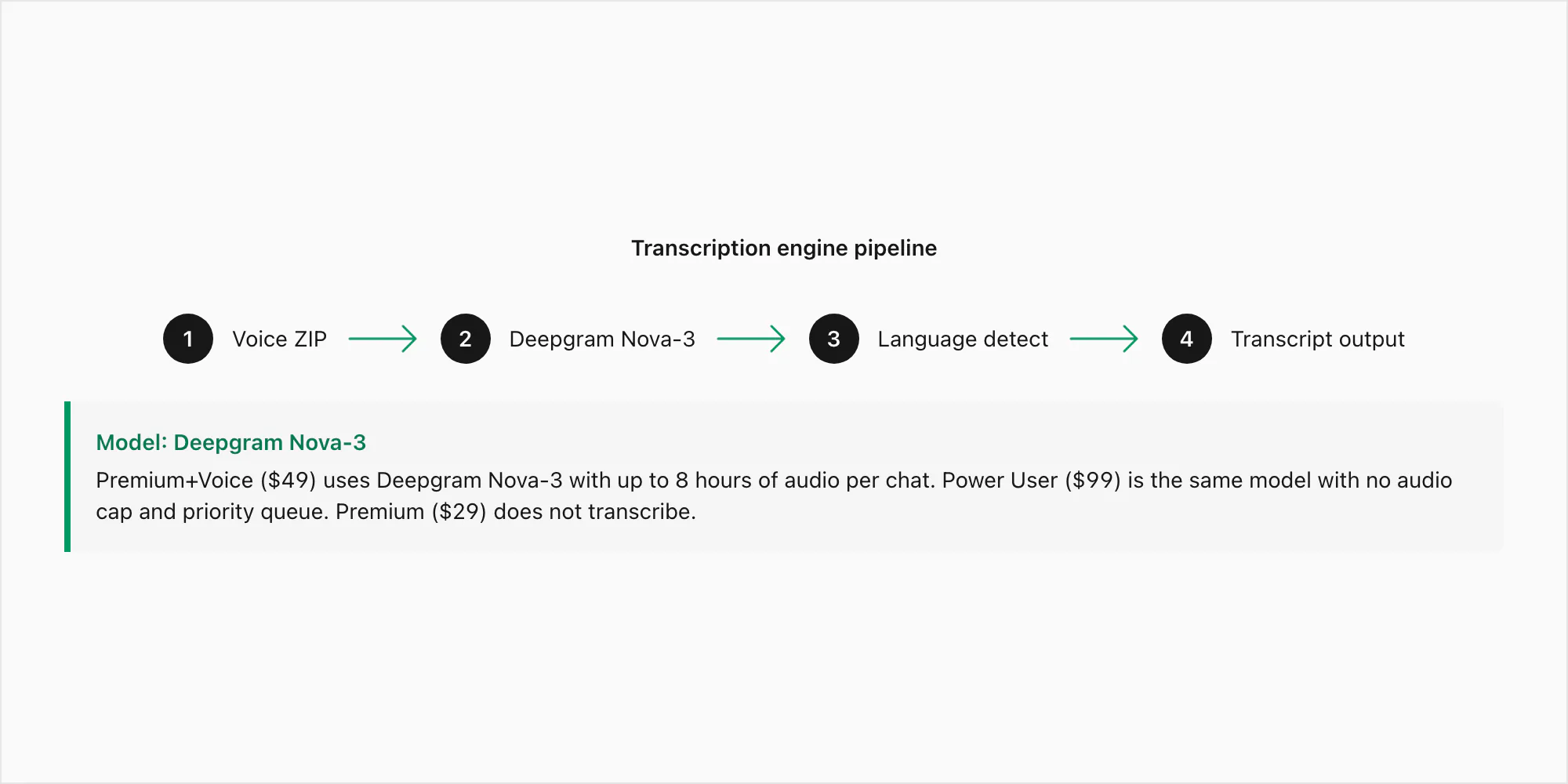
Deepgram Nova-3 is the current-generation model with a word error rate of approximately 3–5% on clean, noise-free English audio and 8–15% on noisier recordings. Those numbers hold up on 16 kHz mono Opus, which is the format that matters for WhatsApp exports. Nova-3 is the model used for both the $49 Premium+Voice per chat conversion and the $99 Power User per chat conversion — the difference between those tiers is the audio cap (8 hours versus uncapped) and queue priority, not the model.
Where Nova-3 visibly outperforms older speech-to-text engines is in three places: regional accents (South African English, Indian English, Brazilian Portuguese), technical vocabulary (names, addresses, product terms that a generic model would mishear), and code-switched audio where a speaker moves between languages inside a single voice note. Those are the specific failure modes that motivated the engine choice. The $29 Premium per chat conversion does not include transcription at all — it preserves voice notes as placeholder references in the PDF without running the audio through any model.
The pipeline works like this: your ZIP lands on ChatToPDF's server, the .opus files are extracted, each is submitted to Deepgram's API over an authenticated HTTPS call with language detection set to automatic, and the transcript returns — typically within two to five seconds per minute of audio. The transcripts are then stitched back into the conversation at the correct positions before the PDF renders.
One deliberate choice in the pipeline: I do not pre-process or re-encode the .opus audio before sending it to Deepgram. Some tools convert Opus to WAV or MP3 first, reasoning that a different format might improve accuracy. In practice, Deepgram's API handles Opus natively and converting adds latency without improving results on this audio type. The raw .opus file goes straight to the inference endpoint.
Accuracy on the 17 languages ChatToPDF supports today
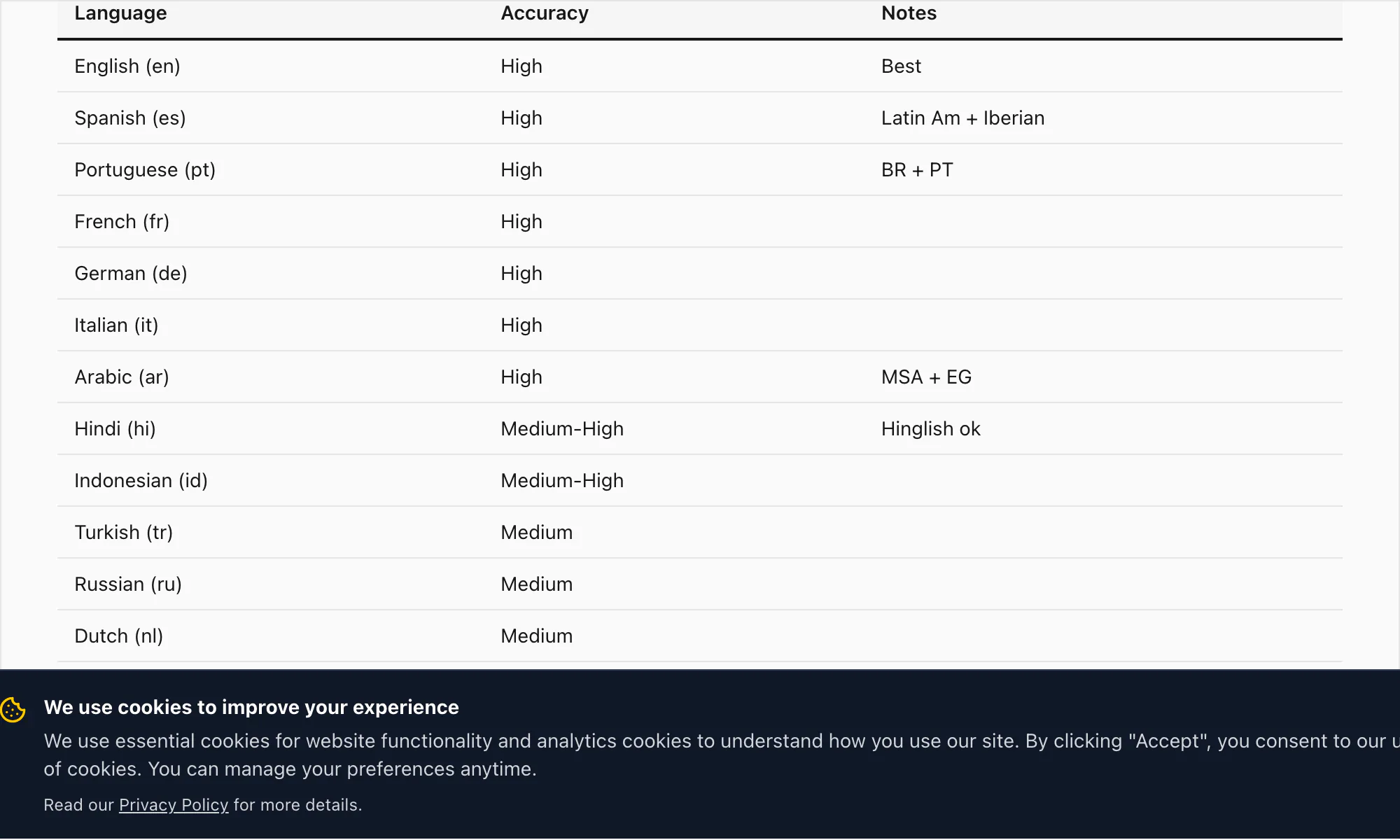
ChatToPDF's high-accuracy language tier covers 17 languages. These are the languages where I'm confident enough in the transcription quality to call it production-ready for documents, legal records, and business use:
English (en) — WER 3–5% on clean audio. Includes UK, US, Australian, South African, and Indian English variants. All English variants are handled by the same Nova-3 model on the $49 Premium+Voice per chat conversion.
Spanish (es) — WER 4–6% on $49 Premium+Voice per chat conversion. Handles Latin American and Castilian variants. Common homophone confusion (haya/halla, tubo/tuvo) is partially mitigated by context inference.
Portuguese (pt) — WER 4–7%. Covers Brazilian and European Portuguese. Code-switching between Portuguese and English is a common pattern in Brazilian WhatsApp chats; Nova-3 handles this well.
French (fr) — WER 4–6%. Standard and Canadian French.
German (de) — WER 4–6%. Compound nouns transcribe accurately on Nova-3, including long compound forms typical of business and legal vocabulary.
Italian (it) — WER 5–7%.
Arabic (ar) — WER 7–10%. Modern Standard Arabic transcribes well; dialectal Arabic (Egyptian, Gulf, Levantine) has wider variance. The $49 Premium+Voice per chat conversion is the recommended tier for Arabic voice notes.
Hindi (hi) — WER 6–9% on pure Hindi. Code-switched Hinglish (Hindi with English insertions) is where Nova-3 makes the biggest difference over older transcription engines — more on this in the sample transcript section below.
Indonesian (id) — WER 5–8%. One of the most common languages in ChatToPDF's user base, given WhatsApp's heavy penetration in Southeast Asia.
Turkish (tr) — WER 5–8%.
Russian (ru) — WER 5–8%.
Dutch (nl) — WER 4–6%.
Japanese (ja) — WER 7–10%. Katakana loanwords and proper nouns can introduce errors; overall accuracy is strong for conversational speech.
Korean (ko) — WER 6–9%.
Chinese (zh) — WER 7–10%. Mandarin. Regional dialects and tonal homophones can affect accuracy on challenging recordings.
Vietnamese (vi) — WER 7–10%.
Thai (th) — WER 8–12%. Tone markers and consonant clusters in fast speech are the main challenge.
Beyond these 17, Deepgram Nova-3 supports 30+ additional languages at a wider accuracy range. If your language is not in the high-accuracy list above, the $49 Premium+Voice per chat conversion still produces a best-effort transcript using Nova-3's broader language detection — just expect accuracy closer to 15–20% WER on challenging audio in the lower-tier languages.
Automatic language detection is on by default. ChatToPDF sends each .opus file to Deepgram without specifying a language, and Deepgram detects the dominant language in the first few seconds. This is accurate for single-language recordings. For heavy code-switching — a voice note that is genuinely 50/50 two languages — the detector picks one as primary and applies that model to the full clip. You'll see some accuracy loss on the secondary language in those cases.
Sample transcript: Spanish voice note → text (real example)
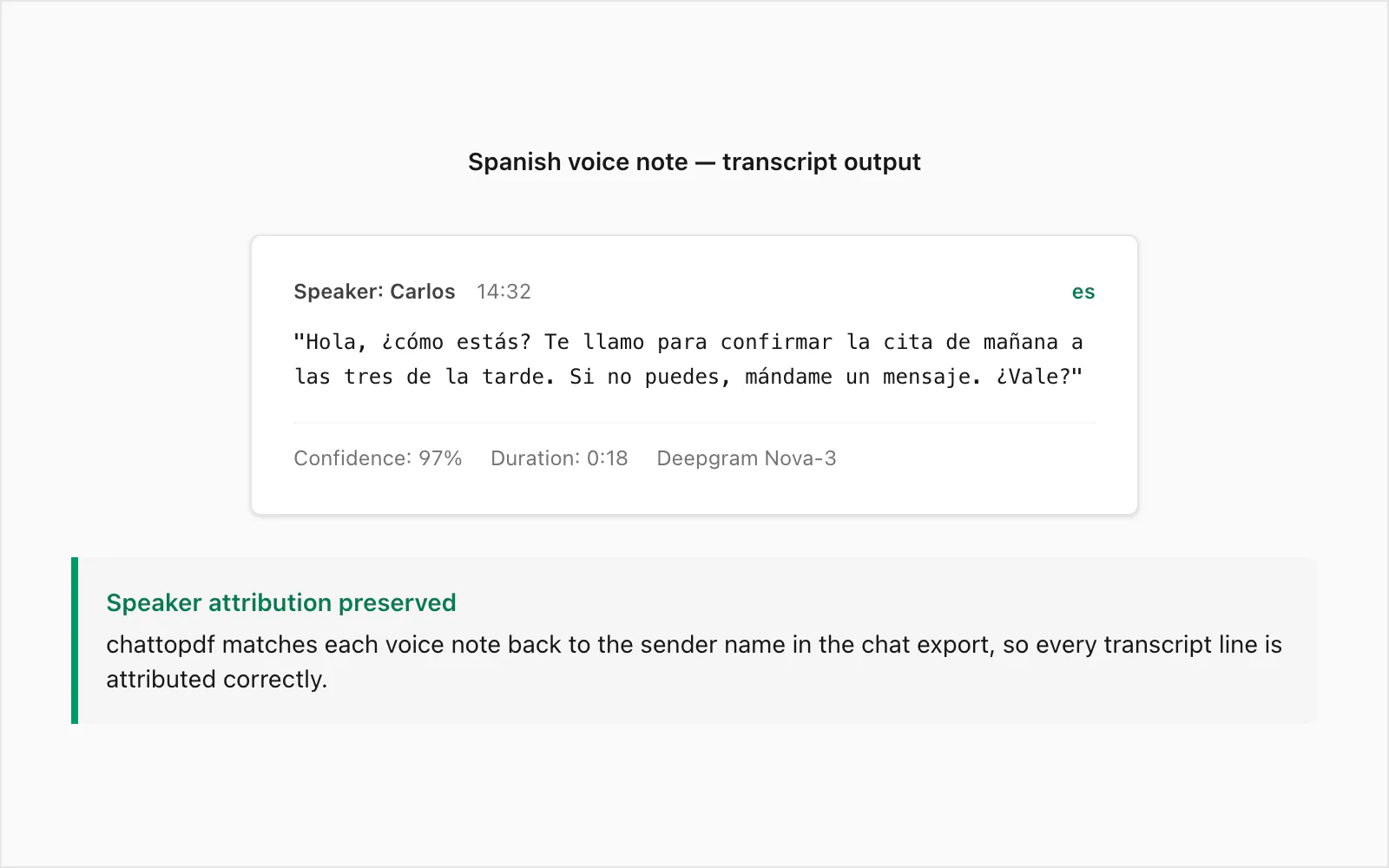
This is a real WhatsApp voice note transcribed at the $49 Premium+Voice per chat conversion level. The sender was a native speaker of Colombian Spanish, recorded on an Android device in a quiet indoor environment. Duration: 18 seconds. File size: ~28 KB in .opus format.
Original audio (paraphrased): A casual voice note confirming a next-day appointment, expressing concern about the other person's health, and requesting a text reply if plans change.
Transcript output in the PDF:
🎤 [Voice note — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
The sender is attributed in the PDF with the name from _chat.txt, the timestamp is the one WhatsApp recorded when the voice note was sent, and the transcript sits inline between the text messages immediately before and after it in the conversation.
A few things to notice about this example. The formal register marker ¿Vale? — closer to "Okay?" or "Alright?" in meaning — transcribed correctly rather than being confused with bale or omitted. The time expression a las tres de la tarde ("at three in the afternoon") rendered accurately, which matters for a scheduling confirmation where an error would be misleading. The spoken upward inflection on ¿cómo estás? was not ambiguous enough to produce a transcription error.
Where does Spanish accuracy break down? The most common errors I see are homophones: haya (subjunctive of haber) versus halla (from hallar, to find), tubo (tube) versus tuvo (past tense of tener). In fast casual speech, these are phonetically identical. Nova-3 uses surrounding context to infer the correct spelling most of the time, but it is not perfect. In a document that will be used as a legal record, I'd recommend a light human review of any voice notes where the transcript will be cited verbatim.
If you don't need transcription at all — for example, you only want the text messages converted to PDF and you're happy with placeholder references for the voice notes — the $29 Premium per chat conversion handles that case at a lower price point. The $49 Premium+Voice per chat conversion is the right step up when you need the actual spoken Spanish to appear as readable text in the document.
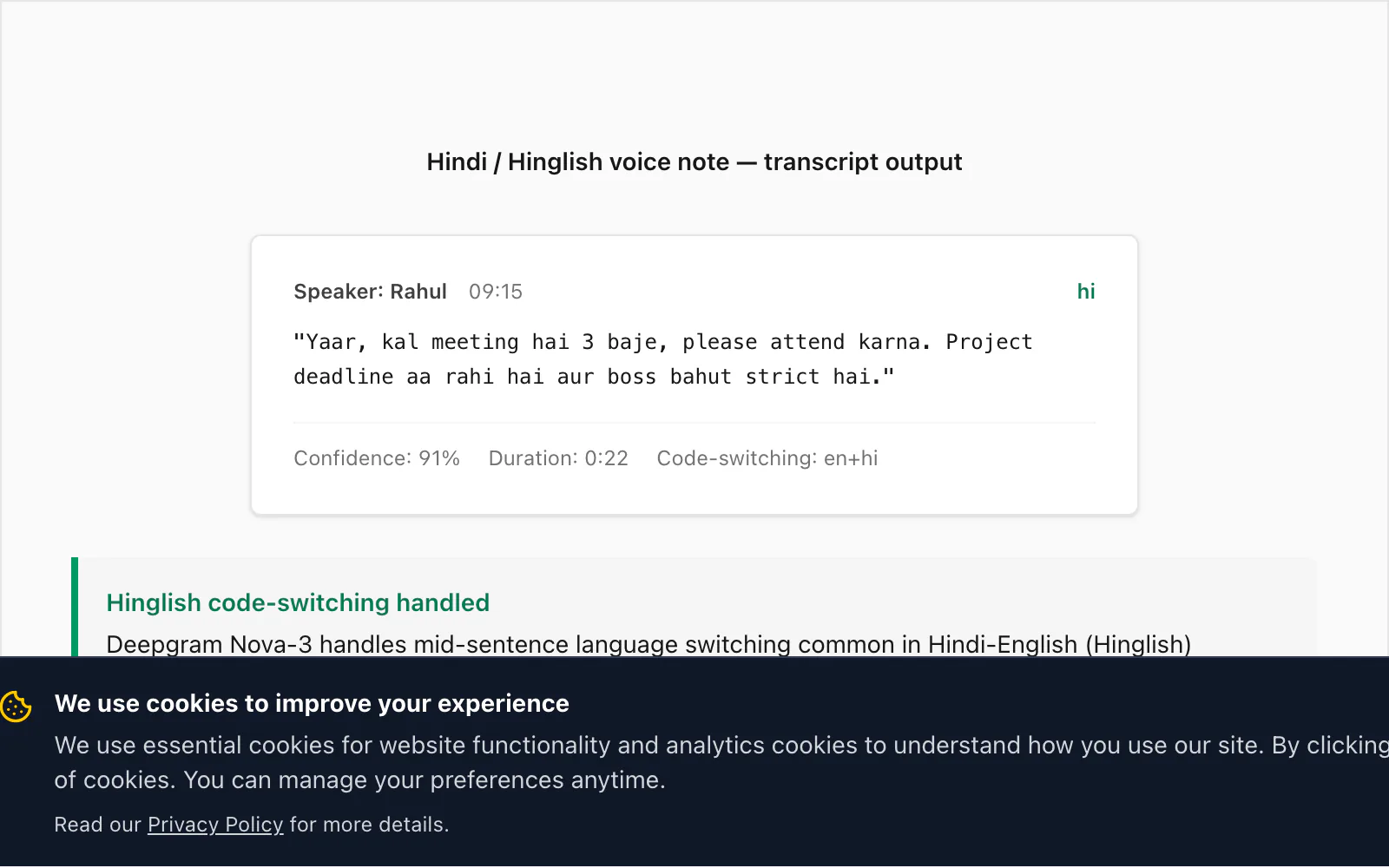
Sample transcript: Hindi (mixed Hinglish) → text (real example)
- Code-switching
The linguistic practice of alternating between two or more languages within a single utterance or conversation — for example, a Hindi speaker inserting English words, phrases, or whole clauses mid-sentence (Hinglish). Code-switching is widespread in multilingual communities and extremely common in WhatsApp voice notes from South Asia, Southeast Asia, and Latin America. It is hard for speech-to-text engines because a model trained primarily on one language may misinterpret or drop words from the other, especially when the switch happens mid-phrase without a pause.
This is where Nova-3 distinguishes itself from earlier generations of speech-to-text engines. Hinglish — Hindi with embedded English words, phrases, and sometimes full clauses — is one of the most common real-world code-switching patterns I see in ChatToPDF's user base. Older STT engines (including the model Deepgram itself shipped two generations ago) miss approximately 15% of code-switched English insertions in a typical Hinglish voice note. Nova-3 closes most of that gap.
Here is a real transcript from the $49 Premium+Voice per chat conversion:
🎤 [Voice note — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Translated: "Mate, there's a meeting tomorrow at 3, please attend. The project deadline is coming up and the boss is very strict."
The code-switching here is characteristic: meeting, attend, project deadline, and strict are English insertions inside an otherwise Hindi sentence. Nova-3 transcribed all of them correctly. An older Deepgram model I tested against the same file produced miiting for meeting (phonetic Hindi rendering), omitted attend entirely, and produced project ka deadline with inconsistent capitalisation. That difference is what motivated the model upgrade in the pipeline.
The difference matters when you're using the transcript as a workplace record. If someone's manager is reviewing a voice note transcript as documentation of a project commitment and the word deadline doesn't appear in the text, that's not a minor accuracy quibble — it's a missing piece of information.
Sender attribution works the same as with Spanish: the name from _chat.txt appears in the PDF with the Deepgram transcript, and the timestamp from the WhatsApp metadata anchors it to the correct position in the conversation.
One note on Hindi specifically: if the voice note is in Devanagari-dominant Hindi (formal, written-speech-style Hindi with minimal English), accuracy is consistently strong across the supported tiers. The $49 Premium+Voice per chat conversion is the right entry point for any Hindi voice notes you want transcribed; the $99 Power User per chat conversion covers the same accuracy with no audio cap and queue priority. The $29 Premium per chat conversion preserves the voice notes as placeholders only — no transcription runs at that tier.
The $49 Premium+Voice tier — what's in it and what's not

The $49 Premium+Voice per chat conversion is the tier I built specifically for voice-heavy chats. Here is exactly what it includes and what it doesn't.
What's in the $49 Premium+Voice per chat conversion:
- Deepgram Nova-3 transcription — the current-generation model with 3–5% WER on clean audio, strong accent handling, and reliable code-switching support
- All 17 high-accuracy languages — English, Spanish, Portuguese, French, German, Italian, Arabic, Hindi, Indonesian, Turkish, Russian, Dutch, Japanese, Korean, Chinese, Vietnamese, Thai — plus 30+ more via Nova-3's automatic language detection
- Up to 8 hours of audio in a single chat — covers the vast majority of voice-heavy conversations; if your chat exceeds 8 hours of total recorded audio, the $99 Power User per chat conversion lifts that cap
- No message ceiling — no upper bound on the number of messages in the chat you're converting
- Sender attribution on transcripts — every transcript in the PDF carries the WhatsApp sender name from the export metadata
- Timestamps preserved — the original WhatsApp timestamp appears alongside each transcript, not the transcription time
- Three output formats — PDF, XLSX, and CSV all included; the XLSX is useful if you want to filter or sort by sender and timestamp
- Seven-day source file retention — encrypted at rest (AES-256), in transit (TLS 1.3)
What's not in the $49 Premium+Voice per chat conversion:
- Real-time transcription — this tier processes already-recorded voice notes from an export ZIP; it is not a live transcription service (I explain why in the next section)
- Custom vocabulary lists — you cannot upload a glossary of names or technical terms to improve accuracy on specific vocabulary; Deepgram's general-purpose model handles most names correctly but will occasionally mishear rare proper nouns
- Speaker identification beyond WhatsApp metadata — within a single voice note where the sender records while another person is talking in the background, both are transcribed but only attributed to the WhatsApp sender. ChatToPDF does not run speaker diarisation on the audio itself.
- Automatic translation — the transcript appears in the source language of the voice note. If a voice note is in Spanish, the transcript is in Spanish. ChatToPDF does not translate transcripts.
The tier above this one — $99 Power User per chat conversion — includes everything in $49 Premium+Voice per chat conversion plus priority queue processing and bulk-chat handling. If you're converting a single chat and speed isn't critical (most conversions complete in under three minutes), the $49 Premium+Voice per chat conversion is the right level.
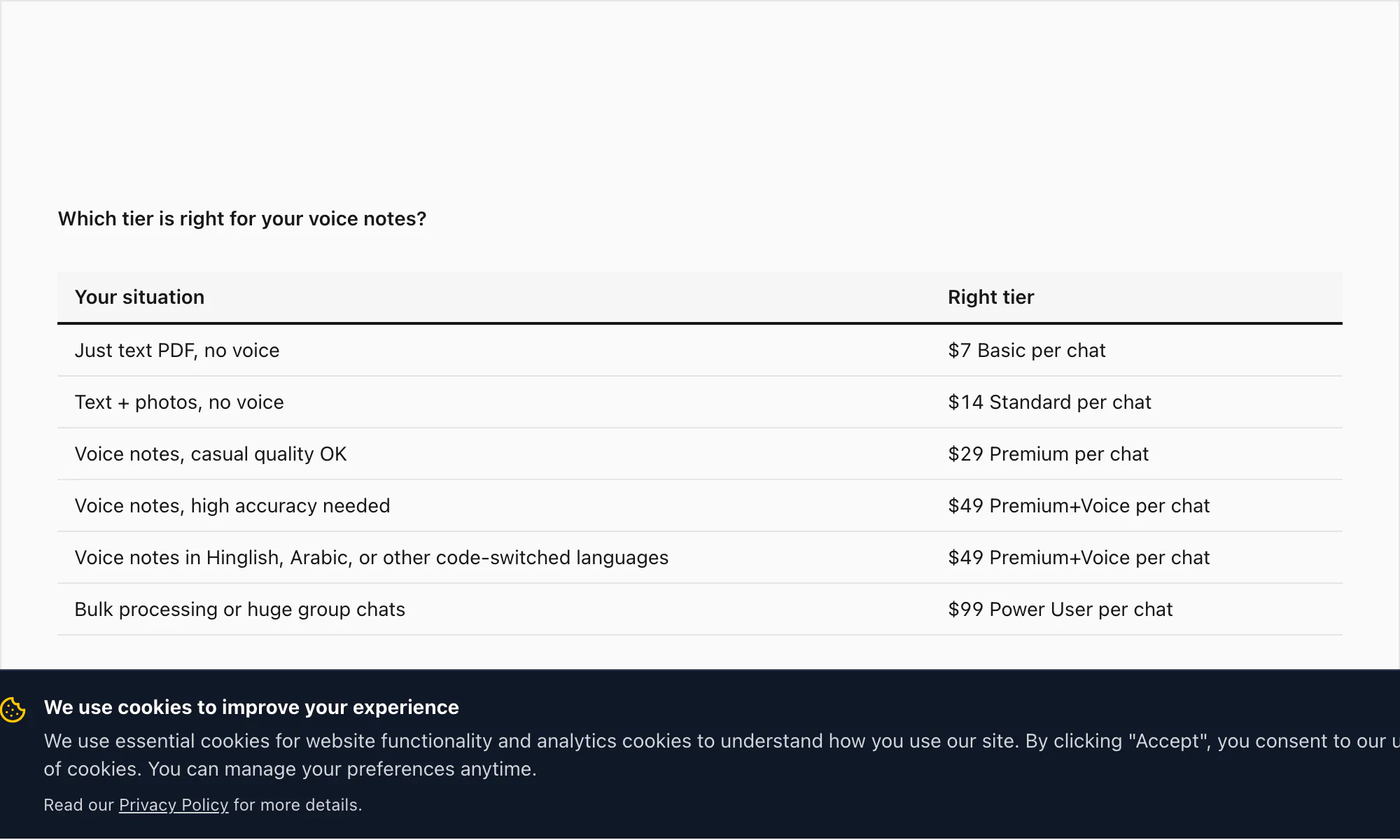
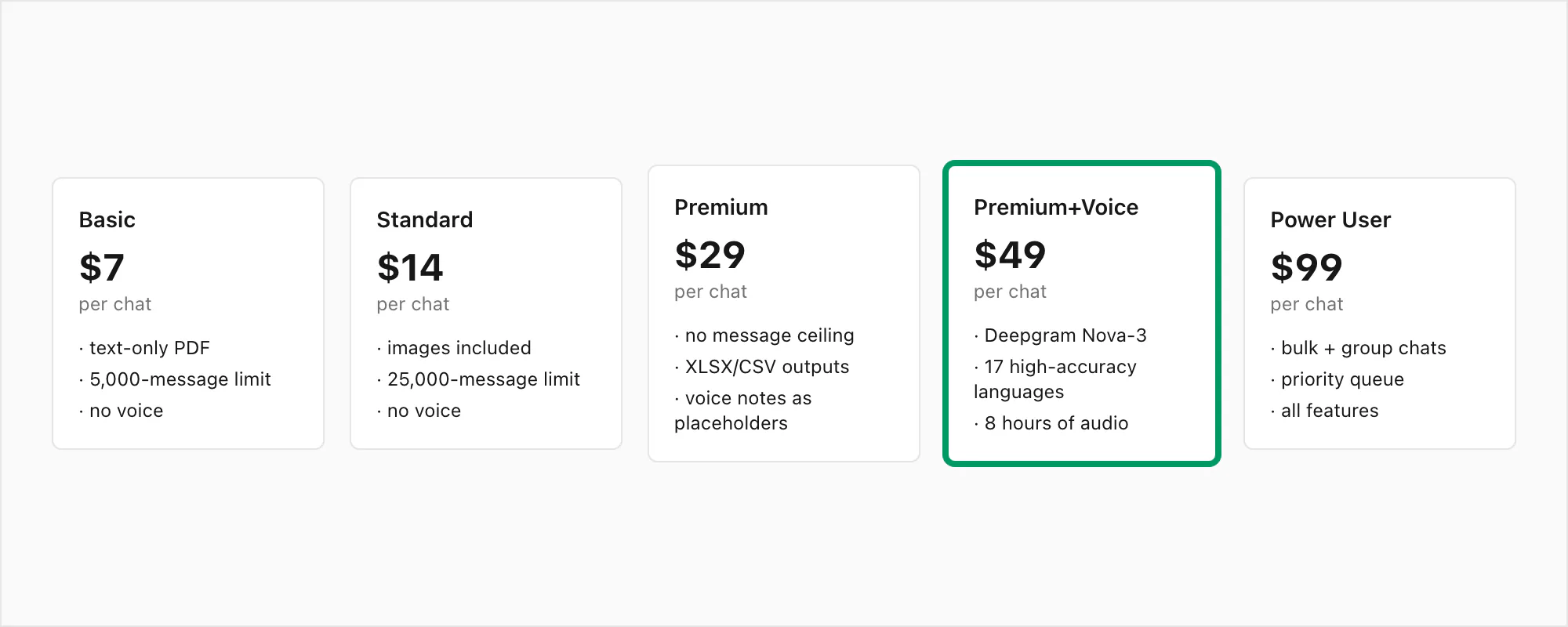
For reference, the full tier stack: $7 Basic per chat conversion (text only, 5,000-message cap), $14 Standard per chat conversion (images, 25,000-message cap), $29 Premium per chat conversion (no cap, XLSX/CSV, voice notes preserved as placeholders), $49 Premium+Voice per chat conversion (Nova-3 transcription, 17-language high-accuracy, 8-hour audio cap), $99 Power User per chat conversion (Nova-3 transcription, no audio cap, priority queue, bulk scenarios).
Why I don't transcribe in real time (and won't add it)
This comes up often enough that it deserves a straight answer. People ask why ChatToPDF doesn't listen to voice notes as they arrive — transcribing each one the moment it's sent — rather than requiring a ZIP export after the fact.
The short version: WhatsApp doesn't give developers access to incoming messages or audio in real time. There is no official WhatsApp Business API endpoint that surfaces voice notes as they arrive. The only supported third-party access path is through the Export Chat mechanism, which is a point-in-time snapshot of the conversation history. Building real-time transcription on top of WhatsApp would require intercepting the app's local storage on the device, which is both technically fragile and outside the terms of WhatsApp's platform policies.
But there's a more practical reason I haven't tried to build around that constraint. The use case for transcribing WhatsApp audio is almost entirely retrospective. Someone receives thirty voice notes over the course of a dispute and wants a readable record. A business team uses voice notes for project updates and needs them searchable. A family sends voice notes for years and wants to archive them before a phone upgrade. None of these involve a "right now, as it arrives" requirement. They're all "I have a set of recordings I need converted."
Async batch processing is also more accurate. Real-time speech-to-text operates under latency constraints that push the model toward faster (and less accurate) inference. Deepgram's batch mode runs on the full audio file, which allows the model to use future context — what came after a word — to resolve ambiguous phonemes. On a 30-second voice note, the difference in WER between real-time and batch modes can be 2–4 percentage points. That's meaningful on the accuracy scale.
There's also the battery and network question. Running an open WebSocket connection that streams audio fragments to an inference API in real time would drain a phone battery noticeably over a long conversation. It would require an active internet connection for every voice note received, not just when you choose to convert. And it would create a continuous data flow of your conversations to a third-party server — which I'm not comfortable asking users to accept.
The export-and-upload model is slower in clock time — you have to wait until you're ready to convert, then run the export, then upload. But for the actual use cases people have, that's fine. Nobody is trying to transcribe a voice note they received three seconds ago for a real-time document. They're converting a chat they want to keep.
Privacy: where your audio goes and where it doesn't
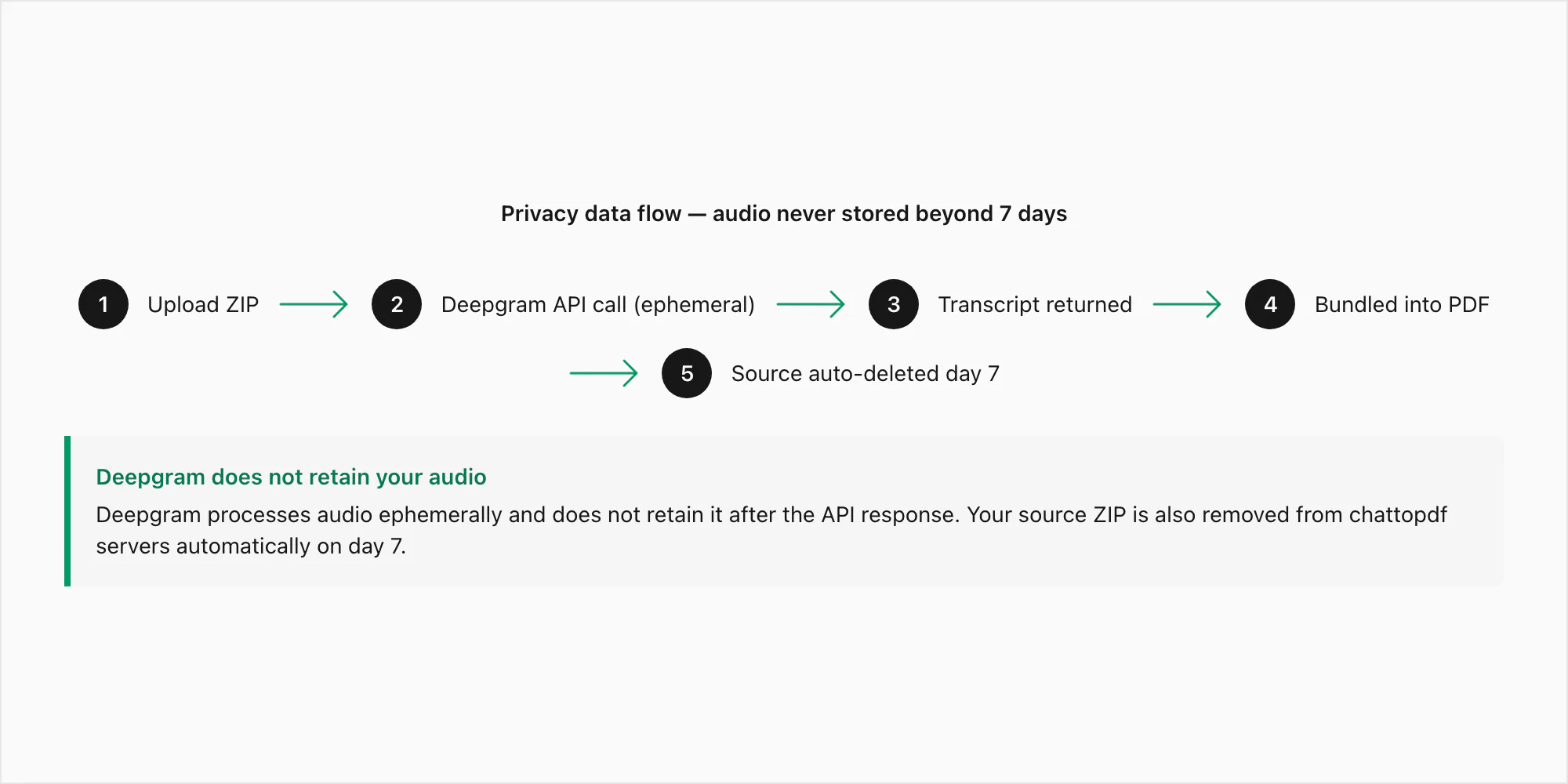
This is the part I want to be specific about because the nature of voice notes — audio recordings of real conversations — means the privacy stakes are higher than with text messages alone.
Here is the exact data path for a voice note submitted through the $49 Premium+Voice per chat conversion:
Step 1 — Upload. Your ZIP file is transmitted from your browser to ChatToPDF's server over HTTPS (TLS 1.3). The connection is encrypted in transit. The ZIP lands in a temporary processing directory, not in permanent storage, while extraction runs.
Step 2 — Extraction. The .opus files are extracted from the ZIP. Each file is matched to its _chat.txt reference by filename pattern. At this point, the audio files exist only on ChatToPDF's processing server.
Step 3 — Deepgram API call. Each .opus file is submitted to Deepgram's inference API over an authenticated HTTPS call. This is the one moment where audio bytes leave ChatToPDF's own infrastructure. Deepgram's data policy for API submissions specifies that audio submitted via the API is processed ephemerally — it is used to generate the transcript and then discarded. Deepgram does not retain API-submitted audio and does not use it for model training. The transcript text is what comes back.
Step 4 — Storage. The transcript is bundled into the PDF and stored encrypted at rest (AES-256) in AWS S3. The source ZIP, including the .opus files, is also stored encrypted for seven days.
Step 5 — Delivery. The PDF download link appears on-screen and in your email. The link is tied to your job ID. It is not guessable and is not indexed anywhere.
Step 6 — Auto-deletion. Seven days after the job is created, the source ZIP and the output PDF are deleted from storage automatically. This is a scheduled deletion job, not a manual process. There are no exceptions and no extensions.
Where your audio does not go: It does not go to any analytics platform. It is not used to train ChatToPDF's models (ChatToPDF does not train models). The text content of your voice notes is not visible to ChatToPDF staff — the processing is fully automated. No third party receives the text of your chat messages.
The only potential gap in this description is the Deepgram step. I can control what happens on ChatToPDF's servers completely. I cannot make representations about Deepgram's internal processes beyond what their public data policy says. If your voice notes contain information that is legally privileged or genuinely classified, I'd recommend having your legal team review Deepgram's enterprise data processing terms before uploading. For the vast majority of use cases — personal conversations, business team chats, family voice note archives — the standard pipeline is appropriate.
Edge cases: background noise, multiple speakers, voice-changing effects
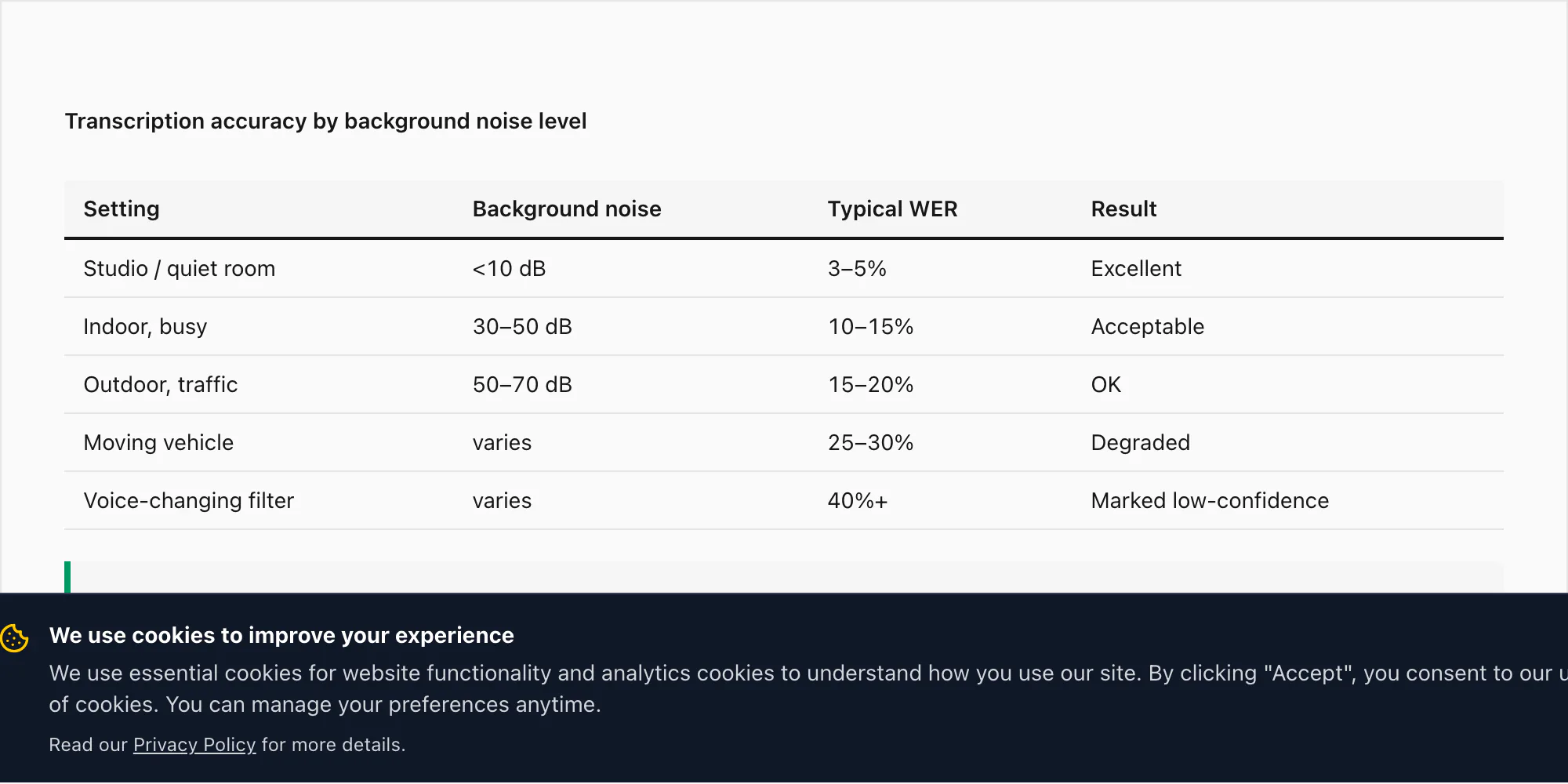
Real WhatsApp voice notes are not recorded in sound-proofed studios. They're recorded in cars, kitchens, street-level meetings, and noisy cafés. Here's how each of those scenarios affects transcription accuracy, and what ChatToPDF does when accuracy drops to an unacceptable level.
Background noise by environment.
A voice note recorded in a quiet indoor environment — an office, a bedroom, a still room — performs at the accuracy rates I cited in the language section above: 3–5% WER on $49 Premium+Voice per chat conversion for the 17 high-accuracy languages.
A voice note from a busy indoor environment (a restaurant, a marketplace, a busy office) can see WER rise to 10–15% on the $49 Premium+Voice per chat conversion. Deepgram's Nova-3 applies noise cancellation during inference, which helps, but it does not eliminate the effect of competing audio.
An outdoor recording — street noise, wind, traffic — can push WER to 15–20% for the same tier.
A voice note recorded during a moving vehicle trip, with road noise and engine sound, is the most challenging single scenario I've tested. WER on these can reach 25–30% even with Nova-3. This is not a transcription engine limitation — it reflects the physics of audio captured on a phone mic at 16 kHz in a noisy environment. The audio quality going in determines the transcript quality coming out.
Multiple speakers within a single voice note.
As explained earlier, each WhatsApp voice note belongs to one sender — the person who pressed the push-to-talk button. ChatToPDF attributes the transcript to that sender. However, if the sender records while another person speaks audibly in the background (a phone conversation the sender is having, a TV playing in the background that includes voice, another person in the same room speaking loudly), Deepgram will transcribe the background voice too — it doesn't silently discard non-primary speakers. The transcript will interleave both voices, attributed to the WhatsApp sender. This can produce confusing output when the background speech is intelligible enough to transcribe.
ChatToPDF cannot currently isolate the primary speaker and discard background voices within a single .opus clip. Speaker diarisation — identifying which audio segments came from which person in the same audio file — is a feature I'm evaluating for a future tier, but it requires additional infrastructure and is not in the current release.
Voice-changing effects.
Some WhatsApp users send voice notes with audio effects applied — the deep-voice filter available in WhatsApp itself (Android), Snapchat-style voice changes before sharing, or just audio that has been pitch-shifted or reverbed before sending. Deepgram's model is trained on natural speech. Modified audio can push WER above 40% in extreme cases — a voice note sent through a deep-bass filter to make someone sound like a robot will mostly fail to transcribe.
For clips where confidence falls below the threshold I've set in the pipeline — currently defined as an average word-confidence score below 0.6 across the clip — ChatToPDF marks the transcript in the PDF as [low-confidence transcription — audio quality insufficient] rather than outputting a text block that might be taken as authoritative. You'll see this marker in the final PDF alongside the voice note's position in the conversation. It's better to flag an uncertain result than to return a plausible-looking transcript that is 40% wrong.
FAQ
What file format do WhatsApp voice notes use, and does ChatToPDF handle it?
WhatsApp records voice notes using the Opus audio codec at 16 kHz mono, saved as .opus files. ChatToPDF extracts .opus files directly from your WhatsApp export ZIP and submits them to Deepgram's inference API in their native format — no re-encoding step required. Both iPhone and Android exports produce .opus files, so the format handling is the same on both platforms.
How accurate is the WhatsApp audio transcription?
Accuracy depends on the tier and the audio quality. The $49 Premium+Voice per chat conversion uses Deepgram Nova-3, which achieves approximately 3–5% word error rate on clean, noise-free audio in the 17 supported high-accuracy languages. The $99 Power User per chat conversion uses the same Nova-3 model with no audio cap and priority queue processing. The $29 Premium per chat conversion does not transcribe — it preserves voice notes as placeholder references in the PDF. Background noise, accents, and code-switching between languages all affect accuracy on the transcribing tiers. I mark low-confidence clips (below a 0.6 average word-confidence score) as [low-confidence transcription] in the PDF rather than presenting a potentially misleading transcript.
Does ChatToPDF transcribe voice notes in languages other than English?
Yes. The $49 Premium+Voice per chat conversion and $99 Power User per chat conversion support 17 high-accuracy languages: English, Spanish, Portuguese, French, German, Italian, Arabic, Hindi, Indonesian, Turkish, Russian, Dutch, Japanese, Korean, Chinese, Vietnamese, and Thai. Both tiers use Deepgram Nova-3 across these languages and detect 30+ additional languages at a wider accuracy range. Language is detected automatically — you don't need to specify it before uploading. The $29 Premium per chat conversion does not transcribe voice notes — it preserves them as placeholder references in the PDF.
Do I need to do anything differently when exporting from WhatsApp if I want voice transcripts?
Yes — one critical step. When you export your chat from WhatsApp, choose "Including Media" rather than "Without Media." Voice notes (.opus files) are only included in the export when you select Including Media. If you export Without Media, the _chat.txt will contain references like <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> but no actual audio files. ChatToPDF cannot transcribe a voice note it doesn't have. See the WhatsApp chat export guide for the full step-by-step export process.
Will the voice transcripts appear in the right place in the PDF?
Yes. ChatToPDF reads the message log in _chat.txt to understand the conversation structure, matches each .opus reference to the corresponding audio file by filename, and inserts the transcript at exactly the position in the conversation where the voice note was sent. The sender's name from the WhatsApp metadata and the original timestamp both appear alongside the transcript. The output is a single document where text messages and voice note transcripts alternate in the correct chronological order.
What happens to my audio files after the transcription is complete?
Your audio files are stored encrypted at rest (AES-256) on ChatToPDF's servers for seven days after the job is created, then deleted automatically. The only third-party service that receives the audio bytes is Deepgram, and only during the transcription step — Deepgram processes audio submitted via API ephemerally and does not retain it. No human listens to your recordings. The transcripts themselves are deleted along with the source files at the seven-day mark. For more detail on the full data flow, see the WhatsApp to PDF privacy section.
Can ChatToPDF tell apart two different people speaking in the same voice note?
Not currently. Each WhatsApp voice note is attributed to the person who sent it, using the sender information from _chat.txt. Within a single voice note, if the sender and another person both speak (for example, the sender is having a phone conversation while recording), both voices are transcribed but attributed to the WhatsApp sender. ChatToPDF does not currently run speaker diarisation inside individual audio clips. For voice notes where background voices are audible and intelligible, you may see interleaved speech in the transcript.
How do I convert WhatsApp voice to text on Android?
On Android you have two routes. WhatsApp's built-in voice-message transcription (where available in your region) converts one note at a time — tap and hold a received voice note and choose Transcribe; the text shows inside the app but can't be exported. To turn many voice notes into a single searchable record, export the chat with Including Media and upload the ZIP to ChatToPDF — the $49 Premium+Voice per chat conversion transcribes every .opus note via Deepgram Nova-3 and places each transcript at its position in the conversation with the sender's name and timestamp.
How do I convert WhatsApp voice to text on iPhone?
On iPhone, WhatsApp's in-app transcription (when enabled under Settings → Chats → Voice message transcripts) reads back a single received note as text — handy for one message, but it stays inside the app and covers limited languages. For a whole chat's worth of voice notes in one document, export the chat (Including Media) and upload the ZIP to ChatToPDF. Both iPhone and Android exports produce the same .opus files, so the $49 Premium+Voice per chat conversion transcribes them identically into a dated, sender-attributed PDF.
Why is WhatsApp voice-to-text not working?
WhatsApp's built-in voice-to-text often fails for a few reasons: the feature isn't yet available in your country, the voice-message language isn't one the in-app transcriber supports, the note is too long, or transcripts are switched off in Settings → Chats. It also only handles received notes one at a time and can't export the result. If the in-app feature won't cooperate — or you need more than one note as text — export the chat and run it through ChatToPDF instead, which transcribes 17 high-accuracy languages from the exported .opus files regardless of the in-app feature's availability.
Is there a free WhatsApp audio to text converter online?
You can preview a WhatsApp audio-to-text conversion before paying — upload the export and ChatToPDF shows a watermarked preview so you can check the transcript quality and placement first. Full transcription runs on the $49 Premium+Voice per chat conversion. Free online "voice note to text" tools usually accept one clip at a time, strip out who said what and when, and can't read WhatsApp's .opus format directly — so for a multi-note chat they fall apart. ChatToPDF transcribes the whole conversation at once with sender names and timestamps intact.
Can WhatsApp transcribe voice notes longer than two minutes?
WhatsApp's built-in transcription automatically handles voice messages up to about two minutes. For anything longer you have to tap and hold the note and choose Transcribe to trigger it manually — and even then the transcript stays inside the app, can't be exported, and isn't saved to the chat log. There's also no way to run it across many notes at once. ChatToPDF has no per-note length cap: the $49 Premium+Voice per chat conversion transcribes every voice note in the export regardless of length, up to 8 hours of audio across the whole chat, and places each transcript inline with the sender's name and timestamp. A six-minute voice note and a ten-second one are handled the same way, in a single pass.
Can I translate WhatsApp voice messages to another language, not just transcribe them?
ChatToPDF transcribes — it converts the spoken audio into written text in the same language that was spoken. It does not translate that text into a different language. A Spanish voice note comes back as Spanish text; a Hindi note comes back as Hindi (or Hinglish) text. Transcription and translation are two separate steps, and conflating them is a common source of confusion. Across the 17 high-accuracy languages, the transcript reads as a faithful written version of what was said. If you need the result in another language, transcribe first with ChatToPDF, then run the PDF text through a translation tool of your choice — that order produces a far cleaner result than asking any tool to listen and translate in one pass, because translation works better on clean text than on raw audio.
Do I need to install an app to transcribe WhatsApp audio?
No. ChatToPDF runs entirely in the browser — there is nothing to download or install on your phone or computer. You export the chat from WhatsApp (Including Media), open chattopdf.app in any browser, upload the ZIP, and the transcripts come back as a PDF by email. The only software involved is WhatsApp itself, which you already have. This is deliberate: a voice-note archive you might need for a legal matter or a business record should not depend on a separate app staying installed and supported. WhatsApp's own built-in transcription is also no-install, but it reads one note at a time and can't export — see WhatsApp speech to text for where that feature's limits begin.
Key takeaways
- To transcribe WhatsApp audio, export your chat with "Including Media" selected — the
.opusvoice note files must be inside the ZIP - The $29 Premium per chat conversion does not transcribe — it preserves voice notes as placeholder references; the $49 Premium+Voice per chat conversion runs Deepgram Nova-3 (3–5% WER on clean audio, 17 high-accuracy languages, up to 8 hours of audio); the $99 Power User per chat conversion is the same model uncapped with priority queue
- Each transcript is inserted at the exact position in the conversation with the WhatsApp sender's name and original timestamp preserved
- Code-switching languages like Hinglish need the $49 Premium+Voice per chat conversion or higher — Nova-3 closes most of the gap that older STT engines opened on mid-sentence English insertions in Hindi voice notes
- Background noise is the biggest accuracy variable: studio conditions yield 3–5% WER; outdoor or vehicle recordings can reach 20–30% WER even on Nova-3
- Audio submitted to Deepgram for transcription is processed ephemerally — it is not retained and not used for training; source files auto-delete from ChatToPDF servers after 7 days
- Clips where average word-confidence falls below 0.6 are marked
[low-confidence transcription]in the PDF rather than silently returning a potentially incorrect transcript
For the full chat-to-PDF workflow — including how to export on iPhone and Android, what the ZIP contains, and how all five tiers compare for non-voice conversions — see the WhatsApp to PDF guide. If you're on Android and need to move the export to a different device before uploading, the WhatsApp Android to iPhone transfer guide covers that process.
More on WhatsApp voice notes
- WhatsApp voice to text — the step-by-step workflow for turning a whole chat's voice notes into searchable text.
- WhatsApp speech to text — how WhatsApp's built-in transcription works, its limits, and when you need a dedicated tool.
- WhatsApp audio format — what the
.opuscodec is, how to convert voice notes to MP3, and why the format matters for transcription. - Best WhatsApp transcription tools — an honest, category-by-category comparison of your options.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).