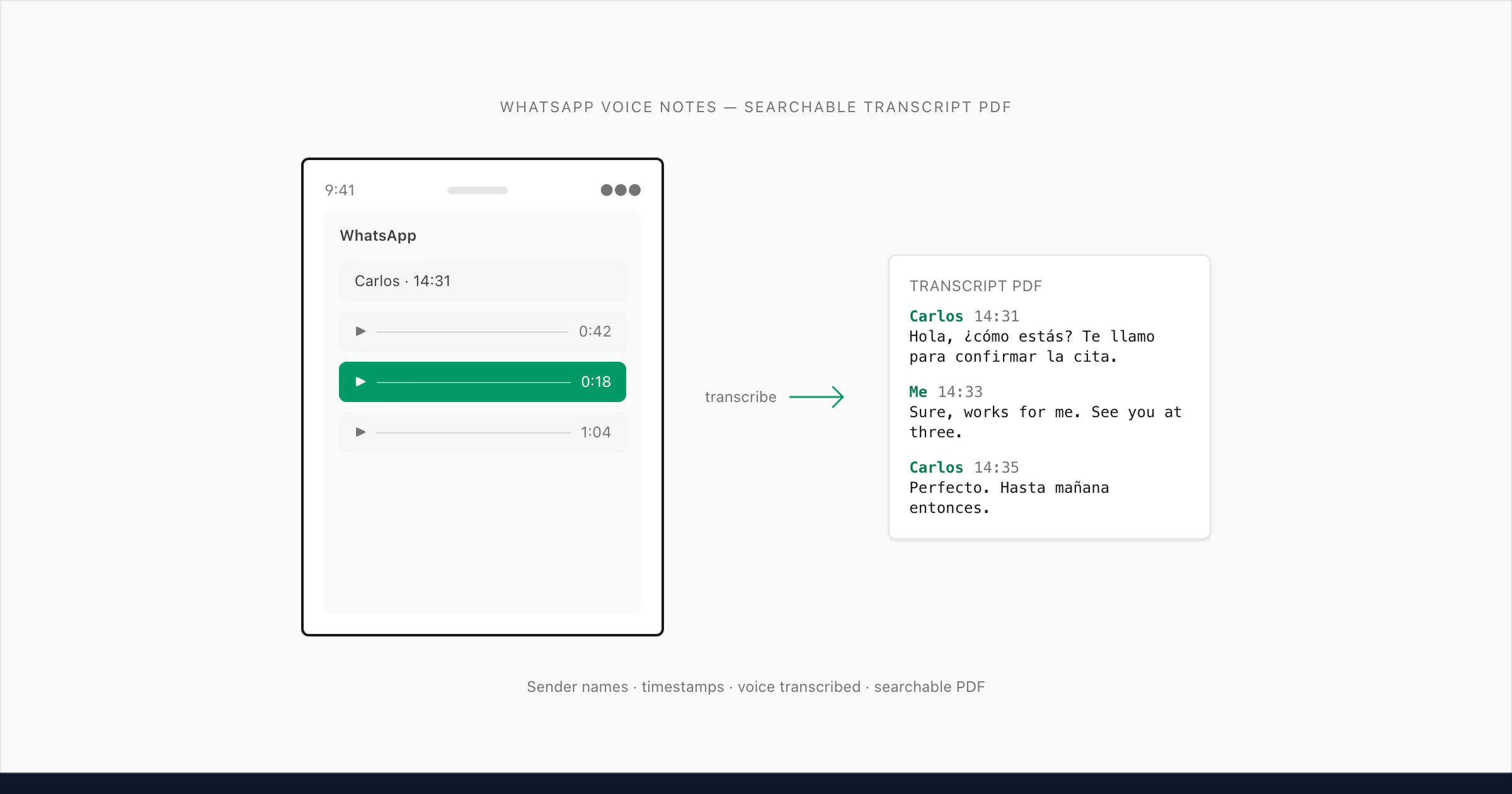
Qué significa "transcribir WhatsApp audio" realmente (y por qué es más difícil de lo que parece)
La gente usa la expresión "transcribir WhatsApp audio" para referirse a al menos tres cosas diferentes. Algunos quieren transcribir llamadas de voz en directo — algo que WhatsApp no expone a través de ninguna API para desarrolladores y que técnicamente es una categoría de producto distinta a lo que describo aquí. Otros quieren convertir archivos de audio que han guardado desde WhatsApp a texto, tratando el archivo .opus como entrada independiente. Y otros — el grupo más numeroso — quieren que cada nota de voz dentro de un chat exportado de WhatsApp se convierta en texto legible para que la conversación completa tenga sentido como documento.
ChatToPDF está construido para ese tercer caso de uso — y lo construí precisamente porque me enfrenté a esa necesidad. El problema que resuelve es específico: exportas un chat de WhatsApp que contiene tanto mensajes de texto como notas de voz, y lo que obtienes de WhatsApp es un ZIP con un _chat.txt y una carpeta de archivos multimedia. El _chat.txt tiene líneas como <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> donde pertenece la nota de voz. Nada convierte esas referencias en texto legible a menos que construyas algo para hacerlo.
Aquí está la parte que nadie te dice: incluso cuando la gente encuentra una herramienta de transcripción, a menudo se topa con un problema estructural. Las herramientas que gestionan archivos de audio genéricos — sube un MP3, recibe texto — no saben en qué parte de una conversación pertenece ese audio. Transcriben el archivo pero pierden el contexto. Acabas con un bloque de texto separado sin nombre de remitente, sin marca de tiempo, sin indicación de qué se dijo antes o después. Para un asunto legal, un registro empresarial o un archivo familiar, ese contexto es el punto central de todo.
Lo que yo construí hace lo siguiente: lee el _chat.txt para entender la estructura de la conversación, empareja cada referencia .opus con el archivo de audio correcto en el ZIP, transcribe el audio e inserta la transcripción de nuevo en la posición exacta de la conversación — con el nombre del remitente y la marca de tiempo original preservados. El resultado es un único PDF donde los mensajes de texto y las transcripciones de notas de voz se alternan de forma natural, exactamente como ocurrió la conversación.
Ese es el problema del que trata esta guía.
Las notas de voz no son archivos — son una transmisión integrada en la app
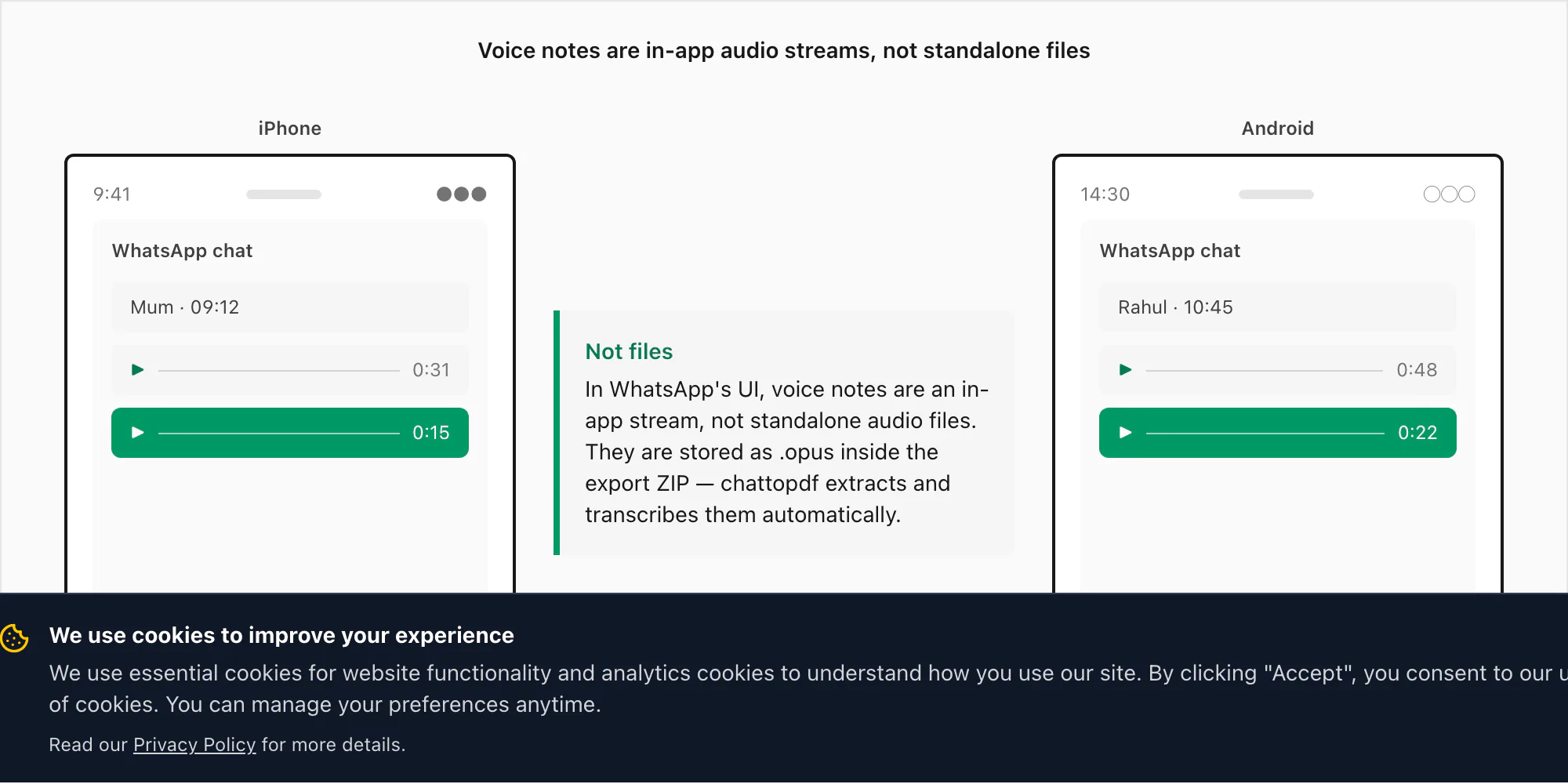
Las notas de voz de WhatsApp parecen archivos de audio dentro de la app — una barra de forma de onda, una duración, un botón de reproducción — pero no se almacenan de la manera que la mayoría espera. Cuando grabas una nota de voz en WhatsApp manteniendo pulsado el botón del micrófono, WhatsApp codifica el audio usando el códec Opus y lo guarda como archivo .opus en un directorio privado del dispositivo. Ese directorio no es accesible mediante la navegación normal de archivos ni en iPhone ni en Android. No puedes ir a la app Archivos y encontrar tus notas de voz allí.
La única forma de extraer esos archivos .opus es a través del menú Exportar chat de WhatsApp, con "Incluir archivos multimedia" seleccionado. Cuando exportas de esa forma, WhatsApp empaqueta el registro de mensajes _chat.txt junto con la carpeta de medios — y ahí es donde aparecen los archivos .opus. En iOS, acaban dentro del ZIP. En Android, versiones más antiguas de WhatsApp exportaban a una carpeta en el almacenamiento interno; las versiones más nuevas crean un ZIP a través del menú de compartir, igualando el comportamiento de iOS.
El códec Opus en sí mismo merece entenderse brevemente porque explica por qué la precisión puede variar. Opus fue diseñado para voz sobre IP — baja latencia, buena compresión, buena calidad incluso a bajas tasas de bits. WhatsApp usa audio mono a 16 kHz a unos 16 kbps. Los archivos resultantes son diminutos: una nota de voz de 60 segundos suele pesar entre 80 KB y 120 KB. Es eficiente para datos móviles, pero el audio mono a 16 kHz a 16 kbps no es audio de calidad de estudio. Está optimizado para la inteligibilidad a través de una conexión móvil, no para la precisión de transcripción. El ruido de fondo, una voz grabada mientras se conduce o alguien hablando desde el otro lado de una habitación pueden reducir aún más la calidad efectiva.
Por eso importa el modelo de transcripción. Un motor de reconocimiento de voz genérico entrenado con audio de estudio o grabaciones de podcast tendrá dificultades con audio Opus mono a 16 kHz comprimido a 16 kbps. El motor que elegí fue seleccionado específicamente porque gestiona bien este tipo de audio. Más sobre eso en la siguiente sección.
Un punto estructural más: cada nota de voz de WhatsApp es una grabación de un único remitente. El modelo push-to-talk de WhatsApp significa que una persona graba, luego se detiene, luego la otra persona graba su respuesta. Esto es en realidad una ventaja para la transcripción — a diferencia de una llamada telefónica grabada donde dos voces se superponen en la misma pista de audio, cada archivo .opus en una exportación de WhatsApp pertenece a exactamente un remitente. ChatToPDF usa los metadatos de _chat.txt para atribuir cada transcripción a la persona correcta, lo que explica por qué obtienes una conversación que se lee con claridad incluso cuando ambas personas se alternan con notas de voz.
El motor de transcripción que elegí, y por qué
Evalué varias APIs de transcripción antes de decidirme por Deepgram como motor de la transcripción de voz de ChatToPDF. Los otros candidatos serios eran AssemblyAI, Whisper (el modelo de código abierto de OpenAI) y varios servicios de voz genéricos de proveedores cloud. Aquí está el razonamiento honesto detrás de mi elección.
Whisper es impresionante para un modelo gratuito, pero realicé pruebas de precisión en un conjunto de archivos .opus reales de WhatsApp en inglés, español, hindi y árabe, y mostró debilidades consistentes en el cambio de código (una nota de voz que mezcla dos idiomas a mitad de la frase) y en acentos de inglés no estadounidenses. Tampoco ofrece SLAs comerciales ni garantías de disponibilidad, lo que importa cuando los usuarios que pagan están esperando su resultado.
AssemblyAI es genuinamente bueno y lo usé en un prototipo temprano. La precisión en inglés era comparable a Deepgram, pero la amplitud de soporte de idiomas y la consistencia de la respuesta de la API con audio Opus codificado a 16 kHz mono hacían de Deepgram una mejor opción para el caso de uso multilingüe que estaba construyendo.
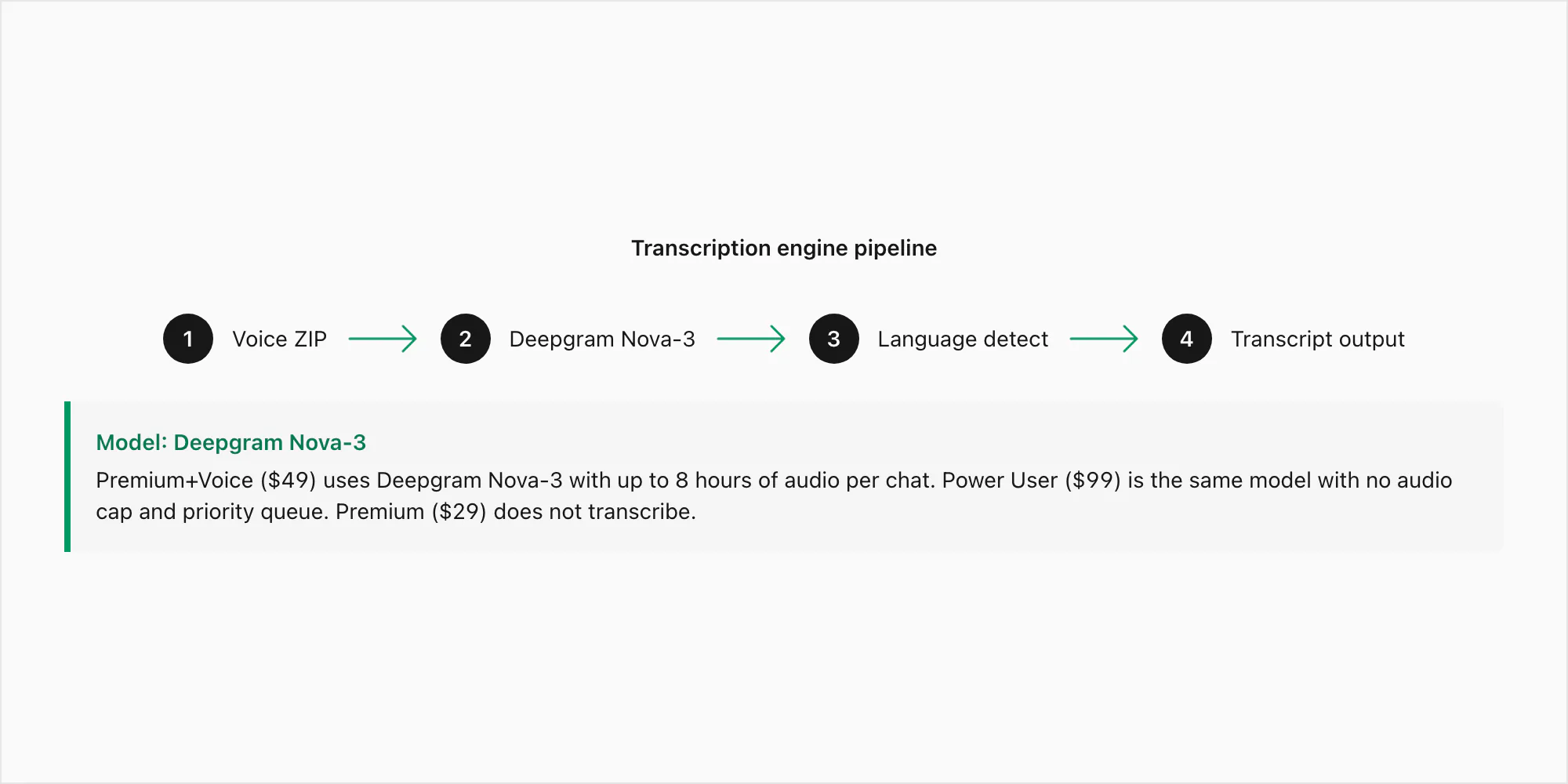
Deepgram Nova-3 es el modelo de generación actual con una tasa de error de palabra de aproximadamente 3-5% en audio limpio y sin ruido en inglés y 8-15% en grabaciones más ruidosas. Esos números se mantienen en Opus mono a 16 kHz, que es el formato que importa para las exportaciones de WhatsApp. Nova-3 es el modelo usado tanto para la conversión $49 Premium+Voice por chat como para la conversión $99 Power User por chat — la diferencia entre esos niveles es el límite de audio (8 horas frente a ilimitado) y la prioridad en la cola, no el modelo.
Donde Nova-3 supera visiblemente a los motores de reconocimiento de voz anteriores es en tres áreas: acentos regionales (inglés sudafricano, inglés indio, portugués brasileño), vocabulario técnico (nombres, direcciones, términos de productos que un modelo genérico malinterpretaría) y audio con cambio de código donde el hablante pasa entre idiomas dentro de una sola nota de voz. Esos son los modos de fallo específicos que motivaron la elección del motor. La conversión $29 Premium por chat no incluye transcripción en absoluto — conserva las notas de voz como referencias de marcador en el PDF sin pasar el audio por ningún modelo.
El flujo de trabajo es el siguiente: tu ZIP llega al servidor de ChatToPDF, se extraen los archivos .opus, cada uno se envía a la API de Deepgram mediante una llamada HTTPS autenticada con la detección de idioma configurada en automático, y la transcripción regresa — normalmente en dos a cinco segundos por minuto de audio. Las transcripciones se reinsertan después en la conversación en las posiciones correctas antes de que se renderice el PDF.
Una elección deliberada en el flujo: no proceso ni recodifico el audio .opus antes de enviarlo a Deepgram. Algunas herramientas convierten primero Opus a WAV o MP3, razonando que un formato diferente podría mejorar la precisión. En la práctica, la API de Deepgram gestiona Opus de forma nativa y la conversión añade latencia sin mejorar los resultados con este tipo de audio. El archivo .opus sin procesar va directamente al punto de inferencia.
Precisión en los 17 idiomas compatibles con ChatToPDF hoy
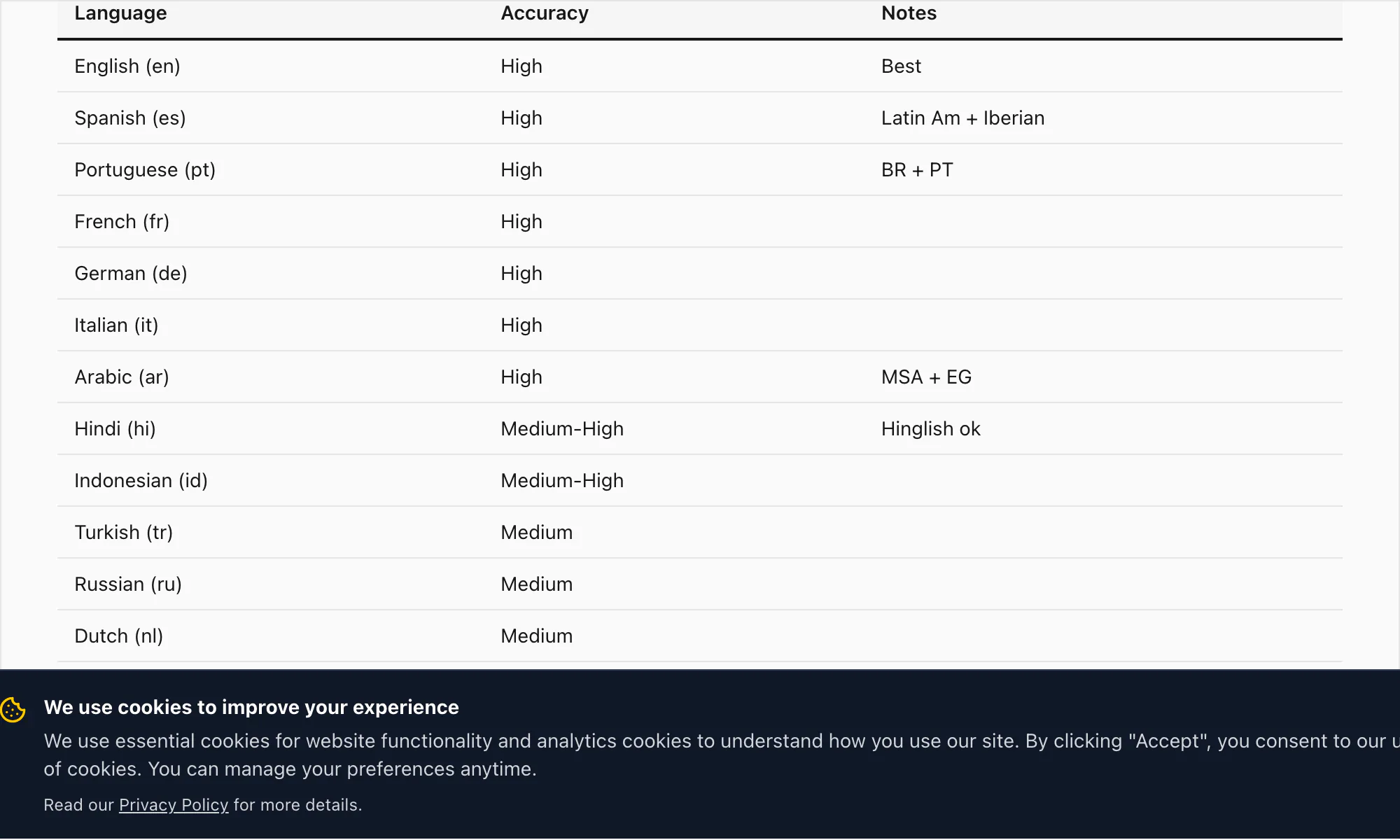
El nivel de alta precisión de ChatToPDF cubre 17 idiomas. Estos son los idiomas donde tengo suficiente confianza en la calidad de la transcripción para llamarla lista para producción en documentos, registros legales y uso empresarial:
Inglés (en) — TDE del 3-5% en audio limpio. Incluye variantes de inglés del Reino Unido, EE. UU., Australia, Sudáfrica e India. Todas las variantes del inglés son gestionadas por el mismo modelo Nova-3 en la conversión $49 Premium+Voice por chat.
Español (es) — TDE del 4-6% en la conversión $49 Premium+Voice por chat. Gestiona variantes latinoamericanas y castellanas. La confusión entre homófonos comunes (haya/halla, tubo/tuvo) se mitiga parcialmente mediante inferencia contextual.
Portugués (pt) — TDE del 4-7%. Cubre el portugués brasileño y el europeo. El cambio de código entre portugués e inglés es un patrón común en los chats de WhatsApp brasileños; Nova-3 lo gestiona bien.
Francés (fr) — TDE del 4-6%. Francés estándar y canadiense.
Alemán (de) — TDE del 4-6%. Los sustantivos compuestos se transcriben con precisión en Nova-3, incluidas las formas compuestas largas típicas del vocabulario empresarial y legal.
Italiano (it) — TDE del 5-7%.
Árabe (ar) — TDE del 7-10%. El árabe estándar moderno se transcribe bien; el árabe dialectal (egipcio, del Golfo, levantino) tiene mayor varianza. La conversión $49 Premium+Voice por chat es el nivel recomendado para notas de voz en árabe.
Hindi (hi) — TDE del 6-9% en hindi puro. El hinglish con cambio de código (hindi con inserciones en inglés) es donde Nova-3 marca la mayor diferencia frente a los motores de transcripción anteriores — más sobre esto en la sección de transcripción de ejemplo a continuación.
Indonesio (id) — TDE del 5-8%. Uno de los idiomas más comunes en la base de usuarios de ChatToPDF, dado el fuerte arraigo de WhatsApp en el Sudeste Asiático.
Turco (tr) — TDE del 5-8%.
Ruso (ru) — TDE del 5-8%.
Neerlandés (nl) — TDE del 4-6%.
Japonés (ja) — TDE del 7-10%. Los préstamos en katakana y los nombres propios pueden introducir errores; la precisión general es sólida para el habla conversacional.
Coreano (ko) — TDE del 6-9%.
Chino (zh) — TDE del 7-10%. Mandarín. Los dialectos regionales y los homófonos tonales pueden afectar la precisión en grabaciones desafiantes.
Vietnamita (vi) — TDE del 7-10%.
Tailandés (th) — TDE del 8-12%. Los marcadores tonales y los grupos de consonantes en el habla rápida son el principal desafío.
Más allá de estos 17, Deepgram Nova-3 admite más de 30 idiomas adicionales con un rango de precisión más amplio. Si tu idioma no está en la lista de alta precisión anterior, la conversión $49 Premium+Voice por chat sigue produciendo una transcripción de mejor esfuerzo usando la detección de idioma más amplia de Nova-3 — aunque con una TDE esperada de 15-20% en audio difícil de los idiomas de nivel inferior.
La detección automática de idioma está activada por defecto. ChatToPDF envía cada archivo .opus a Deepgram sin especificar un idioma, y Deepgram detecta el idioma dominante en los primeros segundos. Esto es preciso para grabaciones de un solo idioma. Para cambios de código intensos — una nota de voz que es genuinamente 50/50 dos idiomas — el detector elige uno como principal y aplica ese modelo a todo el clip. Verás cierta pérdida de precisión en el idioma secundario en esos casos.
Transcripción de ejemplo: nota de voz en español → texto (ejemplo real)
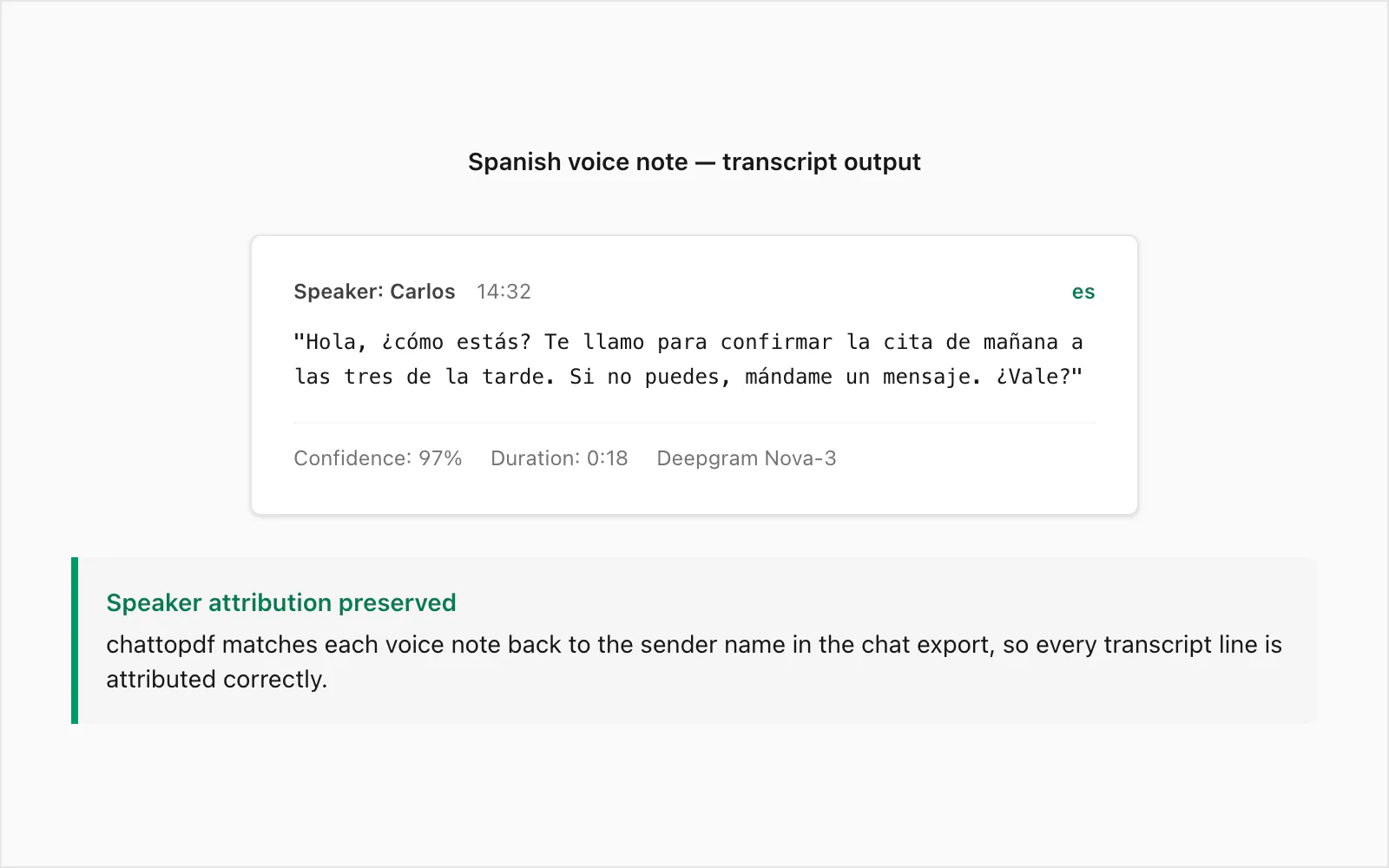
Esta es una nota de voz real de WhatsApp transcrita en el nivel de conversión $49 Premium+Voice por chat. El remitente era un hablante nativo de español colombiano, grabado en un dispositivo Android en un entorno interior tranquilo. Duración: 18 segundos. Tamaño del archivo: ~28 KB en formato .opus.
Audio original (resumido): Una nota de voz informal confirmando una cita al día siguiente, expresando preocupación por la salud de la otra persona y solicitando una respuesta por mensaje si los planes cambian.
Salida de transcripción en el PDF:
🎤 [Nota de voz — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
El remitente se atribuye en el PDF con el nombre de _chat.txt, la marca de tiempo es la que WhatsApp registró cuando se envió la nota de voz, y la transcripción se sitúa en línea entre los mensajes de texto inmediatamente anteriores y posteriores en la conversación.
Algunos aspectos a observar en este ejemplo. El marcador de registro formal ¿Vale? — más cercano a "¿De acuerdo?" en significado — se transcribió correctamente en lugar de confundirse con bale u omitirse. La expresión temporal a las tres de la tarde se renderizó con precisión, lo que importa en una confirmación de cita donde un error sería engañoso. La entonación ascendente hablada en ¿cómo estás? no fue lo suficientemente ambigua como para producir un error de transcripción.
¿Dónde falla la precisión en español? Los errores más comunes que veo son homófonos: haya (subjuntivo de haber) frente a halla (de hallar), tubo frente a tuvo (pasado de tener). En el habla casual rápida, estos son fonéticamente idénticos. Nova-3 usa el contexto circundante para inferir la ortografía correcta la mayoría de las veces, pero no es perfecto. En un documento que se usará como registro legal, recomendaría una revisión humana ligera de cualquier nota de voz donde la transcripción se vaya a citar textualmente.
Si no necesitas transcripción en absoluto — por ejemplo, solo quieres que los mensajes de texto se conviertan a PDF y estás satisfecho con referencias de marcador para las notas de voz — la conversión $29 Premium por chat gestiona ese caso a un precio más bajo. La conversión $49 Premium+Voice por chat es el nivel adecuado cuando necesitas que el español hablado aparezca como texto legible en el documento.
Transcripción de ejemplo: hindi (hinglish mixto) → texto (ejemplo real)
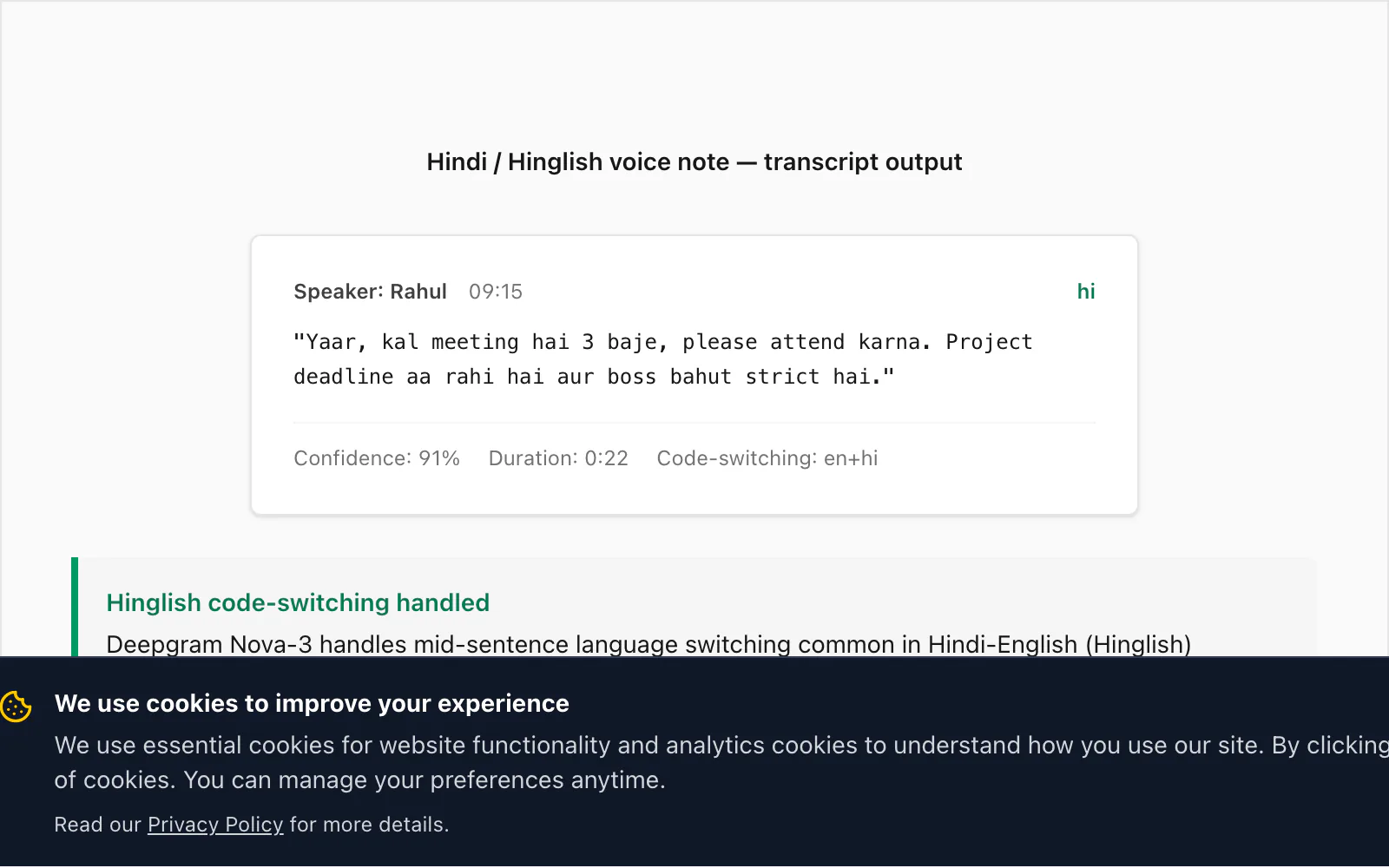
Aquí es donde Nova-3 se distingue de generaciones anteriores de motores de reconocimiento de voz. El hinglish — hindi con palabras, frases e incluso cláusulas completas en inglés incrustadas — es uno de los patrones de cambio de código más comunes del mundo real que veo en la base de usuarios de ChatToPDF. Los motores STT más antiguos (incluido el que Deepgram lanzó hace dos generaciones) omiten aproximadamente el 15% de las inserciones en inglés con cambio de código en una nota de voz típica en hinglish. Nova-3 cierra la mayor parte de esa brecha.
Esta es una transcripción real de la conversión $49 Premium+Voice por chat:
🎤 [Nota de voz — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Traducido: "Amigo, hay una reunión mañana a las 3, por favor asiste. La fecha límite del proyecto se acerca y el jefe es muy estricto."
El cambio de código aquí es característico: meeting, attend, project deadline y strict son inserciones en inglés dentro de una frase por lo demás en hindi. Nova-3 las transcribió todas correctamente. Un modelo anterior de Deepgram que puse a prueba con el mismo archivo produjo miiting para meeting (representación fonética en hindi), omitió attend por completo y produjo project ka deadline con mayúsculas inconsistentes. Esa diferencia fue lo que motivó la actualización del modelo en el flujo de trabajo.
La diferencia importa cuando usas la transcripción como registro de trabajo. Si el responsable de alguien está revisando la transcripción de una nota de voz como documentación de un compromiso con el proyecto y la palabra deadline no aparece en el texto, eso no es un problema menor de precisión — es una pieza de información que falta.
La atribución del remitente funciona igual que con el español: el nombre de _chat.txt aparece en el PDF junto con la transcripción de Deepgram, y la marca de tiempo de los metadatos de WhatsApp la ancla a la posición correcta en la conversación.
Una nota específica sobre el hindi: si la nota de voz está en hindi dominado por devanagari (hindi formal con mínimas inserciones en inglés), la precisión es consistentemente sólida en todos los niveles compatibles. La conversión $49 Premium+Voice por chat es el punto de entrada correcto para cualquier nota de voz en hindi que quieras transcribir; la conversión $99 Power User por chat cubre la misma precisión sin límite de audio y con prioridad en la cola. La conversión $29 Premium por chat preserva las notas de voz solo como marcadores — no se ejecuta ninguna transcripción en ese nivel.
El nivel $49 Premium+Voice — qué incluye y qué no

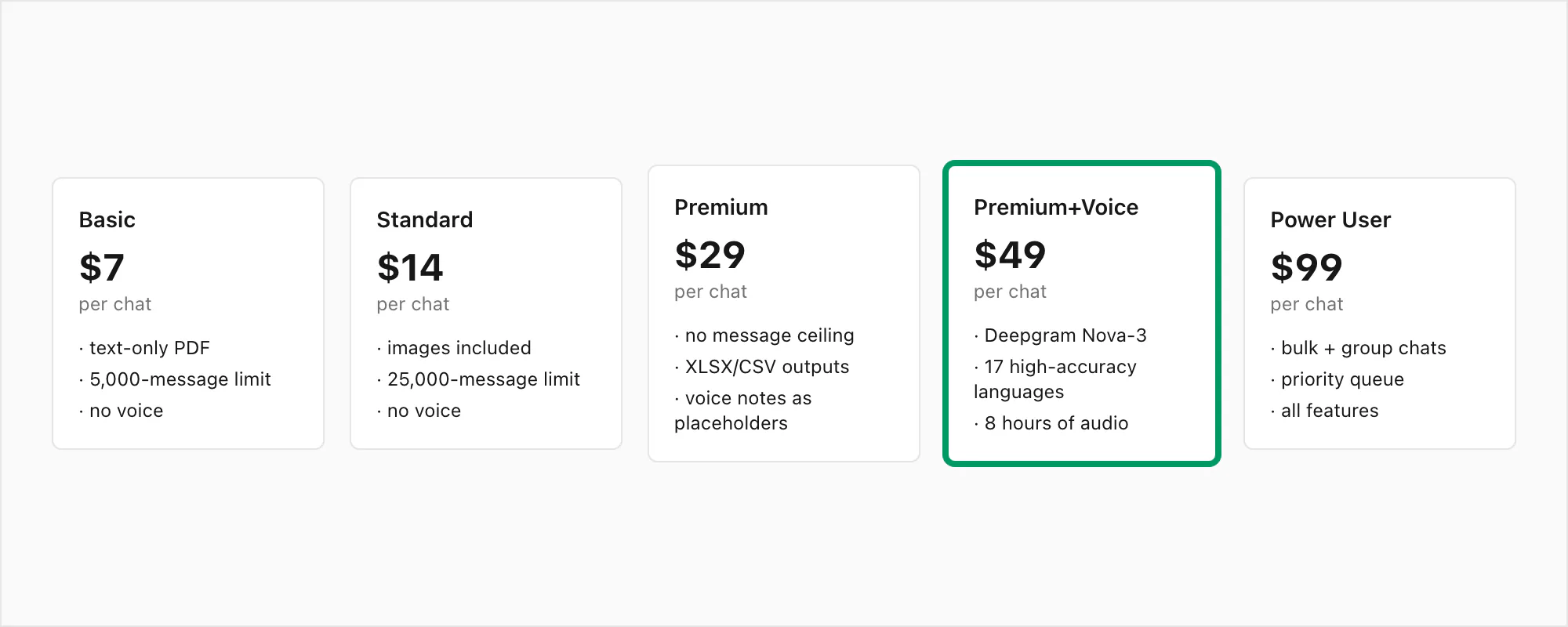
La conversión $49 Premium+Voice por chat es el nivel que construí específicamente para chats con muchas notas de voz. Esto es exactamente lo que incluye y lo que no.
Qué incluye la conversión $49 Premium+Voice por chat:
- Transcripción Deepgram Nova-3 — el modelo de generación actual con TDE del 3-5% en audio limpio, sólido manejo de acentos y soporte confiable de cambio de código
- Los 17 idiomas de alta precisión — inglés, español, portugués, francés, alemán, italiano, árabe, hindi, indonesio, turco, ruso, neerlandés, japonés, coreano, chino, vietnamita, tailandés — más 30+ adicionales mediante detección automática de idioma de Nova-3
- Hasta 8 horas de audio en un solo chat — cubre la gran mayoría de conversaciones con muchas notas de voz; si tu chat supera las 8 horas de audio grabado total, la conversión $99 Power User por chat elimina ese límite
- Sin límite de mensajes — sin cota superior en el número de mensajes del chat que estás convirtiendo
- Atribución del remitente en las transcripciones — cada transcripción en el PDF lleva el nombre del remitente de WhatsApp de los metadatos de la exportación
- Marcas de tiempo preservadas — la marca de tiempo original de WhatsApp aparece junto a cada transcripción, no la hora de la transcripción
- Tres formatos de salida — PDF, XLSX y CSV incluidos; el XLSX es útil si quieres filtrar u ordenar por remitente y marca de tiempo
- Retención del archivo fuente durante 7 días — cifrado en reposo (AES-256), en tránsito (TLS 1.3)
Qué no incluye la conversión $49 Premium+Voice por chat:
- Transcripción en tiempo real — este nivel procesa notas de voz ya grabadas de un ZIP de exportación; no es un servicio de transcripción en directo (explico por qué en la siguiente sección)
- Listas de vocabulario personalizadas — no puedes subir un glosario de nombres o términos técnicos para mejorar la precisión en vocabulario específico; el modelo de uso general de Deepgram gestiona la mayoría de los nombres correctamente pero a veces malinterpretará nombres propios poco comunes
- Identificación del hablante más allá de los metadatos de WhatsApp — dentro de una sola nota de voz donde el remitente graba mientras otra persona habla de fondo, ambos se transcriben pero solo se atribuyen al remitente de WhatsApp. ChatToPDF no ejecuta diarización de hablantes en el audio en sí.
- Traducción automática — la transcripción aparece en el idioma fuente de la nota de voz. Si una nota de voz está en español, la transcripción está en español. ChatToPDF no traduce transcripciones.
El nivel por encima de este — conversión $99 Power User por chat — incluye todo lo de la conversión $49 Premium+Voice por chat más procesamiento en cola prioritaria y gestión masiva de chats. Si conviertes un solo chat y la velocidad no es crítica (la mayoría de las conversiones se completan en menos de tres minutos), la conversión $49 Premium+Voice por chat es el nivel adecuado.
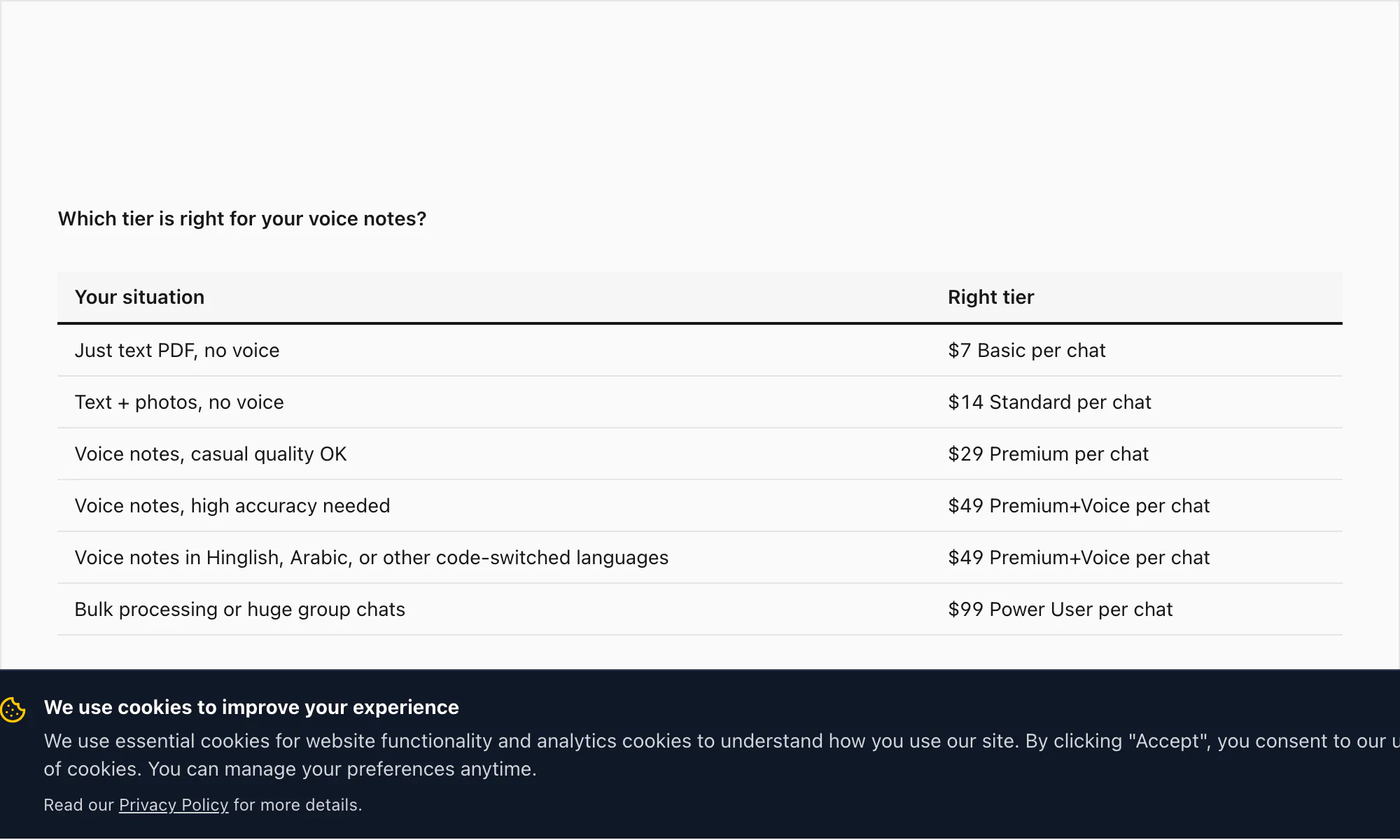
Como referencia, el conjunto completo de niveles: conversión $7 Basic por chat (solo texto, límite de 5.000 mensajes), conversión $14 Standard por chat (imágenes, límite de 25.000 mensajes), conversión $29 Premium por chat (sin límite, XLSX/CSV, notas de voz como marcadores), conversión $49 Premium+Voice por chat (transcripción Nova-3, 17 idiomas de alta precisión, límite de 8 horas de audio), conversión $99 Power User por chat (transcripción Nova-3, sin límite de audio, cola prioritaria, escenarios masivos).
Por qué no transcribo en tiempo real (y no lo añadiré)
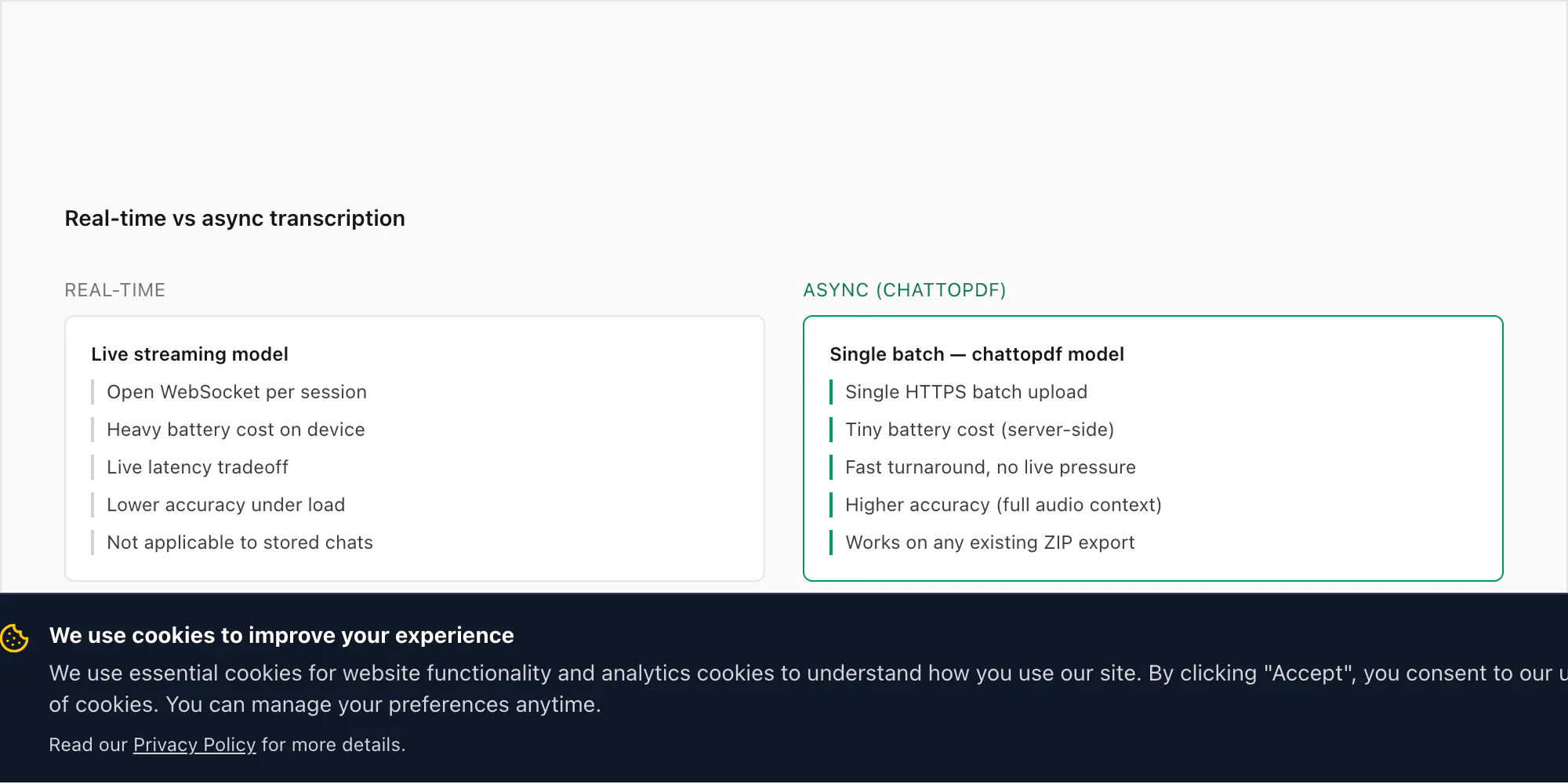
Esto surge con suficiente frecuencia como para merecer una respuesta directa. La gente pregunta por qué ChatToPDF no escucha las notas de voz a medida que llegan — transcribiendo cada una en el momento en que se envía — en lugar de requerir una exportación ZIP después del hecho.
La versión corta: WhatsApp no da a los desarrolladores acceso a mensajes entrantes o audio en tiempo real. No hay ningún punto de acceso de la API oficial de WhatsApp Business que exponga las notas de voz a medida que llegan. El único acceso de terceros admitido es a través del mecanismo Exportar chat, que es una instantánea puntual del historial de conversación. Construir la transcripción en tiempo real sobre WhatsApp requeriría interceptar el almacenamiento local de la app en el dispositivo, lo que es tanto técnicamente frágil como contrario a las políticas de plataforma de WhatsApp.
Pero hay una razón más práctica por la que no he intentado construir alrededor de esa limitación. El caso de uso para transcribir WhatsApp audio es casi en su totalidad retrospectivo. Alguien recibe treinta notas de voz a lo largo de una disputa y quiere un registro legible. Un equipo empresarial usa notas de voz para actualizaciones del proyecto y necesita que sean buscables. Una familia se manda notas de voz durante años y quiere archivarlas antes de cambiar de teléfono. Ninguno de estos implica un requisito de "ahora mismo, a medida que llega". Todos son "tengo un conjunto de grabaciones que necesito convertir".
El procesamiento asíncrono por lotes también es más preciso. El reconocimiento de voz en tiempo real opera bajo restricciones de latencia que impulsan al modelo hacia una inferencia más rápida (y menos precisa). El modo por lotes de Deepgram se ejecuta sobre el archivo de audio completo, lo que permite al modelo usar el contexto futuro — qué vino después de una palabra — para resolver fonemas ambiguos. En una nota de voz de 30 segundos, la diferencia en TDE entre los modos en tiempo real y por lotes puede ser de 2-4 puntos porcentuales. Eso es significativo en la escala de precisión.
También está la cuestión de la batería y la red. Ejecutar una conexión WebSocket abierta que transmita fragmentos de audio a una API de inferencia en tiempo real consumiría batería del teléfono de forma notable durante una conversación larga. Requeriría una conexión a internet activa para cada nota de voz recibida, no solo cuando eliges convertir. Y crearía un flujo de datos continuo de tus conversaciones a un servidor de terceros — algo que no estoy cómodo pidiendo a los usuarios que acepten.
El modelo de exportación y subida es más lento en tiempo de reloj — tienes que esperar hasta que estés listo para convertir, luego hacer la exportación, luego subirla. Pero para los casos de uso reales que tiene la gente, eso está bien. Nadie intenta transcribir una nota de voz que recibió hace tres segundos para un documento en tiempo real. Están convirtiendo un chat que quieren conservar.
Privacidad: adónde va tu audio y adónde no
Quiero ser específico en esta parte porque la naturaleza de las notas de voz — grabaciones de audio de conversaciones reales — significa que las implicaciones para la privacidad son mayores que con solo mensajes de texto.
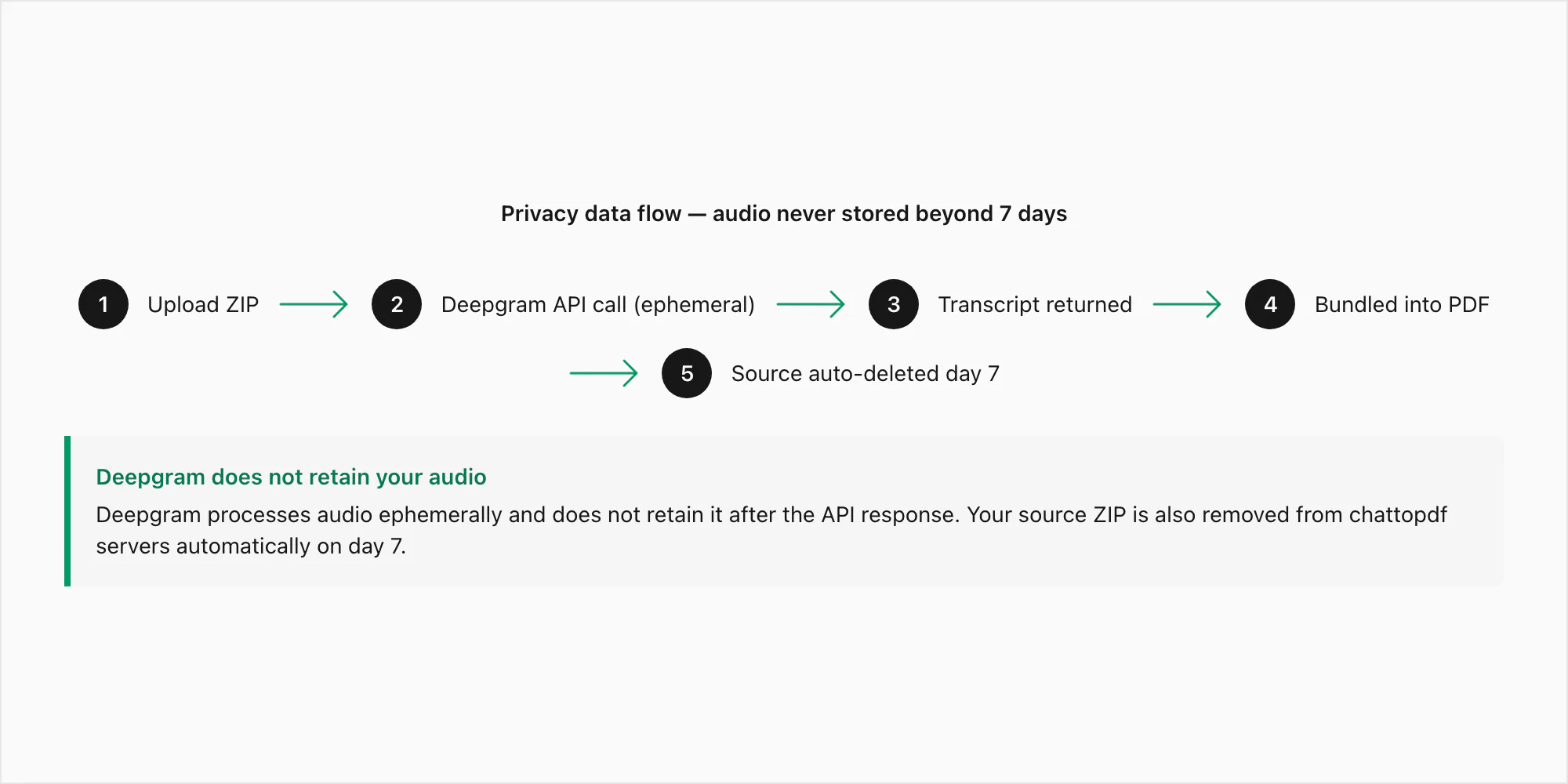
Este es el flujo exacto de datos para una nota de voz enviada a través de la conversión $49 Premium+Voice por chat:
Paso 1 — Subida. Tu archivo ZIP se transmite desde tu navegador al servidor de ChatToPDF por HTTPS (TLS 1.3). La conexión está cifrada en tránsito. El ZIP llega a un directorio de procesamiento temporal, no al almacenamiento permanente, mientras se ejecuta la extracción.
Paso 2 — Extracción. Los archivos .opus se extraen del ZIP. Cada archivo se empareja con su referencia en _chat.txt mediante el patrón del nombre del archivo. En este punto, los archivos de audio solo existen en el servidor de procesamiento de ChatToPDF.
Paso 3 — Llamada a la API de Deepgram. Cada archivo .opus se envía a la API de inferencia de Deepgram mediante una llamada HTTPS autenticada. Este es el único momento en que los bytes de audio salen de la propia infraestructura de ChatToPDF. La política de datos de Deepgram para envíos de API especifica que el audio enviado mediante API se procesa de forma efímera — se usa para generar la transcripción y luego se descarta. Deepgram no retiene el audio enviado por API y no lo usa para el entrenamiento de modelos. Lo que regresa es el texto de la transcripción.
Paso 4 — Almacenamiento. La transcripción se empaqueta en el PDF y se almacena cifrada en reposo (AES-256) en AWS S3. El ZIP fuente, incluidos los archivos .opus, también se almacena cifrado durante siete días.
Paso 5 — Entrega. El enlace de descarga del PDF aparece en pantalla y en tu correo electrónico. El enlace está vinculado a tu ID de trabajo. No es adivinable y no está indexado en ningún lugar.
Paso 6 — Eliminación automática. Siete días después de que se crea el trabajo, el ZIP fuente y el PDF resultante se eliminan del almacenamiento automáticamente. Este es un trabajo de eliminación programado, no un proceso manual. No hay excepciones ni extensiones.
Adónde no va tu audio: no va a ninguna plataforma de análisis. No se usa para entrenar los modelos de ChatToPDF (ChatToPDF no entrena modelos). El contenido de texto de tus notas de voz no es visible para el personal de ChatToPDF — el procesamiento es completamente automatizado. Ningún tercero recibe el texto de tus mensajes de chat.
La única posible laguna en esta descripción es el paso de Deepgram. Puedo controlar completamente lo que ocurre en los servidores de ChatToPDF. No puedo hacer afirmaciones sobre los procesos internos de Deepgram más allá de lo que dice su política de datos pública. Si tus notas de voz contienen información legalmente privilegiada o genuinamente clasificada, te recomendaría que tu equipo legal revisara los términos de procesamiento de datos empresariales de Deepgram antes de subir. Para la gran mayoría de los casos de uso — conversaciones personales, chats de equipos empresariales, archivos de notas de voz familiares — el flujo estándar es apropiado.
Casos extremos: ruido de fondo, varios hablantes, efectos de voz
Las notas de voz reales de WhatsApp no se graban en estudios insonorizados. Se graban en coches, cocinas, reuniones en la calle y cafés ruidosos. Así afecta cada uno de esos escenarios a la precisión de la transcripción, y qué hace ChatToPDF cuando la precisión cae a un nivel inaceptable.
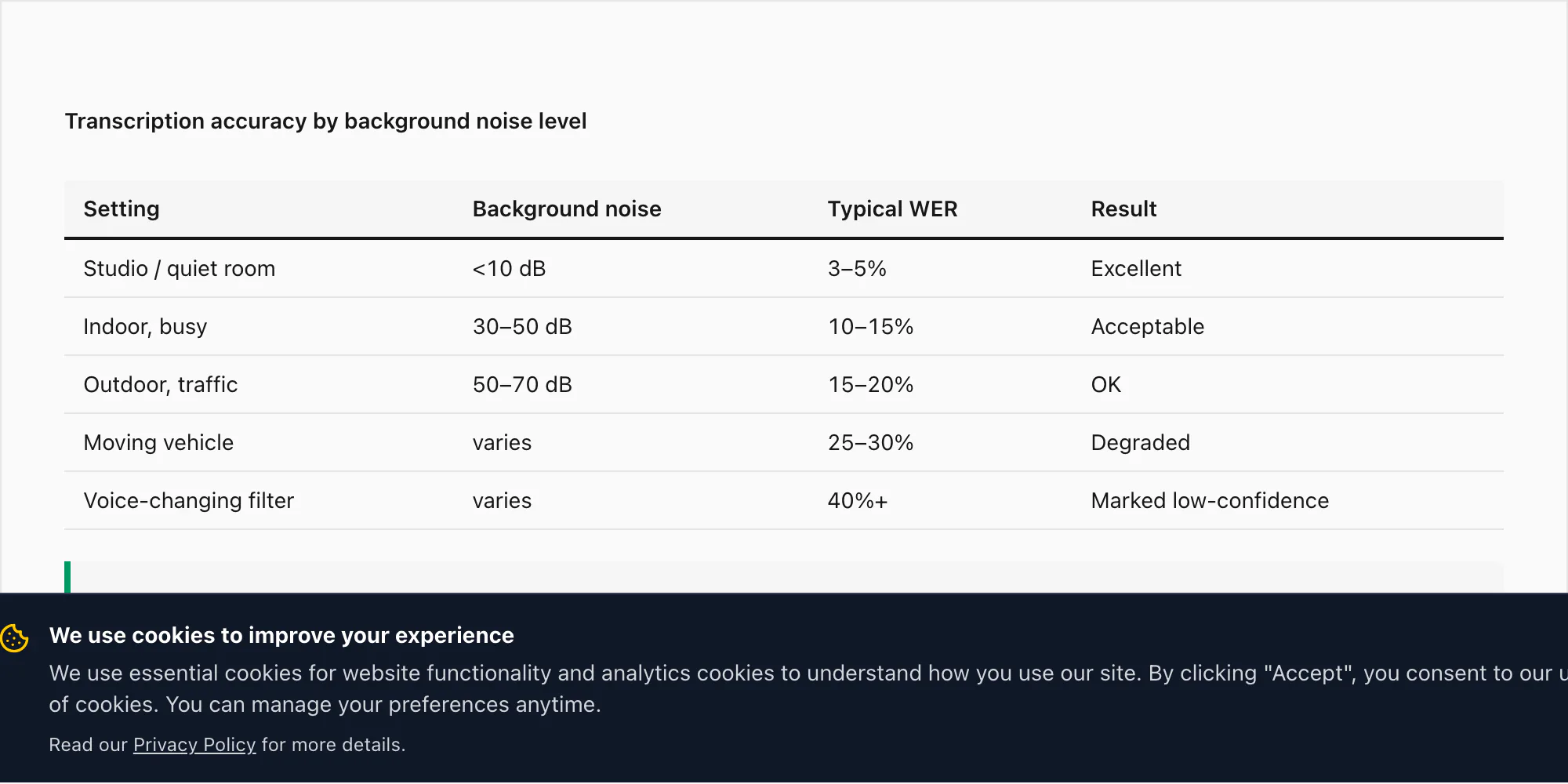
Ruido de fondo según el entorno.
Una nota de voz grabada en un entorno interior tranquilo — una oficina, un dormitorio, una habitación en silencio — funciona a las tasas de precisión que cité en la sección de idiomas: TDE del 3-5% en la conversión $49 Premium+Voice por chat para los 17 idiomas de alta precisión.
Una nota de voz de un entorno interior concurrido (un restaurante, un mercado, una oficina animada) puede ver la TDE subir al 10-15% en la conversión $49 Premium+Voice por chat. Nova-3 de Deepgram aplica cancelación de ruido durante la inferencia, lo que ayuda, pero no elimina el efecto del audio competidor.
Una grabación exterior — ruido de calle, viento, tráfico — puede llevar la TDE al 15-20% para el mismo nivel.
Una nota de voz grabada durante un viaje en vehículo en movimiento, con ruido de carretera y motor, es el escenario individual más desafiante que he probado. La TDE en estos casos puede alcanzar el 25-30% incluso con Nova-3. Esto no es una limitación del motor de transcripción — refleja la física del audio capturado en el micrófono de un teléfono a 16 kHz en un entorno ruidoso. La calidad del audio de entrada determina la calidad de la transcripción de salida.
Varios hablantes dentro de una sola nota de voz.
Como expliqué antes, cada nota de voz de WhatsApp pertenece a un remitente — la persona que pulsó el botón push-to-talk. ChatToPDF atribuye la transcripción a ese remitente. El problema aparece cuando el remitente graba mientras otra persona habla audiblemente de fondo (una conversación telefónica que el remitente está teniendo, un televisor sonando de fondo con voz, otra persona en la misma habitación hablando en voz alta): en ese caso, Deepgram también transcribirá la voz de fondo — no la descarta silenciosamente. La transcripción intercalará ambas voces, atribuidas al remitente de WhatsApp. Esto puede producir una salida confusa cuando el habla de fondo es lo suficientemente inteligible como para transcribirse.
ChatToPDF actualmente no puede aislar al hablante principal y descartar las voces de fondo dentro de un único clip .opus. La diarización de hablantes — identificar qué segmentos de audio provinieron de qué persona en el mismo archivo de audio — es una función que estoy evaluando para un nivel futuro, pero requiere infraestructura adicional y no está en la versión actual.
Efectos de cambio de voz.
Algunos usuarios de WhatsApp envían notas de voz con efectos de audio aplicados — el filtro de voz grave disponible en el propio WhatsApp (Android), cambios de voz al estilo Snapchat antes de compartir, o simplemente audio que ha sido alterado de tono o con reverberación antes de enviarse. El modelo de Deepgram está entrenado con habla natural. El audio modificado puede llevar la TDE por encima del 40% en casos extremos — una nota de voz enviada a través de un filtro de graves para hacer sonar a alguien como un robot en su mayor parte no se transcribirá.
Para los clips donde la confianza cae por debajo del umbral que he establecido en el flujo — actualmente definido como una puntuación de confianza de palabras promedio inferior a 0,6 en todo el clip — ChatToPDF marca la transcripción en el PDF como [transcripción de baja confianza — calidad de audio insuficiente] en lugar de producir un bloque de texto que podría tomarse como autorizado. Verás este marcador en el PDF final junto a la posición de la nota de voz en la conversación. Es mejor señalar un resultado incierto que devolver una transcripción de aspecto plausible que sea un 40% incorrecta.
Preguntas frecuentes
¿Qué formato de archivo usan las notas de voz de WhatsApp y lo gestiona ChatToPDF?
WhatsApp graba notas de voz usando el códec de audio Opus a 16 kHz mono, guardadas como archivos .opus. ChatToPDF extrae los archivos .opus directamente del ZIP de exportación de WhatsApp y los envía a la API de inferencia de Deepgram en su formato nativo — no se requiere ningún paso de recodificación. Las exportaciones de iPhone y Android producen archivos .opus, por lo que el manejo del formato es el mismo en ambas plataformas.
¿Qué precisión tiene la transcripción de audio de WhatsApp?
La precisión depende del nivel y la calidad del audio. La conversión $49 Premium+Voice por chat usa Deepgram Nova-3, que logra aproximadamente un 3-5% de tasa de error de palabras en audio limpio y sin ruido en los 17 idiomas de alta precisión compatibles. La conversión $99 Power User por chat usa el mismo modelo Nova-3 sin límite de audio y con procesamiento en cola prioritaria. La conversión $29 Premium por chat no transcribe — conserva las notas de voz como referencias de marcador en el PDF. El ruido de fondo, los acentos y el cambio de código entre idiomas afectan la precisión en los niveles con transcripción. Marqué los clips de baja confianza (por debajo de una puntuación de confianza de palabras promedio de 0,6) como [transcripción de baja confianza] en el PDF en lugar de presentar una transcripción potencialmente engañosa.
¿Transcribe ChatToPDF notas de voz en idiomas distintos al inglés?
Sí. La conversión $49 Premium+Voice por chat y la conversión $99 Power User por chat admiten 17 idiomas de alta precisión: inglés, español, portugués, francés, alemán, italiano, árabe, hindi, indonesio, turco, ruso, neerlandés, japonés, coreano, chino, vietnamita y tailandés. Ambos niveles usan Deepgram Nova-3 en estos idiomas y detectan más de 30 idiomas adicionales con un rango de precisión más amplio. El idioma se detecta automáticamente — no necesitas especificarlo antes de subir. La conversión $29 Premium por chat no transcribe notas de voz — las conserva como referencias de marcador en el PDF.
¿Necesito hacer algo diferente al exportar desde WhatsApp si quiero transcripciones de voz?
Sí — un paso crítico. Cuando exportas tu chat desde WhatsApp, elige "Incluir archivos multimedia" en lugar de "Sin archivos multimedia". Las notas de voz (archivos .opus) solo se incluyen en la exportación cuando seleccionas Incluir archivos multimedia. Si exportas Sin archivos multimedia, el _chat.txt contendrá referencias como <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> pero sin archivos de audio reales. ChatToPDF no puede transcribir una nota de voz que no tiene. Consulta la guía de exportación de chat de WhatsApp para el proceso completo de exportación paso a paso.
¿Aparecerán las transcripciones de voz en el lugar correcto del PDF?
Sí. ChatToPDF lee el registro de mensajes en _chat.txt para entender la estructura de la conversación, empareja cada referencia .opus con el archivo de audio correspondiente por nombre de archivo e inserta la transcripción en la posición exacta de la conversación donde se envió la nota de voz. El nombre del remitente de los metadatos de WhatsApp y la marca de tiempo original aparecen junto a la transcripción. La salida es un único documento donde los mensajes de texto y las transcripciones de notas de voz se alternan en el orden cronológico correcto.
¿Qué ocurre con mis archivos de audio una vez completada la transcripción?
Tus archivos de audio se almacenan cifrados en reposo (AES-256) en los servidores de ChatToPDF durante siete días después de que se crea el trabajo, luego se eliminan automáticamente. El único servicio de terceros que recibe los bytes de audio es Deepgram, y solo durante el paso de transcripción — Deepgram procesa el audio enviado por API de forma efímera y no lo retiene. Ninguna persona escucha tus grabaciones. Las transcripciones se eliminan junto con los archivos fuente en el período de siete días. Para más detalles sobre el flujo de datos completo, consulta la sección de privacidad de WhatsApp a PDF.
¿Puede ChatToPDF distinguir a dos personas diferentes hablando en la misma nota de voz?
Actualmente no. Cada nota de voz de WhatsApp se atribuye a la persona que la envió, usando la información del remitente de _chat.txt. Dentro de una sola nota de voz, si el remitente y otra persona hablan (por ejemplo, el remitente está teniendo una conversación telefónica mientras graba), ambas voces se transcriben pero se atribuyen al remitente de WhatsApp. ChatToPDF actualmente no ejecuta diarización de hablantes dentro de clips de audio individuales. Para notas de voz donde las voces de fondo son audibles e inteligibles, podrías ver habla intercalada en la transcripción.
Key takeaways
- Para transcribir WhatsApp audio, exporta tu chat con "Incluir archivos multimedia" seleccionado — los archivos de notas de voz
.opusdeben estar dentro del ZIP - La conversión $29 Premium por chat no transcribe — conserva las notas de voz como referencias de marcador; la conversión $49 Premium+Voice por chat ejecuta Deepgram Nova-3 (TDE del 3-5% en audio limpio, 17 idiomas de alta precisión, hasta 8 horas de audio); la conversión $99 Power User por chat usa el mismo modelo sin límite y con cola prioritaria
- Cada transcripción se inserta en la posición exacta de la conversación con el nombre del remitente de WhatsApp y la marca de tiempo original preservados
- Los idiomas con cambio de código como el hinglish requieren la conversión $49 Premium+Voice por chat o superior — Nova-3 cierra la mayor parte de la brecha que los motores STT anteriores dejaban en las inserciones en inglés a mitad de frase en notas de voz en hindi
- El ruido de fondo es la mayor variable de precisión: las condiciones de estudio producen una TDE del 3-5%; las grabaciones en exteriores o en vehículos pueden llegar al 20-30% incluso con Nova-3
- El audio enviado a Deepgram para la transcripción se procesa de forma efímera — no se retiene ni se usa para entrenamiento; los archivos fuente se eliminan automáticamente de los servidores de ChatToPDF después de 7 días
- Los clips donde la confianza de palabras promedio cae por debajo de 0,6 se marcan como
[transcripción de baja confianza]en el PDF en lugar de devolver silenciosamente una transcripción potencialmente incorrecta
Para el flujo completo de chat a PDF — incluyendo cómo exportar en iPhone y Android, qué contiene el ZIP y cómo se comparan los cinco niveles para conversiones sin voz — consulta la guía de WhatsApp a PDF. Si estás en Android y necesitas mover la exportación a otro dispositivo antes de subirla, la guía de transferencia de WhatsApp Android a iPhone cubre ese proceso.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).