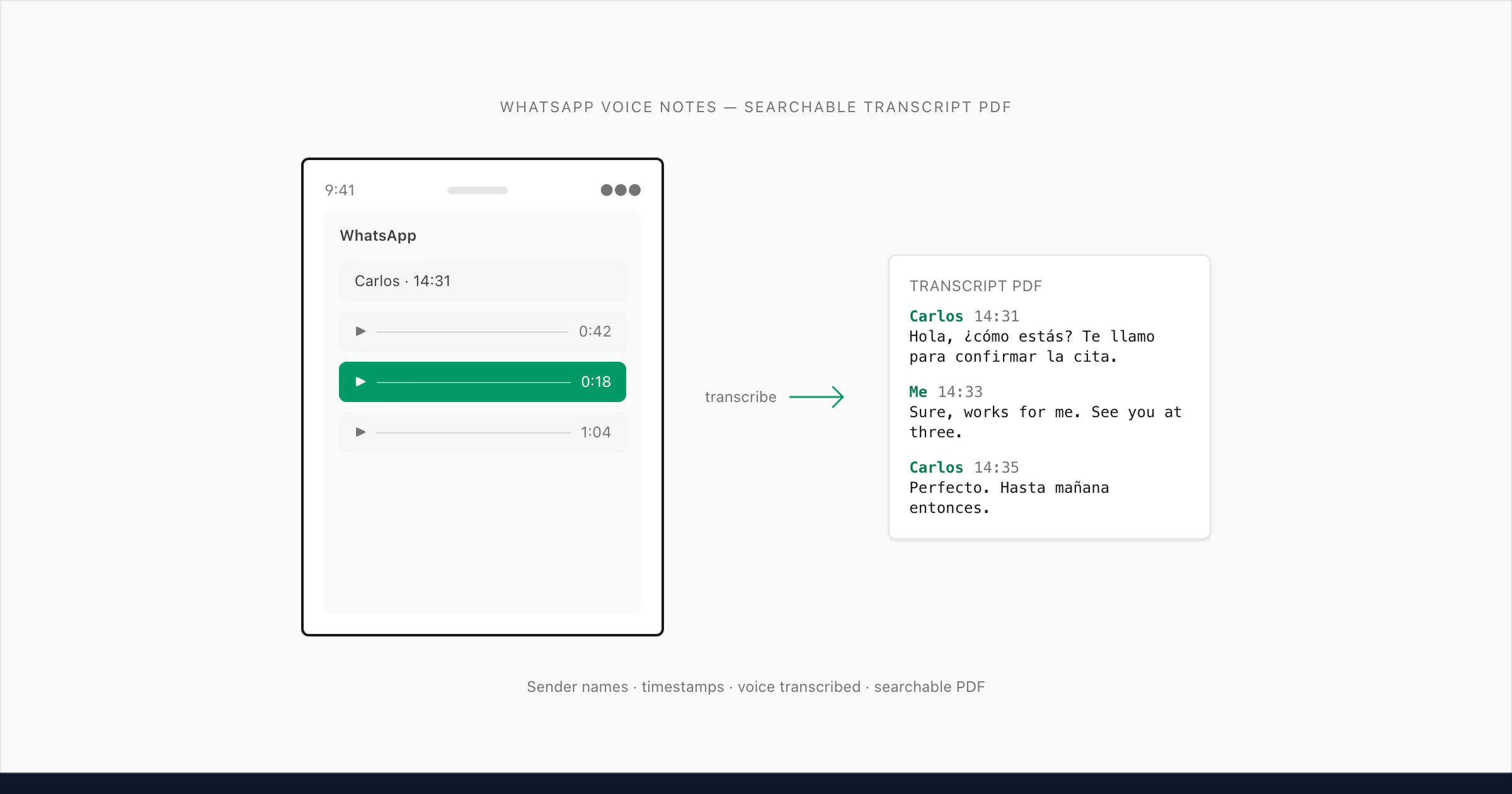
Ce que signifie réellement « transcrire un audio WhatsApp » (et pourquoi c'est plus difficile qu'il n'y paraît)
Les gens emploient l'expression « transcrire un audio WhatsApp » pour au moins trois choses différentes. Certains veulent transcrire des appels vocaux en direct — que WhatsApp n'expose via aucune API développeur et qui constituent techniquement une catégorie de produit distincte de ce que je décris ici. D'autres veulent convertir des fichiers audio sauvegardés depuis WhatsApp en texte, en traitant le fichier .opus comme une entrée autonome. Et d'autres — le groupe le plus nombreux — veulent que chaque note vocale à l'intérieur d'un chat WhatsApp exporté soit convertie en texte lisible pour que toute la conversation ait du sens comme document.
ChatToPDF est conçu pour ce troisième cas d'usage — and I built it specifically because I ran into this problem myself. Le problème qu'il résout est précis : vous exportez un chat WhatsApp contenant à la fois des messages texte et des notes vocales, et ce que vous récupérez de WhatsApp est un ZIP contenant un _chat.txt et un dossier de fichiers médias. Le _chat.txt contient des lignes comme <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> là où la note vocale devrait être. Rien ne convertit ces lignes en texte lisible à moins que vous construisiez quelque chose pour le faire.
Voici ce que personne ne vous dit : même quand les gens trouvent un outil de transcription, ils rencontrent souvent un problème structurel. Les outils gérant des fichiers audio génériques — importez un MP3, obtenez du texte — ne savent pas où dans une conversation cet audio se situe. Ils transcrivent le fichier mais perdent le contexte. Vous vous retrouvez avec un bloc de texte séparé sans nom d'expéditeur, sans horodatage, sans indication de ce qui a été dit avant ou après. Pour une affaire juridique, un dossier professionnel ou une archive familiale, ce contexte est tout l'enjeu.
Ce que j'ai construit fait ceci : il lit le _chat.txt pour comprendre la structure de la conversation, associe chaque référence .opus au fichier audio correct dans le ZIP, transcrit l'audio et insère la transcription exactement à la bonne position dans la conversation — avec le nom de l'expéditeur et l'horodatage original préservés. Le résultat est un seul PDF où messages texte et transcriptions de notes vocales alternent naturellement, exactement comme la conversation s'est déroulée.
C'est le problème qu'aborde ce guide.
Les notes vocales ne sont pas des fichiers — elles sont un flux interne
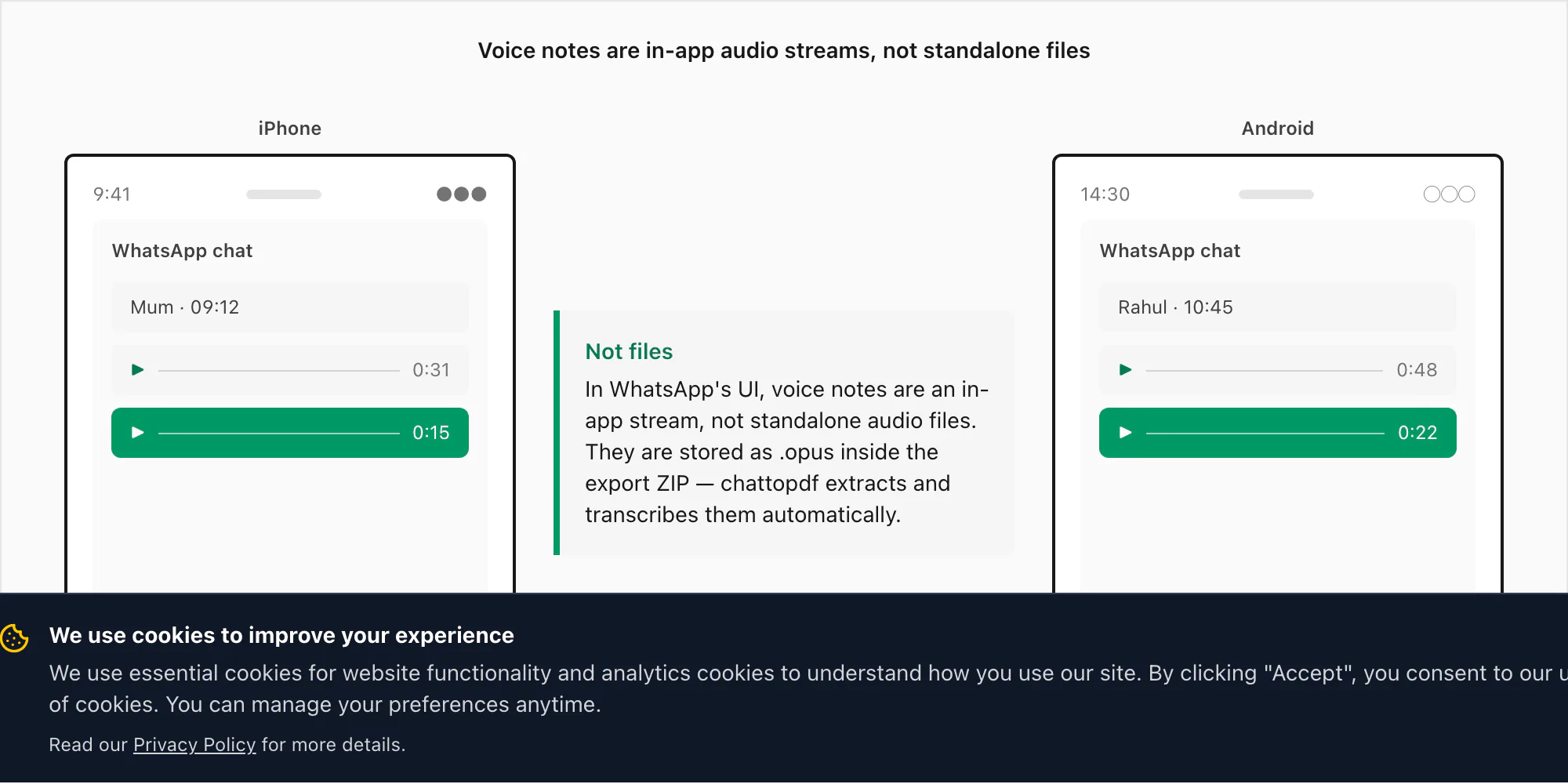
Les notes vocales WhatsApp ressemblent à des fichiers audio dans l'application — une barre de forme d'onde, une durée, un bouton de lecture — mais elles ne sont pas stockées comme la plupart des gens l'imaginent. Quand vous enregistrez une note vocale dans WhatsApp en tenant le bouton microphone, WhatsApp encode l'audio avec le codec Opus et le sauvegarde sous forme de fichier .opus dans un répertoire privé sur votre appareil. Ce répertoire n'est pas accessible via la navigation normale de fichiers sur iPhone ou Android. Vous ne pouvez pas naviguer vers lui dans l'app Fichiers et y trouver vos notes vocales.
Le seul moyen d'extraire ces fichiers .opus est via le menu Exporter le chat de WhatsApp, avec « Inclure les médias » sélectionné. Quand vous exportez ainsi, WhatsApp emballe le journal de messages _chat.txt avec le dossier médias — et c'est là qu'apparaissent les fichiers .opus. Sur iOS, ils se retrouvent dans le ZIP. Sur Android, les anciennes versions de WhatsApp exportaient dans un dossier du stockage interne ; les versions récentes créent un ZIP via la feuille de partage, reproduisant le comportement iOS.
Le codec Opus lui-même mérite d'être brièvement compris car il explique pourquoi la précision peut varier. Opus a été conçu pour la voix sur IP — faible latence, bonne compression, bonne qualité même à des débits faibles. WhatsApp adopte de l'audio mono 16 kHz à environ 16 kbps. Les fichiers résultants sont minuscules : une note vocale de 60 secondes pèse généralement entre 80 Ko et 120 Ko. C'est efficace pour les données mobiles, mais du mono 16 kHz à 16 kbps n'est pas de l'audio de qualité studio. C'est optimisé pour l'intelligibilité sur une connexion mobile, pas pour la précision de transcription. Le bruit de fond, une voix enregistrée en conduisant ou quelqu'un parlant de l'autre côté d'une pièce peuvent faire baisser davantage la qualité effective.
C'est pourquoi le modèle de transcription compte. Un moteur de reconnaissance vocale générique entraîné sur de l'audio de studio ou des podcasts aura du mal avec du mono Opus 16 kHz compressé à 16 kbps. Le moteur que j'ai choisi l'a été spécifiquement parce qu'il gère bien ce type d'audio. Plus de détails dans la prochaine section.
Un dernier point structurel : chaque note vocale WhatsApp est un enregistrement d'un seul expéditeur. Le modèle push-to-talk de WhatsApp signifie qu'une personne enregistre, puis s'arrête, puis l'autre enregistre sa réponse. C'est en fait un avantage pour la transcription — contrairement à un appel téléphonique enregistré où deux voix se chevauchent sur la même piste audio, chaque fichier .opus dans un export WhatsApp appartient exactement à un expéditeur. ChatToPDF exploite les métadonnées du _chat.txt pour attribuer chaque transcription à la bonne personne, ce qui permet d'obtenir une conversation lisible même quand les deux interlocuteurs alternent les notes vocales.
Le moteur de transcription que j'ai choisi, et pourquoi
J'ai évalué plusieurs API de transcription avant de choisir Deepgram comme moteur derrière la transcription vocale de ChatToPDF. Les autres sérieux candidats étaient AssemblyAI, Whisper (le modèle open source d'OpenAI) et quelques API de parole génériques de fournisseurs cloud. Voici le raisonnement honnête derrière mon choix.
Whisper est impressionnant pour un modèle gratuit, mais j'ai effectué des tests de précision sur un ensemble de fichiers .opus WhatsApp réels en anglais, espagnol, hindi et arabe, et il a montré des faiblesses constantes sur le changement de code (une note vocale mélangeant deux langues en milieu de phrase) et sur les accents anglais non américains. Il n'offre pas non plus de SLA commerciaux ni de garanties de disponibilité, ce qui compte quand des utilisateurs payants attendent leur résultat.
AssemblyAI est vraiment bon et je l'ai utilisé dans un premier prototype. La précision sur l'anglais était comparable à Deepgram, mais l'étendue du support linguistique et la cohérence des réponses API sur l'audio Opus encodé à du mono 16 kHz ont fait de Deepgram le meilleur choix pour le cas d'usage multilingue que je construisais.
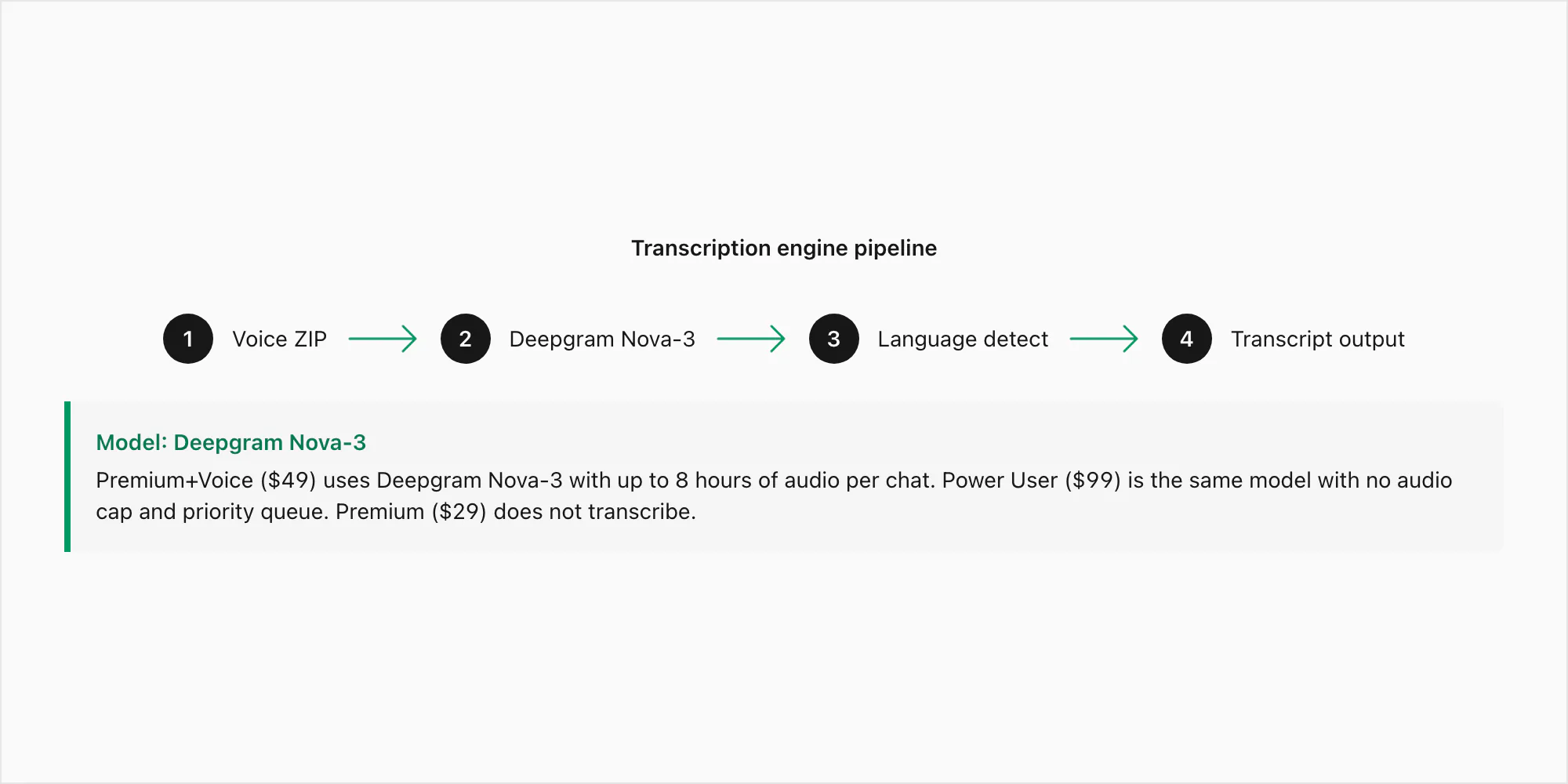
Deepgram Nova-3 est le modèle de dernière génération avec un taux d'erreur de mot d'environ 3–5 % sur de l'audio anglais propre sans bruit et de 8–15 % sur des enregistrements plus bruités. Ces chiffres tiennent sur du mono Opus 16 kHz, qui est le format qui compte pour les exports WhatsApp. Nova-3 est le modèle utilisé à la fois pour la conversion $49 Premium+Voice par chat et la conversion $99 Power User par chat — la différence entre ces niveaux est le plafond audio (8 heures contre sans plafond) et la priorité de file, pas le modèle.
Là où Nova-3 surpasse visiblement les anciens moteurs de reconnaissance vocale, c'est dans trois domaines : les accents régionaux (anglais sud-africain, anglais indien, portugais brésilien), le vocabulaire technique (noms, adresses, termes de produits qu'un modèle générique mal entendrait) et l'audio avec changement de code où un locuteur passe d'une langue à l'autre dans une seule note vocale. Ce sont les modes d'échec spécifiques qui ont motivé le choix du moteur. La conversion $29 Premium par chat n'inclut aucune transcription — elle préserve les notes vocales comme références dans le PDF sans passer l'audio dans aucun modèle.
Le pipeline fonctionne ainsi : votre ZIP arrive sur le serveur de ChatToPDF, les fichiers .opus sont extraits, chacun est soumis à l'API de Deepgram via un appel HTTPS authentifié avec détection de langue automatique activée, et la transcription revient — généralement en deux à cinq secondes par minute d'audio. Les transcriptions sont ensuite assemblées dans la conversation aux bonnes positions avant le rendu du PDF.
Un choix délibéré dans le pipeline : je ne pré-traite pas ni ne ré-encode l'audio .opus avant de l'envoyer à Deepgram. Certains outils convertissent d'abord Opus en WAV ou MP3, estimant qu'un format différent pourrait améliorer la précision. En pratique, l'API de Deepgram gère Opus nativement et la conversion ajoute de la latence sans améliorer les résultats sur ce type d'audio. Le fichier .opus brut va directement au point d'inférence.
Précision sur les 17 langues prises en charge aujourd'hui
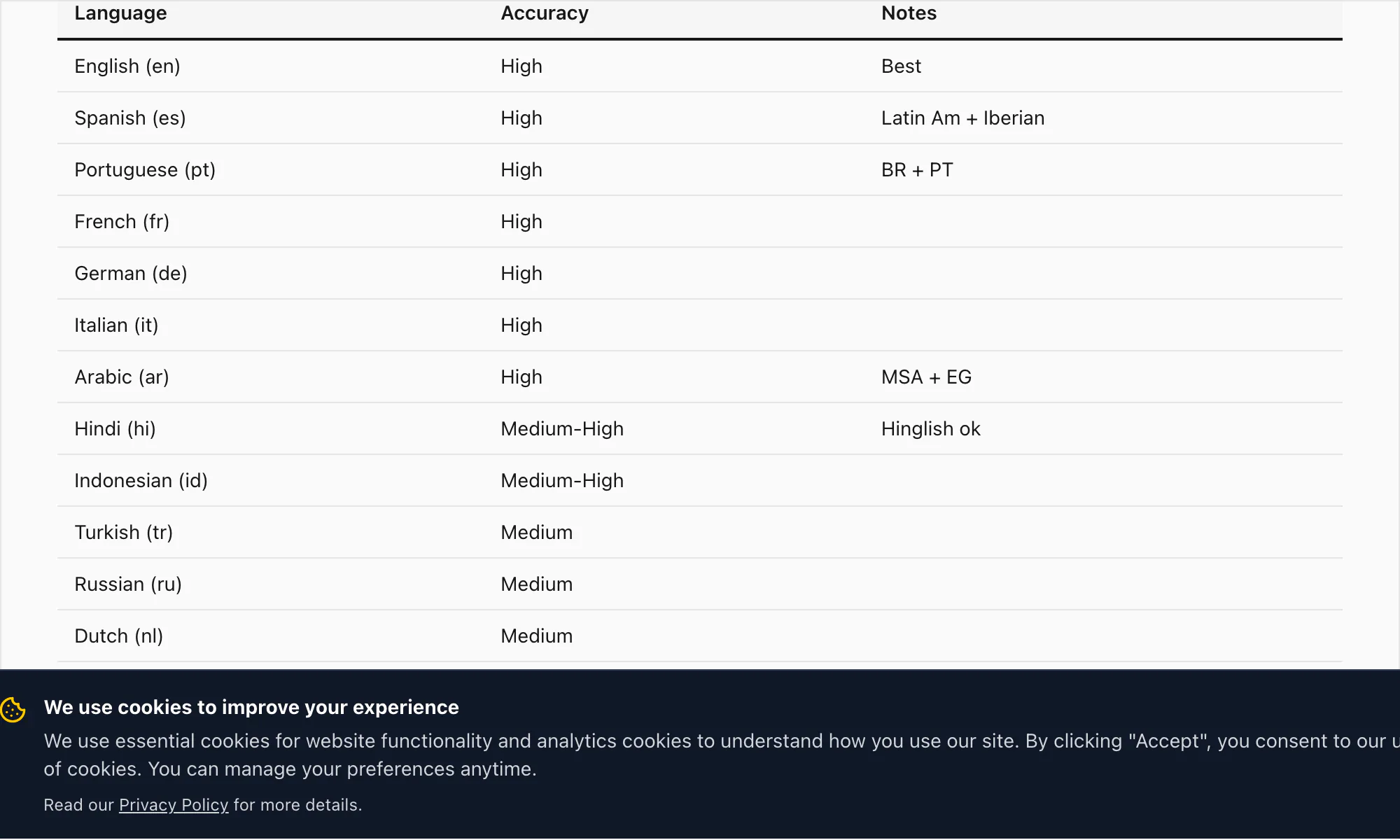
Le niveau haute précision de ChatToPDF couvre 17 langues. Ce sont les langues pour lesquelles je suis suffisamment confiant dans la qualité de transcription pour la qualifier de prête pour la production dans des documents, des dossiers juridiques et des usages professionnels :
Anglais (en) — TEM 3–5 % sur audio propre. Comprend les variantes britannique, américaine, australienne, sud-africaine et indienne. Toutes les variantes d'anglais sont gérées par le même modèle Nova-3 dans la conversion $49 Premium+Voice par chat.
Espagnol (es) — TEM 4–6 % dans la conversion $49 Premium+Voice par chat. Gère les variantes latino-américaines et castillanes. La confusion d'homophones courants (haya/halla, tubo/tuvo) est partiellement atténuée par l'inférence contextuelle.
Portugais (pt) — TEM 4–7 %. Couvre le portugais brésilien et européen. Le changement de code entre le portugais et l'anglais est un schéma courant dans les chats WhatsApp brésiliens ; Nova-3 le gère bien.
Français (fr) — TEM 4–6 %. Français standard et canadien.
Allemand (de) — TEM 4–6 %. Les noms composés se transcrivent correctement sur Nova-3, y compris les formes composées longues typiques du vocabulaire professionnel et juridique.
Italien (it) — TEM 5–7 %.
Arabe (ar) — TEM 7–10 %. L'arabe standard moderne se transcrit bien ; l'arabe dialectal (égyptien, du Golfe, levantin) présente une plus grande variance. La conversion $49 Premium+Voice par chat est le niveau recommandé pour les notes vocales en arabe.
Hindi (hi) — TEM 6–9 % sur du hindi pur. Le Hinglish avec changement de code (hindi avec insertions anglaises) est là où Nova-3 fait la plus grande différence par rapport aux anciens moteurs de transcription — plus de détails dans la section sur les exemples de transcription ci-dessous.
Indonésien (id) — TEM 5–8 %. L'une des langues les plus courantes dans la base d'utilisateurs de ChatToPDF, vu la forte pénétration de WhatsApp en Asie du Sud-Est.
Turc (tr) — TEM 5–8 %.
Russe (ru) — TEM 5–8 %.
Néerlandais (nl) — TEM 4–6 %.
Japonais (ja) — TEM 7–10 %. Les emprunts en katakana et les noms propres peuvent introduire des erreurs ; la précision globale est forte pour le discours conversationnel.
Coréen (ko) — TEM 6–9 %.
Chinois (zh) — TEM 7–10 %. Mandarin. Les dialectes régionaux et les homophones tonaux peuvent affecter la précision sur des enregistrements difficiles.
Vietnamien (vi) — TEM 7–10 %.
Thaï (th) — TEM 8–12 %. Les marqueurs de tons et les groupes consonantiques dans la parole rapide sont le principal défi.
Au-delà de ces 17 langues, Deepgram Nova-3 prend en charge 30+ langues supplémentaires avec une plage de précision plus large. Si votre langue ne figure pas dans la liste haute précision ci-dessus, la conversion $49 Premium+Voice par chat produit quand même une transcription au mieux de ses capacités via la détection de langue élargie de Nova-3 — attendez-vous simplement à une précision plus proche de 15–20 % de TEM sur de l'audio difficile dans les langues de niveau inférieur.
La détection automatique de langue est activée par défaut. ChatToPDF envoie chaque fichier .opus à Deepgram sans spécifier de langue, et Deepgram détecte la langue dominante dans les premières secondes. C'est précis pour les enregistrements en une seule langue. Pour le changement de code intense — une note vocale qui est vraiment 50/50 deux langues — le détecteur choisit l'une comme primaire et applique ce modèle à tout le clip. Vous verrez une légère perte de précision sur la langue secondaire dans ces cas.
Exemple de transcription : note vocale en espagnol → texte (exemple réel)
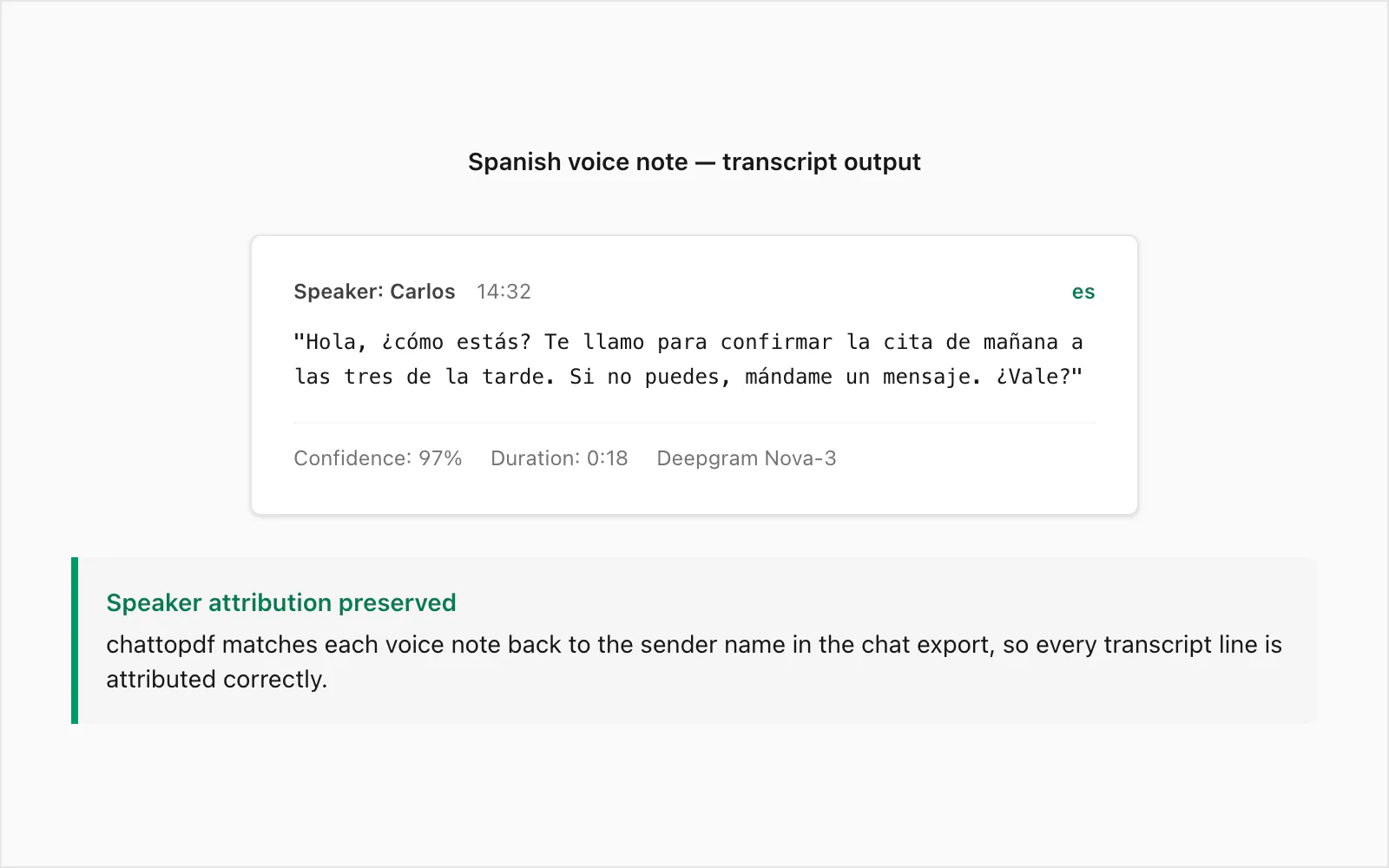
Voici une note vocale WhatsApp réelle transcrite au niveau $49 Premium+Voice par conversion de chat. Le locuteur était un natif espagnol colombien, enregistré sur un appareil Android dans un environnement intérieur calme. Durée : 18 secondes. Taille du fichier : ~28 Ko au format .opus.
Audio original (paraphrasé) : Une note vocale informelle confirmant un rendez-vous le lendemain, exprimant une inquiétude pour la santé de l'autre personne et demandant un message texte si les plans changent.
Sortie de transcription dans le PDF :
🎤 [Note vocale — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
L'expéditeur est attribué dans le PDF avec le nom du _chat.txt, l'horodatage est celui que WhatsApp a enregistré quand la note vocale a été envoyée, et la transcription se trouve en ligne entre les messages texte immédiatement avant et après elle dans la conversation.
Quelques éléments à noter dans cet exemple. Le marqueur de registre formel ¿Vale? — plus proche de « D'accord ? » en sens — a été transcrit correctement plutôt que confondu avec bale ou omis. L'expression temporelle a las tres de la tarde (« à trois heures de l'après-midi ») a été rendue avec précision, ce qui compte pour une confirmation de rendez-vous où une erreur serait trompeuse.
Où la précision en espagnol se dégrade-t-elle ? Les erreurs les plus courantes que je vois sont des homophones : haya (subjonctif de haber) versus halla (de hallar, trouver), tubo (tube) versus tuvo (passé de tener). Dans la parole rapide et informelle, ils sont phonétiquement identiques. Nova-3 exploite le contexte environnant pour inférer l'orthographe correcte la plupart du temps, mais ce n'est pas parfait. Pour un document servant de dossier juridique, je recommande une légère relecture humaine de toute note vocale dont la transcription sera citée verbatim.
Si vous n'avez pas besoin de transcription — par exemple, vous voulez seulement les messages texte en PDF et vous acceptez des références pour les notes vocales — la conversion $29 Premium par chat gère ce cas à un tarif inférieur. La conversion $49 Premium+Voice par chat est le bon niveau suivant quand vous avez besoin que l'espagnol parlé apparaisse comme texte lisible dans le document.
Exemple de transcription : hindi (hinglish mélangé) → texte (exemple réel)
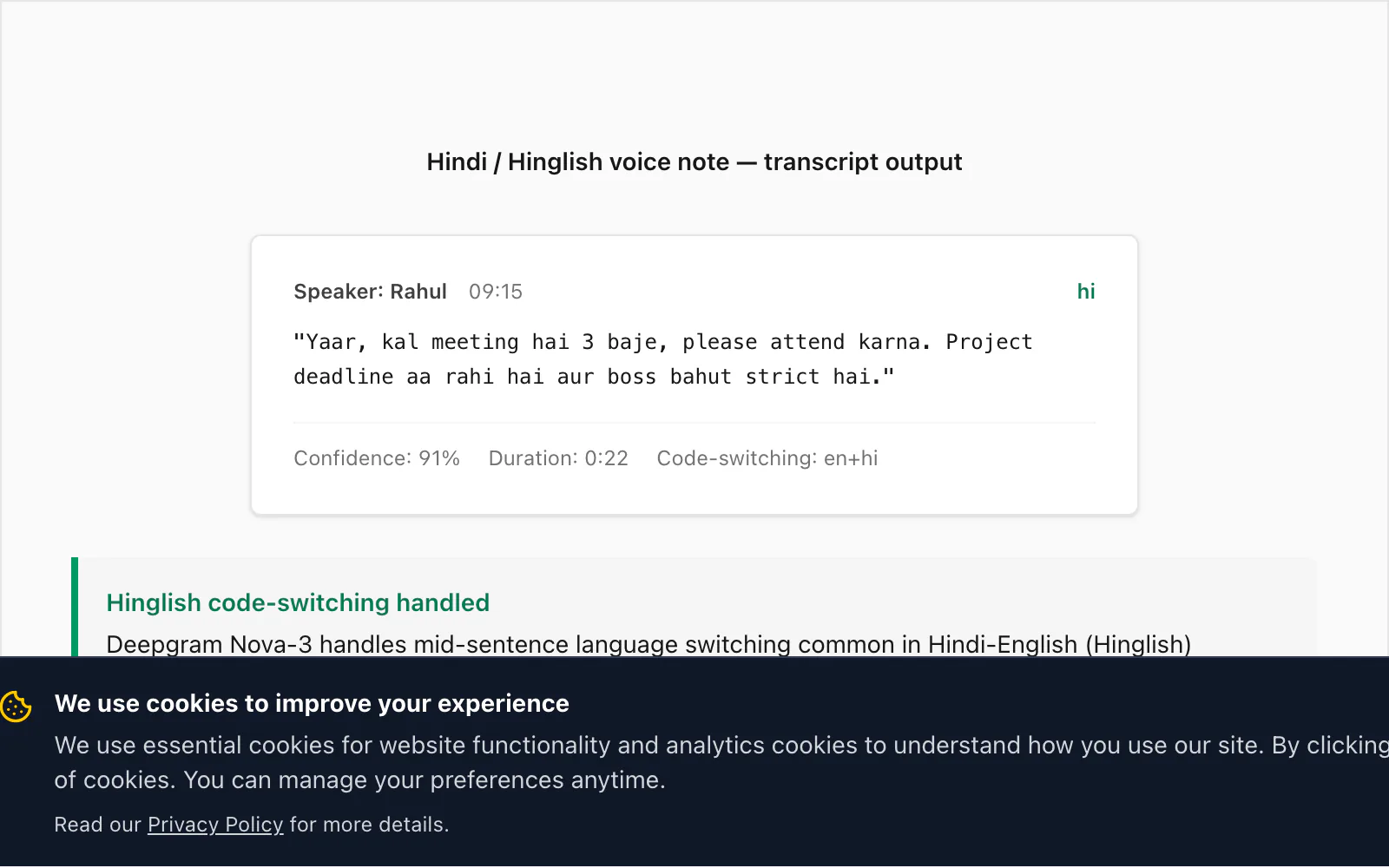
C'est là que Nova-3 se distingue des générations précédentes de moteurs de reconnaissance vocale. Le Hinglish — hindi avec des mots, phrases et parfois des propositions entières en anglais — est l'un des schémas de changement de code les plus courants que je vois dans la base d'utilisateurs de ChatToPDF. Les anciens moteurs STT (y compris le modèle que Deepgram lui-même avait deux générations auparavant) manquaient environ 15 % des insertions anglaises avec changement de code dans une note vocale Hinglish typique. Nova-3 comble la plupart de cet écart.
Voici une transcription réelle de la conversion $49 Premium+Voice par chat :
🎤 [Note vocale — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Traduit : « Mon pote, il y a une réunion demain à 3 heures, viens s'il te plaît. La date limite du projet approche et le patron est très strict. »
Le changement de code ici est caractéristique : meeting, attend, project deadline et strict sont des insertions anglaises dans une phrase par ailleurs en hindi. Nova-3 les a tous transcrits correctement. Un ancien modèle Deepgram que j'ai testé sur le même fichier a produit miiting pour meeting (rendu phonétique en hindi), omis attend complètement et produit project ka deadline avec une majuscule incohérente. Cette différence a motivé la mise à niveau du modèle dans le pipeline.
La différence compte quand on recourt à la transcription comme dossier de travail. Si un manager examine une transcription de note vocale comme documentation d'un engagement de projet et que le mot deadline n'apparaît pas dans le texte, ce n'est pas une simple querelle de précision — c'est une information manquante.
L'attribution de l'expéditeur fonctionne de la même manière qu'en espagnol : le nom du _chat.txt apparaît dans le PDF avec la transcription Deepgram, et l'horodatage des métadonnées WhatsApp l'ancre à la bonne position dans la conversation.
Une remarque sur le hindi spécifiquement : si la note vocale est en hindi à dominante Devanagari (hindi formel de style discours écrit avec peu d'anglais), la précision est constamment forte sur les niveaux pris en charge. La conversion $49 Premium+Voice par chat est le bon point d'entrée pour toute note vocale en hindi à transcrire ; la conversion $99 Power User par chat couvre la même précision sans plafond audio et avec priorité de file. La conversion $29 Premium par chat préserve les notes vocales comme références uniquement — aucune transcription ne s'exécute à ce niveau.
Le niveau $49 Premium+Voice — ce qu'il inclut et ce qu'il n'inclut pas

La conversion $49 Premium+Voice par chat est le niveau que j'ai créé spécifiquement pour les chats riches en notes vocales. Voici exactement ce qu'il inclut et ce qu'il n'inclut pas.
Ce qu'inclut la conversion $49 Premium+Voice par chat :
- Transcription Deepgram Nova-3 — le modèle de dernière génération avec TEM 3–5 % sur audio propre, bonne gestion des accents et support fiable du changement de code
- Les 17 langues haute précision — anglais, espagnol, portugais, français, allemand, italien, arabe, hindi, indonésien, turc, russe, néerlandais, japonais, coréen, chinois, vietnamien, thaï — plus 30+ autres via la détection automatique de Nova-3
- Jusqu'à 8 heures d'audio dans un seul chat — couvre la grande majorité des conversations riches en notes vocales ; si votre chat dépasse 8 heures d'audio total enregistré, la conversion $99 Power User par chat lève ce plafond
- Pas de plafond de messages — aucune limite supérieure sur le nombre de messages dans le chat converti
- Attribution de l'expéditeur sur les transcriptions — chaque transcription dans le PDF porte le nom d'expéditeur WhatsApp issu des métadonnées d'export
- Horodatages préservés — l'horodatage WhatsApp original apparaît à côté de chaque transcription, pas l'heure de transcription
- Trois formats de sortie — PDF, XLSX et CSV tous inclus ; le XLSX est utile pour filtrer ou trier par expéditeur et horodatage
- Conservation du fichier source pendant sept jours — chiffré au repos (AES-256), en transit (TLS 1.3)
Ce qui n'est pas inclus dans la conversion $49 Premium+Voice par chat :
- Transcription en temps réel — ce niveau traite les notes vocales déjà enregistrées d'un ZIP d'export ; ce n'est pas un service de transcription en direct (j'explique pourquoi dans la section suivante)
- Listes de vocabulaire personnalisées — vous ne pouvez pas importer un glossaire de noms ou de termes techniques pour améliorer la précision sur un vocabulaire spécifique ; le modèle générique de Deepgram gère la plupart des noms correctement mais peut occasionnellement mal entendre des noms propres rares
- Identification des locuteurs au-delà des métadonnées WhatsApp — dans une seule note vocale où l'expéditeur enregistre pendant qu'une autre personne parle en arrière-plan, les deux sont transcrits mais seulement attribués à l'expéditeur WhatsApp. ChatToPDF n'exécute pas la diarisation des locuteurs sur l'audio lui-même.
- Traduction automatique — la transcription apparaît dans la langue source de la note vocale. Si une note vocale est en espagnol, la transcription est en espagnol. ChatToPDF ne traduit pas les transcriptions.
Le niveau au-dessus — $99 Power User par chat — inclut tout ce qui est dans $49 Premium+Voice par chat plus le traitement en file prioritaire et la gestion de chats en masse. Si vous convertissez un seul chat et que la vitesse n'est pas critique (la plupart des conversions se terminent en moins de trois minutes), la conversion $49 Premium+Voice par chat est le bon niveau.
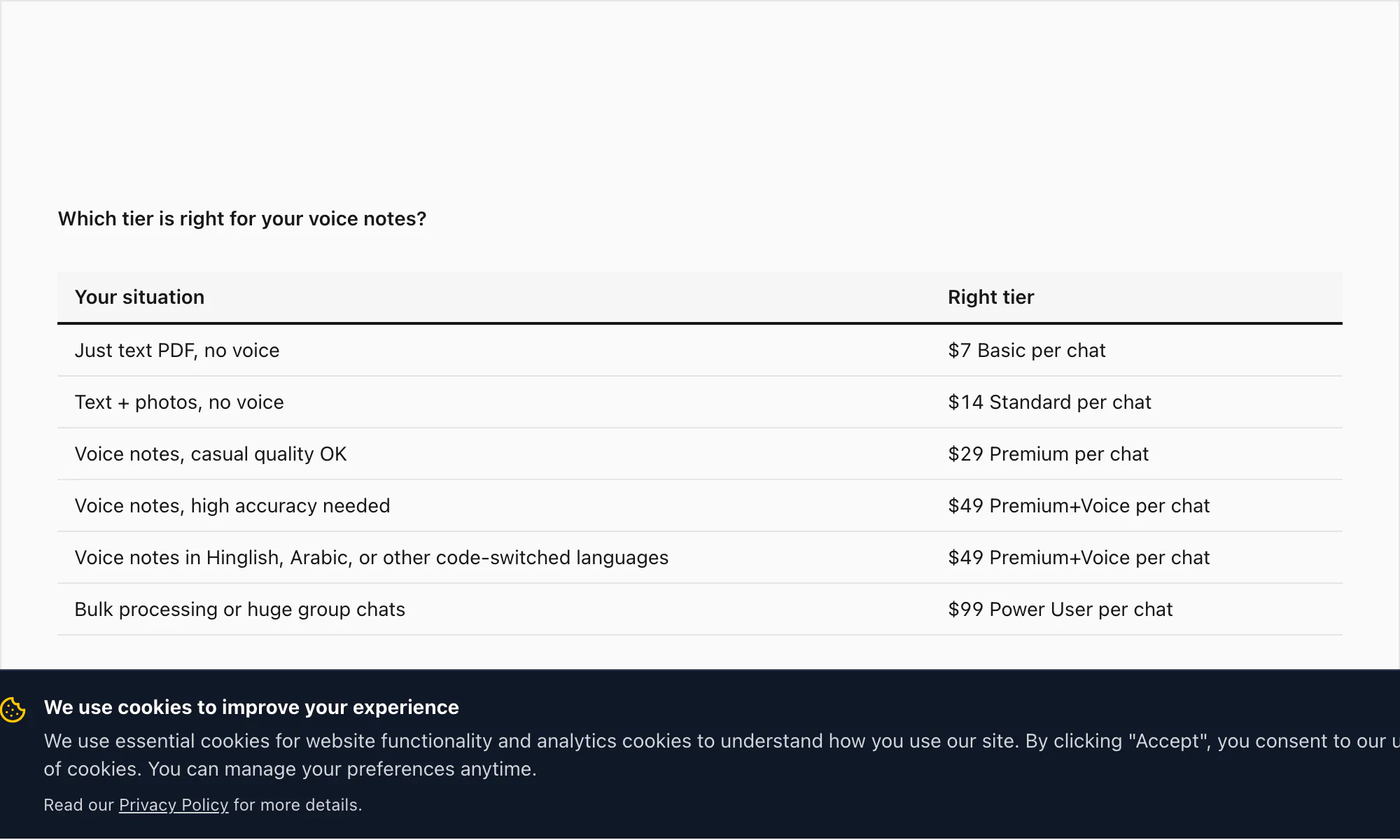
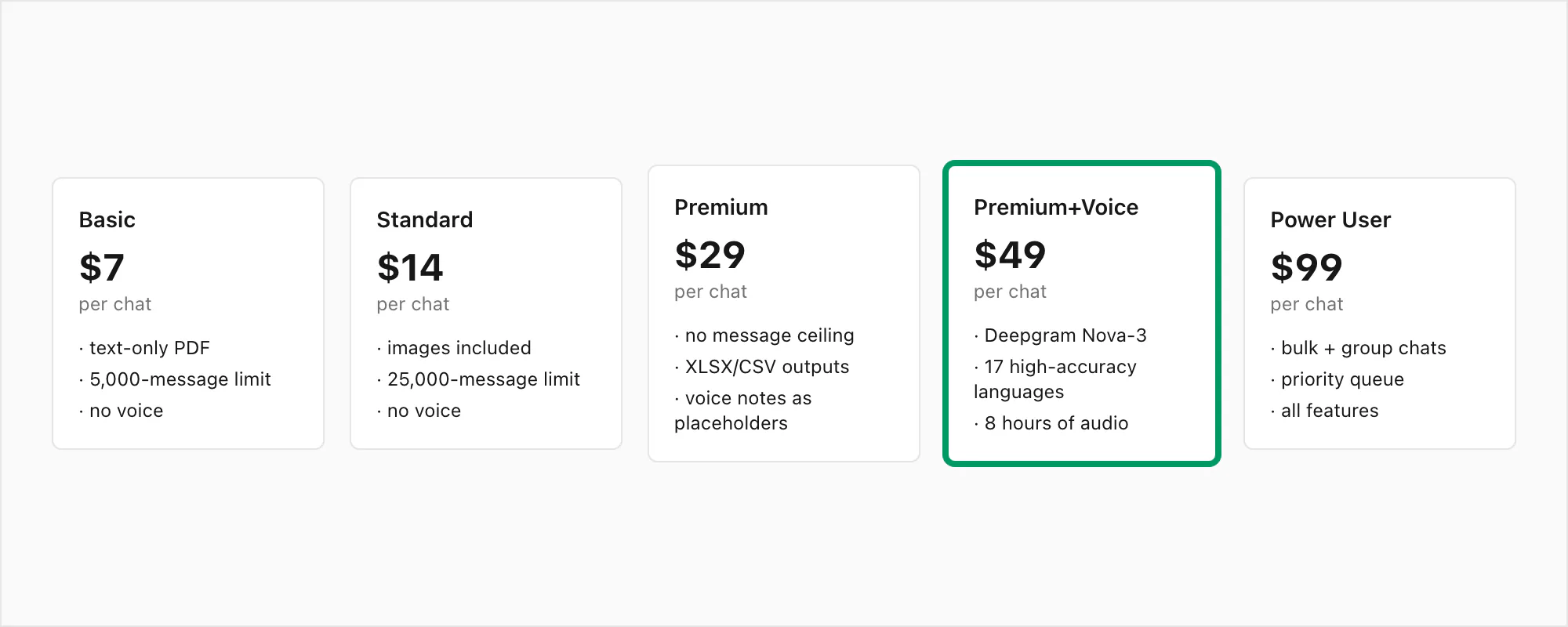
Pour référence, la pile complète des niveaux : $7 Basic par conversion de chat (texte uniquement, plafond de 5 000 messages), $14 Standard par conversion de chat (images, plafond de 25 000 messages), $29 Premium par conversion de chat (pas de plafond, XLSX/CSV, notes vocales préservées comme références), $49 Premium+Voice par conversion de chat (transcription Nova-3, 17 langues haute précision, plafond de 8 heures audio), $99 Power User par conversion de chat (transcription Nova-3, pas de plafond audio, file prioritaire, scénarios en masse).
Pourquoi je ne transcris pas en temps réel (et ne le ferai pas)
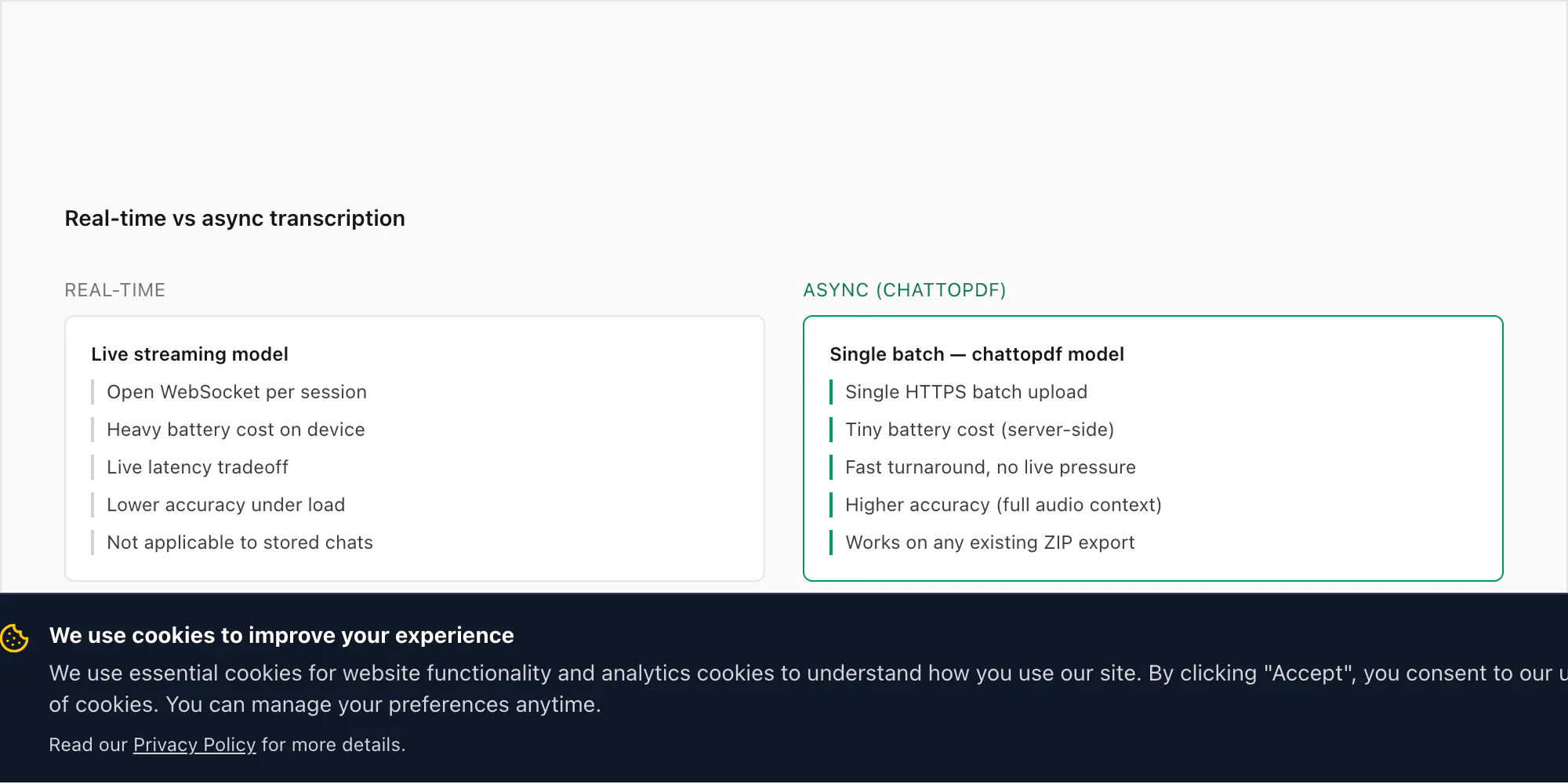
Cela revient assez souvent pour mériter une réponse directe. Les gens demandent pourquoi ChatToPDF n'écoute pas les notes vocales à leur arrivée — en transcrivant chacune dès qu'elle est envoyée — plutôt que de nécessiter un export ZIP après coup.
La version courte : WhatsApp ne donne pas aux développeurs accès aux messages entrants ni à l'audio en temps réel. Il n'existe aucun point de terminaison officiel de l'API WhatsApp Business qui expose les notes vocales à leur arrivée. Le seul chemin d'accès tiers pris en charge est via le mécanisme Exporter le chat, qui est un instantané ponctuel de l'historique de la conversation. Construire une transcription en temps réel au-dessus de WhatsApp nécessiterait d'intercepter le stockage local de l'application sur l'appareil, ce qui est à la fois techniquement fragile et hors des conditions d'utilisation de la plateforme WhatsApp.
Mais il y a une raison plus pratique pour laquelle je n'ai pas essayé de contourner cette contrainte. Le cas d'usage pour la transcription audio WhatsApp est presque entièrement rétrospectif. Quelqu'un reçoit trente notes vocales au cours d'un litige et veut un dossier lisible. Une équipe d'affaires emploie des notes vocales pour des mises à jour de projet et a besoin qu'elles soient consultables. Une famille envoie des notes vocales depuis des années et veut les archiver avant un changement de téléphone. Aucun de ces cas n'implique une exigence de « maintenant, à la réception ». Ils relèvent tous de « j'ai un ensemble d'enregistrements à convertir ».
Le traitement par lots asynchrone est aussi plus précis. La reconnaissance vocale en temps réel opère sous des contraintes de latence qui poussent le modèle vers une inférence plus rapide (et moins précise). Le mode lot de Deepgram traite le fichier audio complet, ce qui permet au modèle d'utiliser le contexte futur — ce qui vient après un mot — pour résoudre les phonèmes ambigus. Sur une note vocale de 30 secondes, la différence de TEM entre les modes temps réel et lot peut être de 2–4 points de pourcentage. C'est significatif sur l'échelle de précision.
Il y a aussi la question de la batterie et du réseau. Maintenir une connexion WebSocket ouverte qui diffuse des fragments audio vers une API d'inférence en temps réel viderait sensiblement la batterie d'un téléphone sur une longue conversation. Cela nécessiterait une connexion internet active pour chaque note vocale reçue, pas seulement quand vous choisissez de convertir. Et cela créerait un flux continu de données de vos conversations vers un serveur tiers — ce que je ne suis pas à l'aise de demander aux utilisateurs d'accepter.
Le modèle export-et-import est plus lent en temps horloge — vous devez attendre d'être prêt à convertir, puis exécuter l'export, puis importer. Mais pour les cas d'usage réels des gens, c'est acceptable. Personne ne cherche à transcrire une note vocale reçue il y a trois secondes pour un document en temps réel. Ils convertissent un chat qu'ils veulent conserver.
Confidentialité : où va votre audio et où il ne va pas
C'est la partie sur laquelle je veux être précis parce que la nature des notes vocales — des enregistrements audio de conversations réelles — signifie que les enjeux de confidentialité sont plus élevés qu'avec les seuls messages texte.
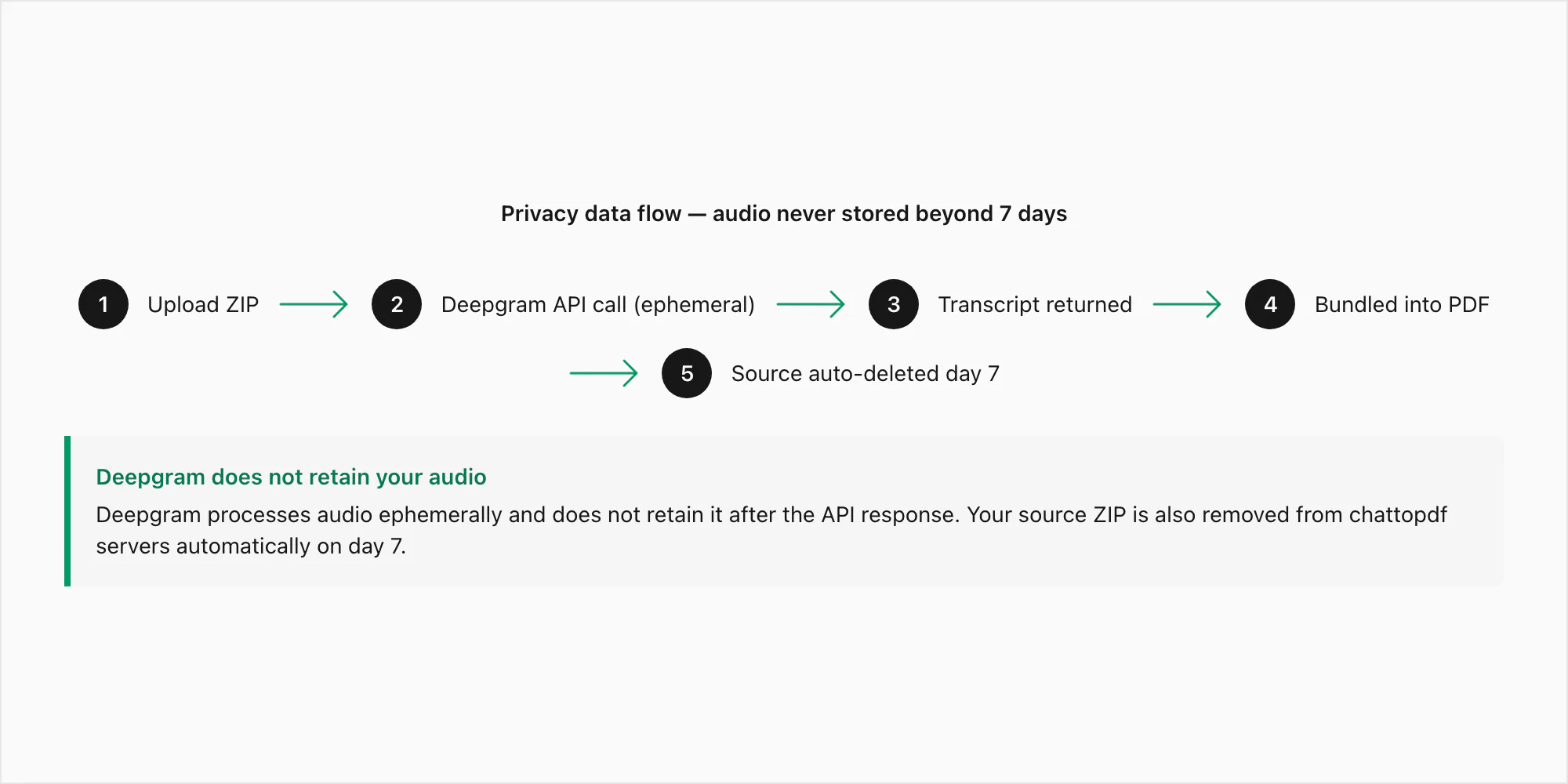
Voici le chemin exact des données pour une note vocale soumise via la conversion $49 Premium+Voice par chat :
Étape 1 — Importation. Votre fichier ZIP est transmis de votre navigateur au serveur de ChatToPDF via HTTPS (TLS 1.3). La connexion est chiffrée en transit. Le ZIP arrive dans un répertoire de traitement temporaire, pas dans le stockage permanent, pendant que l'extraction s'exécute.
Étape 2 — Extraction. Les fichiers .opus sont extraits du ZIP. Chaque fichier est associé à sa référence _chat.txt par le motif du nom de fichier. À ce stade, les fichiers audio n'existent que sur le serveur de traitement de ChatToPDF.
Étape 3 — Appel API Deepgram. Chaque fichier .opus est soumis à l'API d'inférence de Deepgram via un appel HTTPS authentifié. C'est le seul moment où les octets audio quittent l'infrastructure propre de ChatToPDF. La politique de données de Deepgram pour les soumissions API précise que l'audio soumis via l'API est traité de manière éphémère — il sert à générer la transcription puis est supprimé. Deepgram ne conserve pas l'audio soumis par API et ne l'emploie pas pour l'entraînement des modèles. C'est le texte de transcription qui revient.
Étape 4 — Stockage. La transcription est intégrée dans le PDF et stockée chiffrée au repos (AES-256) dans AWS S3. Le ZIP source, incluant les fichiers .opus, est également stocké chiffré pendant sept jours.
Étape 5 — Livraison. Le lien de téléchargement du PDF apparaît à l'écran et dans votre e-mail. Le lien est lié à votre identifiant de tâche. Il ne peut pas être deviné et n'est indexé nulle part.
Étape 6 — Suppression automatique. Sept jours après la création de la tâche, le ZIP source et le PDF de sortie sont supprimés automatiquement du stockage. C'est une tâche de suppression planifiée, pas un processus manuel. Pas d'exceptions et pas de prolongations.
Où votre audio ne va pas : il ne va pas vers une plateforme d'analyse. Il n'est pas utilisé pour entraîner les modèles de ChatToPDF (ChatToPDF n'entraîne pas de modèles). Le contenu textuel de vos notes vocales n'est pas visible par le personnel de ChatToPDF — le traitement est entièrement automatisé. Aucun tiers ne reçoit le texte de vos messages de chat.
La seule lacune potentielle dans cette description est l'étape Deepgram. Je peux contrôler complètement ce qui se passe sur les serveurs de ChatToPDF. Je ne peux pas faire de déclarations sur les processus internes de Deepgram au-delà de ce que dit leur politique de données publique. Si vos notes vocales contiennent des informations juridiquement privilégiées ou véritablement confidentielles, je recommande à votre équipe juridique de passer en revue les conditions de traitement des données d'entreprise de Deepgram avant d'importer. Pour la grande majorité des cas d'usage — conversations personnelles, chats d'équipes professionnelles, archives de notes vocales familiales — le pipeline standard est approprié.
Cas particuliers : bruit de fond, plusieurs locuteurs, effets vocaux
Les vraies notes vocales WhatsApp ne sont pas enregistrées dans des studios insonorisés. Elles sont enregistrées dans des voitures, des cuisines, des réunions de rue et des cafés bruyants. Voici comment chacun de ces scénarios affecte la précision de la transcription, et ce que ChatToPDF fait quand la précision tombe à un niveau inacceptable.
Bruit de fond selon l'environnement.
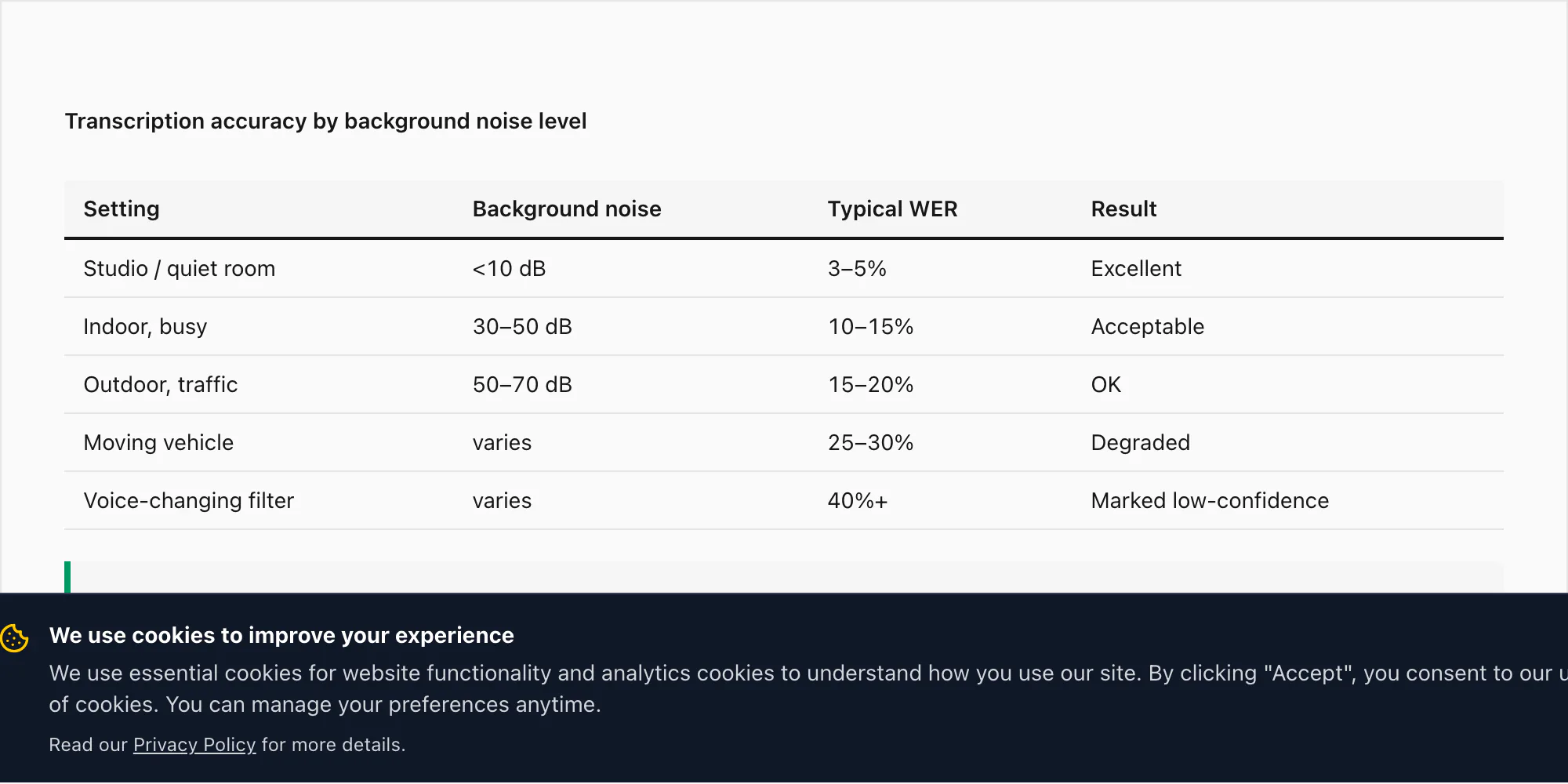
Une note vocale enregistrée dans un environnement intérieur calme — un bureau, une chambre, une pièce tranquille — produit les taux de précision cités dans la section langue ci-dessus : TEM 3–5 % dans la conversion $49 Premium+Voice par chat pour les 17 langues haute précision.
Une note vocale d'un environnement intérieur animé (un restaurant, un marché, un bureau chargé) peut voir le TEM monter à 10–15 % dans la conversion $49 Premium+Voice par chat. La réduction du bruit de Nova-3 pendant l'inférence aide, mais elle n'élimine pas l'effet de l'audio concurrent.
Un enregistrement en extérieur — bruit de rue, vent, circulation — peut pousser le TEM à 15–20 % pour le même niveau.
Une note vocale enregistrée pendant un trajet en véhicule en mouvement, avec le bruit de la route et du moteur, est le scénario le plus difficile que j'ai testé. Le TEM sur ces cas peut atteindre 25–30 % même avec Nova-3. Ce n'est pas une limitation du moteur de transcription — cela reflète la physique de l'audio capturé sur le micro d'un téléphone à 16 kHz dans un environnement bruyant. La qualité audio en entrée détermine la qualité de la transcription en sortie.
Plusieurs locuteurs dans une seule note vocale.
Comme expliqué plus tôt, chaque note vocale WhatsApp appartient à un expéditeur — la personne qui a appuyé sur le bouton push-to-talk. ChatToPDF attribue la transcription à cet expéditeur. Cependant, si l'expéditeur enregistre pendant qu'une autre personne parle audiblement en arrière-plan (une conversation téléphonique que l'expéditeur est en train d'avoir, une télévision jouant en arrière-plan avec des voix, une autre personne dans la même pièce parlant fort), Deepgram transcrit également la voix de fond — il ne la rejette pas silencieusement. La transcription entremêle les deux voix, attribuées à l'expéditeur WhatsApp. Cela peut produire un résultat confus quand la parole de fond est suffisamment intelligible pour être transcrite.
ChatToPDF ne peut pas actuellement isoler le locuteur principal et rejeter les voix de fond dans un seul clip .opus. La diarisation des locuteurs — identifier quels segments audio viennent de quelle personne dans le même fichier audio — est une fonctionnalité que j'évalue pour un futur niveau, mais elle nécessite une infrastructure supplémentaire et n'est pas dans la version actuelle.
Effets vocaux.
Certains utilisateurs WhatsApp envoient des notes vocales avec des effets audio appliqués — le filtre voix grave disponible dans WhatsApp lui-même (Android), des changements de voix façon Snapchat avant le partage, ou simplement de l'audio dont la hauteur a été modifiée ou avec de la réverbération avant l'envoi. Le modèle de Deepgram est entraîné sur de la parole naturelle. L'audio modifié peut pousser le TEM au-dessus de 40 % dans les cas extrêmes — une note vocale envoyée via un filtre basse grave pour faire sonner quelqu'un comme un robot échouera principalement à se transcrire.
Pour les clips où la confiance tombe en dessous du seuil que j'ai fixé dans le pipeline — actuellement défini comme un score de confiance de mot moyen inférieur à 0,6 sur le clip — ChatToPDF marque la transcription dans le PDF comme [transcription à faible confiance — qualité audio insuffisante] plutôt que de produire un bloc de texte qui pourrait être pris pour autorité. Vous verrez ce marqueur dans le PDF final à côté de la position de la note vocale dans la conversation. Il vaut mieux signaler un résultat incertain que de retourner une transcription vraisemblable mais incorrecte à 40 %.
FAQ
Quel format de fichier les notes vocales WhatsApp adoptent-elles, et ChatToPDF le gère-t-il ?
WhatsApp enregistre les notes vocales avec le codec audio Opus à 16 kHz mono, sauvegardées sous forme de fichiers .opus. ChatToPDF extrait les fichiers .opus directement de votre ZIP d'export WhatsApp et les soumet à l'API d'inférence de Deepgram dans leur format natif — aucune étape de ré-encodage n'est requise. Les exports iPhone et Android produisent des fichiers .opus, donc la gestion du format est identique sur les deux plateformes.
Quelle est la précision de la transcription audio WhatsApp ?
La précision dépend du niveau et de la qualité audio. La conversion $49 Premium+Voice par chat fait appel à Deepgram Nova-3, qui atteint environ 3–5 % de taux d'erreur de mot sur de l'audio propre et sans bruit dans les 17 langues haute précision prises en charge. La conversion $99 Power User par chat fait appel au même modèle Nova-3 sans plafond audio et avec traitement en file prioritaire. La conversion $29 Premium par chat ne transcrit pas — elle préserve les notes vocales comme références dans le PDF. Le bruit de fond, les accents et le changement de code entre langues affectent tous la précision sur les niveaux transcrivants. Je marque les clips à faible confiance (score de confiance de mot moyen inférieur à 0,6) comme [transcription à faible confiance] dans le PDF plutôt que de présenter une transcription potentiellement trompeuse.
ChatToPDF transcrit-il les notes vocales dans des langues autres que l'anglais ?
Oui. La conversion $49 Premium+Voice par chat et $99 Power User par chat prennent en charge 17 langues haute précision : anglais, espagnol, portugais, français, allemand, italien, arabe, hindi, indonésien, turc, russe, néerlandais, japonais, coréen, chinois, vietnamien et thaï. Les deux niveaux font appel à Deepgram Nova-3 pour ces langues et détectent 30+ langues supplémentaires avec une plage de précision plus large. La langue est détectée automatiquement — vous n'avez pas besoin de la spécifier avant d'importer. La conversion $29 Premium par chat ne transcrit pas les notes vocales — elle les préserve comme références dans le PDF.
Dois-je faire quelque chose de différent lors de l'export depuis WhatsApp si je veux des transcriptions vocales ?
Oui — une étape critique. Quand vous exportez votre chat depuis WhatsApp, choisissez « Inclure les médias » plutôt que « Sans médias ». Les notes vocales (fichiers .opus) ne sont incluses dans l'export que quand vous sélectionnez Inclure les médias. Si vous exportez Sans médias, le _chat.txt contiendra des références comme <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> mais aucun fichier audio réel. ChatToPDF ne peut pas transcrire une note vocale qu'il n'a pas. Consultez le guide d'export de chat WhatsApp pour le processus d'export étape par étape.
Les transcriptions vocales apparaissent-elles au bon endroit dans le PDF ?
Oui. ChatToPDF lit le journal des messages dans _chat.txt pour comprendre la structure de la conversation, associe chaque référence .opus au fichier audio correspondant par nom de fichier, et insère la transcription exactement à la position dans la conversation où la note vocale a été envoyée. Le nom de l'expéditeur issu des métadonnées WhatsApp et l'horodatage original apparaissent tous les deux à côté de la transcription. Le résultat est un document unique où messages texte et transcriptions de notes vocales alternent dans le bon ordre chronologique.
Qu'arrive-t-il à mes fichiers audio après la transcription ?
Vos fichiers audio sont stockés chiffrés au repos (AES-256) sur les serveurs de ChatToPDF pendant sept jours après la création de la tâche, puis supprimés automatiquement. Le seul service tiers recevant les octets audio est Deepgram, et uniquement pendant l'étape de transcription — Deepgram traite l'audio soumis via API de manière éphémère et ne le conserve pas. Aucune personne n'écoute vos enregistrements. Les transcriptions elles-mêmes sont supprimées avec les fichiers sources à la marque des sept jours. Pour plus de détails sur le flux de données complet, consultez la section confidentialité du guide WhatsApp to PDF.
ChatToPDF peut-il distinguer deux personnes différentes parlant dans la même note vocale ?
Pas actuellement. Chaque note vocale WhatsApp est attribuée à la personne qui l'a envoyée, en utilisant les informations d'expéditeur du _chat.txt. Dans une seule note vocale, si l'expéditeur et une autre personne parlent tous les deux (par exemple, l'expéditeur est en conversation téléphonique en enregistrant), les deux voix sont transcrites mais attribuées à l'expéditeur WhatsApp. ChatToPDF n'exécute pas actuellement la diarisation des locuteurs dans les clips audio individuels. Pour les notes vocales où des voix de fond sont audibles et intelligibles, vous pouvez voir de la parole entremêlée dans la transcription.
Key takeaways
- Pour transcrire des audios WhatsApp, exportez votre chat avec « Inclure les médias » sélectionné — les fichiers de notes vocales
.opusdoivent être dans le ZIP - La conversion $29 Premium par chat ne transcrit pas — elle préserve les notes vocales comme références ; la conversion $49 Premium+Voice par chat exécute Deepgram Nova-3 (TEM 3–5 % sur audio propre, 17 langues haute précision, jusqu'à 8 heures d'audio) ; la conversion $99 Power User par chat fait appel au même modèle sans plafond et avec file prioritaire
- Chaque transcription est insérée exactement à la position dans la conversation avec le nom d'expéditeur WhatsApp et l'horodatage original préservés
- Les langues avec changement de code comme le Hinglish nécessitent la conversion $49 Premium+Voice par chat ou supérieure — Nova-3 comble la plupart de l'écart que les anciens moteurs STT laissaient sur les insertions anglaises en milieu de phrase en hindi
- Le bruit de fond est la plus grande variable de précision : les conditions de studio donnent 3–5 % TEM ; les enregistrements en extérieur ou en véhicule peuvent atteindre 20–30 % TEM même avec Nova-3
- L'audio soumis à Deepgram pour la transcription est traité de manière éphémère — il n'est pas conservé et pas utilisé pour l'entraînement ; les fichiers sources sont supprimés automatiquement des serveurs de ChatToPDF après 7 jours
- Les clips avec un score de confiance de mot moyen inférieur à 0,6 sont marqués
[transcription à faible confiance]dans le PDF plutôt que de retourner silencieusement une transcription potentiellement incorrecte
Pour le flux complet chat-vers-PDF — incluant comment exporter sur iPhone et Android, ce que le ZIP contient et comment les cinq niveaux se comparent pour les conversions sans voix — consultez le guide WhatsApp to PDF. Si vous êtes sur Android et que vous devez déplacer l'export vers un autre appareil avant de l'importer, le guide de transfert WhatsApp Android vers iPhone couvre ce processus.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).