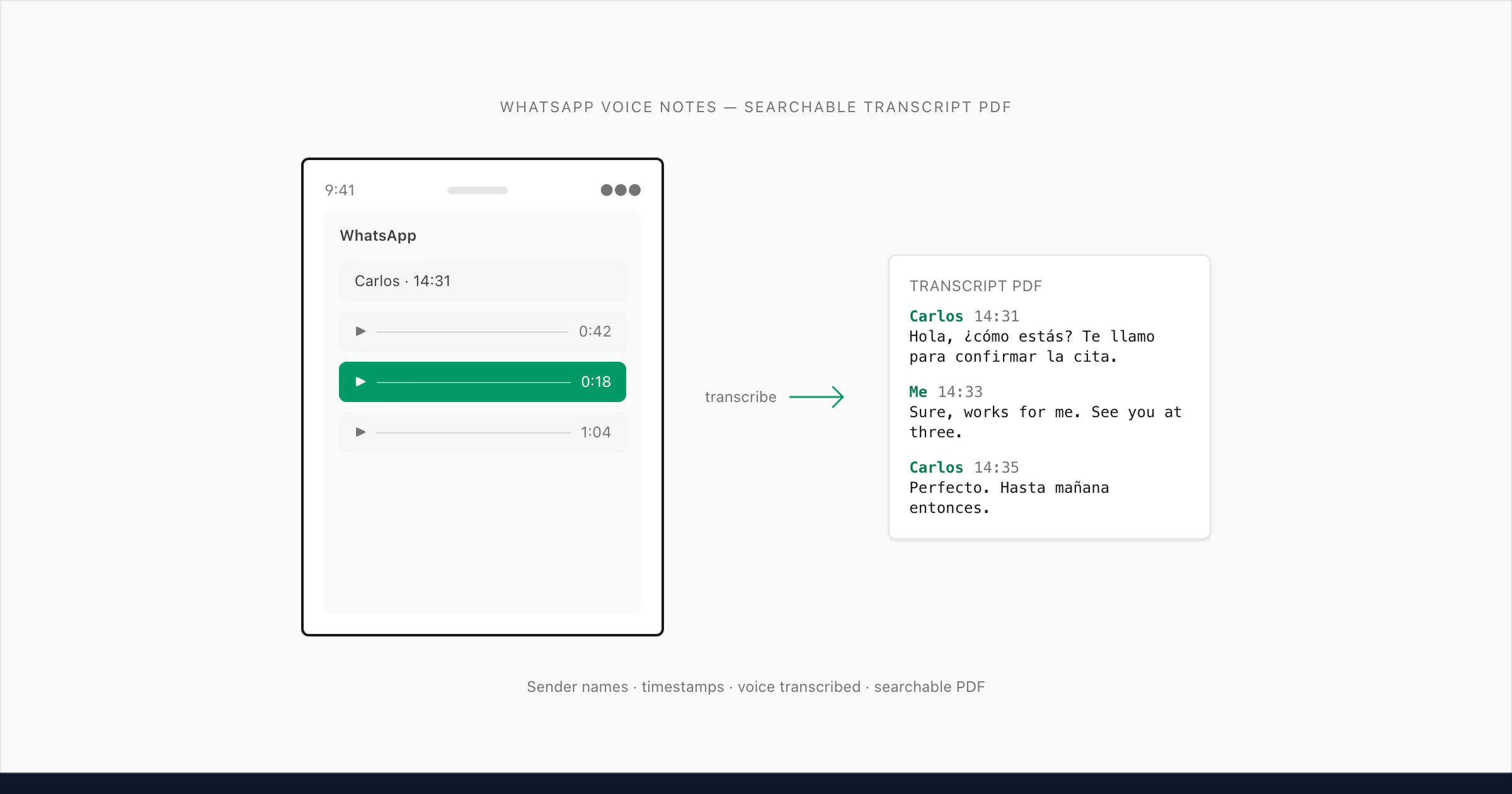
"Transcribe WhatsApp audio" का actually मतलब (और यह जितना लगता है उससे कठिन क्यों है)
लोग "transcribe WhatsApp audio" phrase को कम से कम तीन अलग-अलग चीज़ों के लिए use करते हैं। कुछ live voice calls transcribe करना चाहते हैं — जो WhatsApp किसी developer API के ज़रिए expose नहीं करता। कुछ WhatsApp से save किए गए audio files को text में convert करना चाहते हैं। और कुछ — सबसे बड़ा group — exported WhatsApp chat में हर voice note को readable text में convert करना चाहते हैं ताकि पूरी conversation एक document के रूप में sense बनाए।
ChatToPDF उस third use case के लिए बना है। यह जो problem solve करता है वह specific है: आप एक WhatsApp chat export करते हैं जिसमें text messages और voice notes दोनों हैं, और WhatsApp से आपको एक ZIP मिलती है जिसमें _chat.txt और media files का एक folder है। _chat.txt में ऐसी lines हैं जैसे <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> जहाँ voice note belong करती है। जब तक आप कुछ build न करें, कुछ भी उन्हें readable text में convert नहीं करता।
यहाँ वह बात है जो कोई नहीं बताता: जब लोग transcription tool ढूँढते हैं, तो वे अक्सर एक structural problem में फँस जाते हैं। Generic audio files handle करने वाले tools — MP3 upload करें, text वापस पाएं — नहीं जानते कि वह audio conversation में कहाँ belong करती है। वे file transcribe करते हैं लेकिन context खो देते हैं। आपको एक separate text block मिलता है बिना sender name, timestamp, या इस indication के कि पहले या बाद में क्या कहा गया। Legal matter, business record, या family archive के लिए वह context ही सब कुछ है।
मैंने जो बनाया (that's my solution to this problem) वह यह करता है: _chat.txt read करता है conversation structure समझने के लिए, हर .opus reference को ZIP में correct audio file से match करता है, audio transcribe करता है, और transcript को conversation में exactly सही position पर वापस insert करता है — sender का name और original timestamp preserve के साथ। Result एक single PDF है जहाँ text messages और voice note transcripts naturally alternate करते हैं, exactly जैसे conversation हुई थी।
Voice notes files नहीं हैं — in-app stream हैं
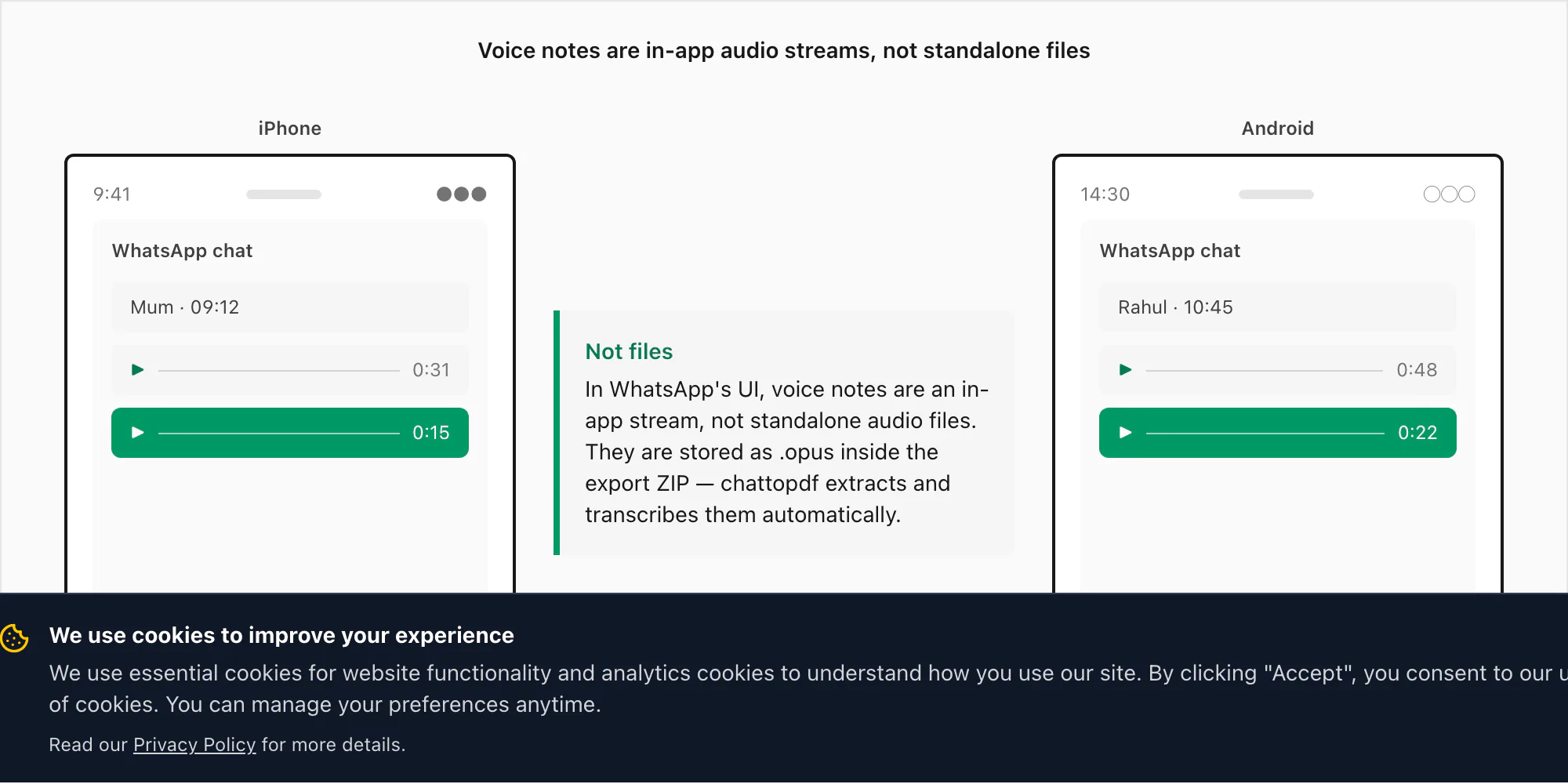
App में WhatsApp voice notes audio files जैसी दिखती हैं — waveform bar, duration, play button — लेकिन वे उस तरह stored नहीं होतीं जैसा ज़्यादातर लोग expect करते हैं। जब आप WhatsApp में microphone button hold करके voice note record करते हैं, WhatsApp audio को Opus codec use करके encode करता है और device पर एक private directory में .opus file के रूप में save करता है। वह directory iPhone या Android पर normal file browsing से accessible नहीं है।
उन .opus files को extract करने का एकमात्र तरीका WhatsApp का अपना Export Chat menu है, "Including Media" select करके। जब आप उस तरह export करते हैं, WhatsApp media folder के साथ _chat.txt message log package करता है — और वहाँ .opus files appear करती हैं।
Opus codec को briefly समझना worthwhile है क्योंकि यह explain करता है कि accuracy vary क्यों होती है। Opus voice-over-IP के लिए design हुआ था — low latency, अच्छा compression, low bitrates पर भी अच्छी quality। WhatsApp 16 kHz mono audio लगभग 16 kbps पर use करता है। Files tiny होती हैं: 60-second voice note typically 80 KB से 120 KB के बीच होती है। यह mobile data के लिए efficient है, लेकिन transcription accuracy के लिए optimal नहीं। Background noise, driving के दौरान record करी गई voice, या कमरे के दूसरे कोने से बोलने वाला कोई व्यक्ति effective quality और कम कर सकता है।
इसीलिए transcription model matter करता है। Opus 16 kHz mono at 16 kbps के साथ generic speech-to-text engine struggle करेगा। मैंने जो engine चुना वह specifically इसी तरह के audio के लिए choose किया गया था।
एक और structural point: हर WhatsApp voice note single-sender recording है। WhatsApp का push-to-talk model मतलब है एक person record करता है, फिर रुकता है, फिर दूसरा record करता है। यह actually एक transcription advantage है — एक recorded phone call के unlike जहाँ दो voices same audio track पर overlap करती हैं, WhatsApp export की हर .opus file exactly एक sender की होती है।
मैंने जो transcription engine चुना, और क्यों
ChatToPDF की voice transcription के पीछे engine के रूप में Deepgram settle करने से पहले मैंने कई transcription APIs evaluate किए। दूसरे serious contenders AssemblyAI, Whisper (OpenAI का open-source model), और कुछ cloud providers के generic speech APIs थे। यहाँ honest reasoning है।
Whisper एक free model के लिए impressive है, लेकिन मैंने English, Spanish, Hindi और Arabic में real WhatsApp .opus files के set पर accuracy tests run किए, और यह code-switching (एक voice note जो mid-sentence दो languages mix करे) और non-US English accents पर consistent weaknesses दिखाता है।
AssemblyAI genuinely अच्छा है और मैंने इसे early prototype में use किया। English पर accuracy Deepgram के comparable थी, लेकिन language support breadth और 16 kHz mono पर Opus-encoded audio की API response consistency ने Deepgram को multilingual use case के लिए better fit बनाया।
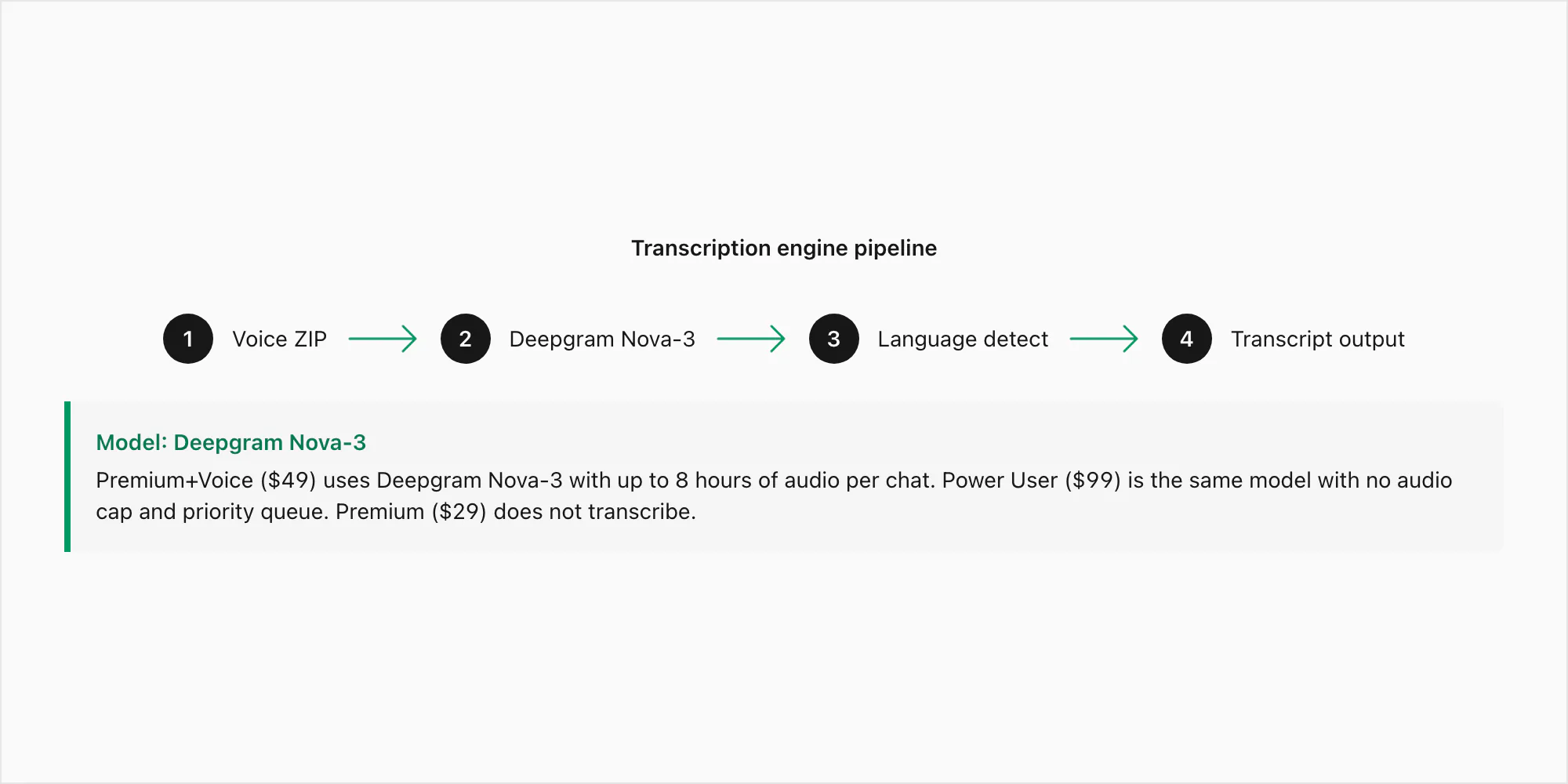
Deepgram Nova-3 current-generation model है जो clean, noise-free English audio पर approximately 3–5% word error rate achieve करता है और noisier recordings पर 8–15%। वे numbers 16 kHz mono Opus पर hold करते हैं, जो WhatsApp exports के लिए matter करने वाला format है। Nova-3 ही वह model है जो $49 Premium+Voice per chat conversion और $99 Power User per chat conversion दोनों के लिए use होता है।
Nova-3 पुराने speech-to-text engines को visibly outperform करता है तीन जगहों पर: regional accents (South African English, Indian English, Brazilian Portuguese), technical vocabulary (names, addresses, product terms जिन्हें generic model mishear करे), और code-switched audio जहाँ speaker एक single voice note में languages switch करे। $29 Premium per chat conversion transcription include नहीं करता — यह voice notes को PDF में placeholder references के रूप में preserve करता है बिना audio किसी model से run किए।
Pipeline इस तरह काम करती है: आपकी ZIP ChatToPDF के server पर land होती है, .opus files extract होती हैं, हर एक को language detection automatic set करके Deepgram के API पर authenticated HTTPS call के ज़रिए submit किया जाता है, और transcript वापस आता है — typically audio के per minute of two to five seconds में।
एक deliberate choice: मैं .opus audio को Deepgram पर submit करने से पहले pre-process या re-encode नहीं करता। कुछ tools Opus को WAV या MP3 में convert करते हैं यह reasoning करते हुए कि अलग format accuracy improve कर सकता है। Practice में, Deepgram का API Opus natively handle करता है और converting इस audio type पर results improve किए बिना latency add करता है।
17 languages में accuracy
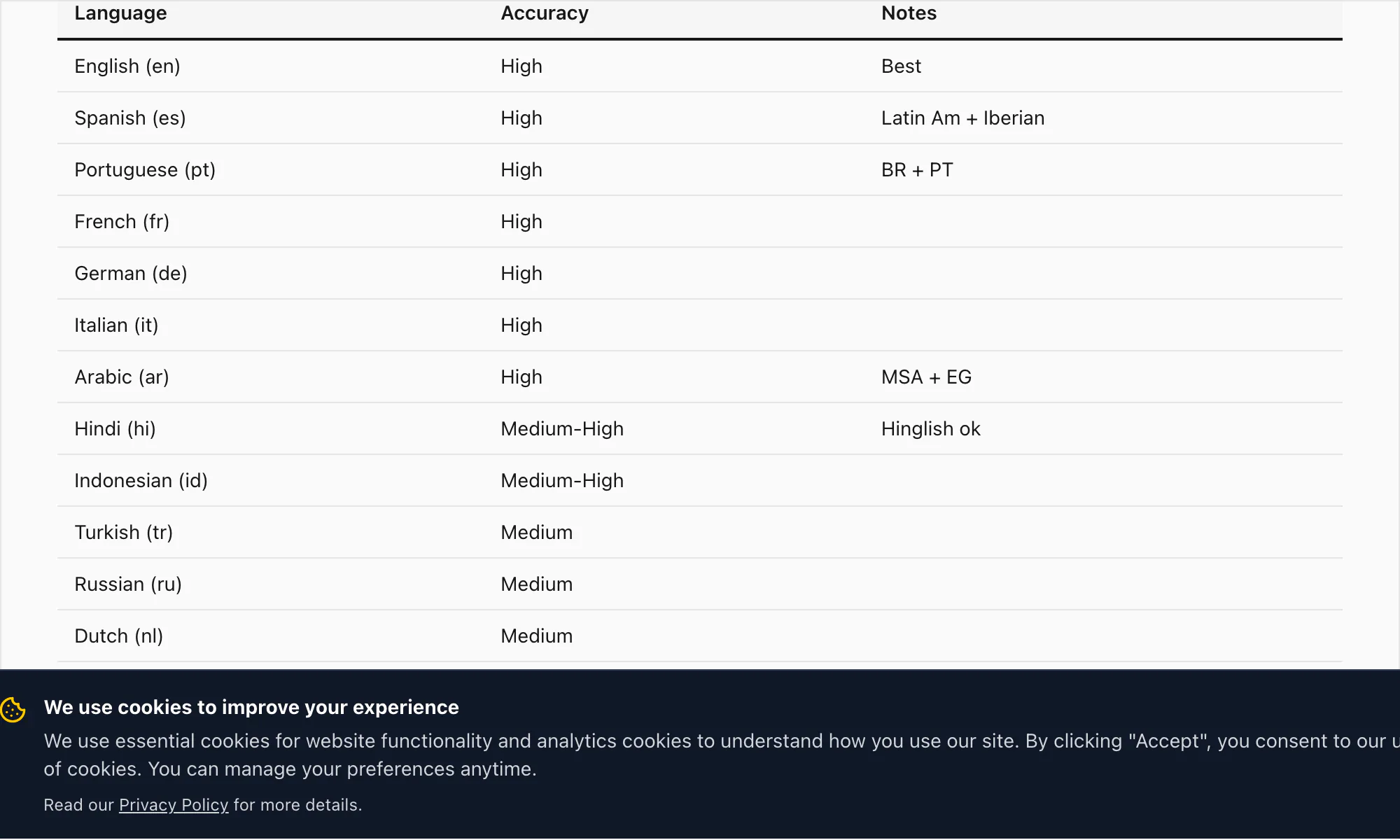
ChatToPDF की high-accuracy language tier 17 languages cover करती है। ये वे languages हैं जहाँ मुझे transcription quality पर documents, legal records और business use के लिए production-ready कहने का confidence है:
English (en) — WER 3–5% clean audio पर। UK, US, Australian, South African और Indian English variants include हैं। सभी English variants same Nova-3 model से $49 Premium+Voice per chat conversion पर handle होते हैं।
Spanish (es) — WER 4–6% $49 Premium+Voice per chat conversion पर। Latin American और Castilian variants handle करता है।
Portuguese (pt) — WER 4–7%। Brazilian और European Portuguese cover करता है।
French (fr) — WER 4–6%। Standard और Canadian French।
German (de) — WER 4–6%।
Italian (it) — WER 5–7%।
Arabic (ar) — WER 7–10%। Modern Standard Arabic अच्छी तरह transcribe होती है; dialectal Arabic (Egyptian, Gulf, Levantine) में wider variance है।
Hindi (hi) — pure Hindi पर WER 6–9%। Code-switched Hinglish (Hindi with English insertions) वह जगह है जहाँ Nova-3 पुराने transcription engines से सबसे बड़ा difference बनाता है — इसके बारे में नीचे sample transcript section में ज़्यादा।
Indonesian (id) — WER 5–8%।
Turkish (tr) — WER 5–8%।
Russian (ru) — WER 5–8%।
Dutch (nl) — WER 4–6%।
Japanese (ja) — WER 7–10%।
Korean (ko) — WER 6–9%।
Chinese (zh) — WER 7–10%। Mandarin।
Vietnamese (vi) — WER 7–10%।
Thai (th) — WER 8–12%।
इन 17 से परे, Deepgram Nova-3 wider accuracy range पर 30+ additional languages support करता है। Automatic language detection by default on है। ChatToPDF language specify किए बिना हर .opus file Deepgram को भेजता है, और Deepgram पहले कुछ seconds में dominant language detect करता है। Code-switching के लिए — genuinely 50/50 दो languages वाली voice note — detector एक को primary pick करता है और full clip पर वह model apply करता है।
Sample transcript: Spanish voice note → text (real example)
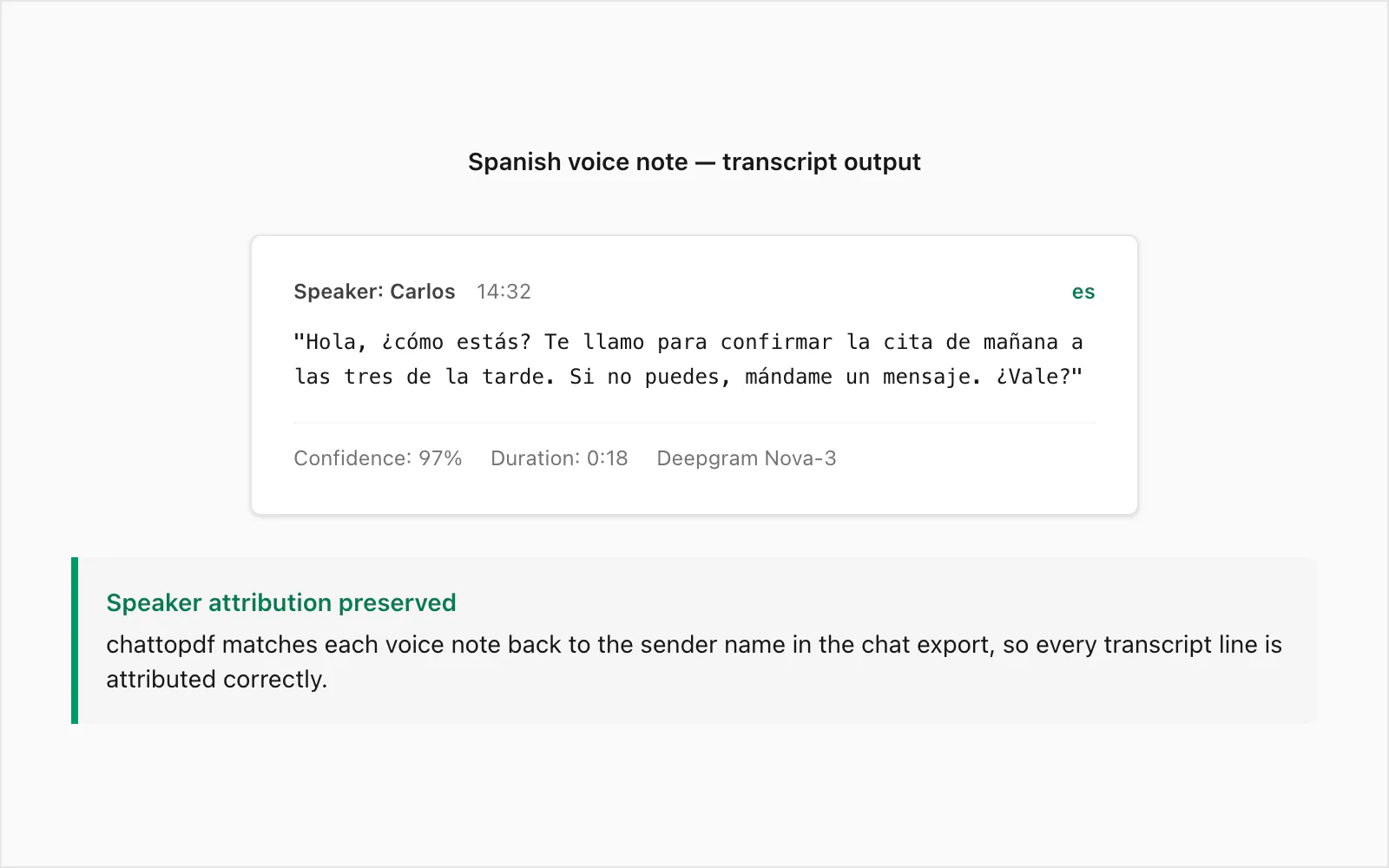
यह $49 Premium+Voice per chat conversion level पर transcribed एक real WhatsApp voice note है। Sender Colombian Spanish का native speaker था, quiet indoor environment में Android device पर recorded। Duration: 18 seconds।
Transcript output PDF में:
🎤 [Voice note — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
Sender PDF में _chat.txt के name से attributed है, timestamp वह है जो WhatsApp ने voice note send होने पर record किया, और transcript conversation में इससे पहले और बाद के text messages के बीच inline है।
Spanish accuracy कहाँ break down होती है? सबसे common errors homophones हैं: haya (subjunctive of haber) बनाम halla (from hallar)। Fast casual speech में ये phonetically identical हैं। Nova-3 surrounding context से ज़्यादातर समय correct spelling infer करता है, लेकिन यह perfect नहीं है। Document जो legal record के रूप में use होगा उसमें, voice notes के light human review की recommendation है।
अगर transcription बिल्कुल नहीं चाहिए — उदाहरण के लिए सिर्फ text messages PDF में चाहिए और voice notes के placeholder references से comfortable हैं — तो $29 Premium per chat conversion lower price पर वह case handle करता है।
Sample transcript: Hindi (Hinglish) → text (real example)
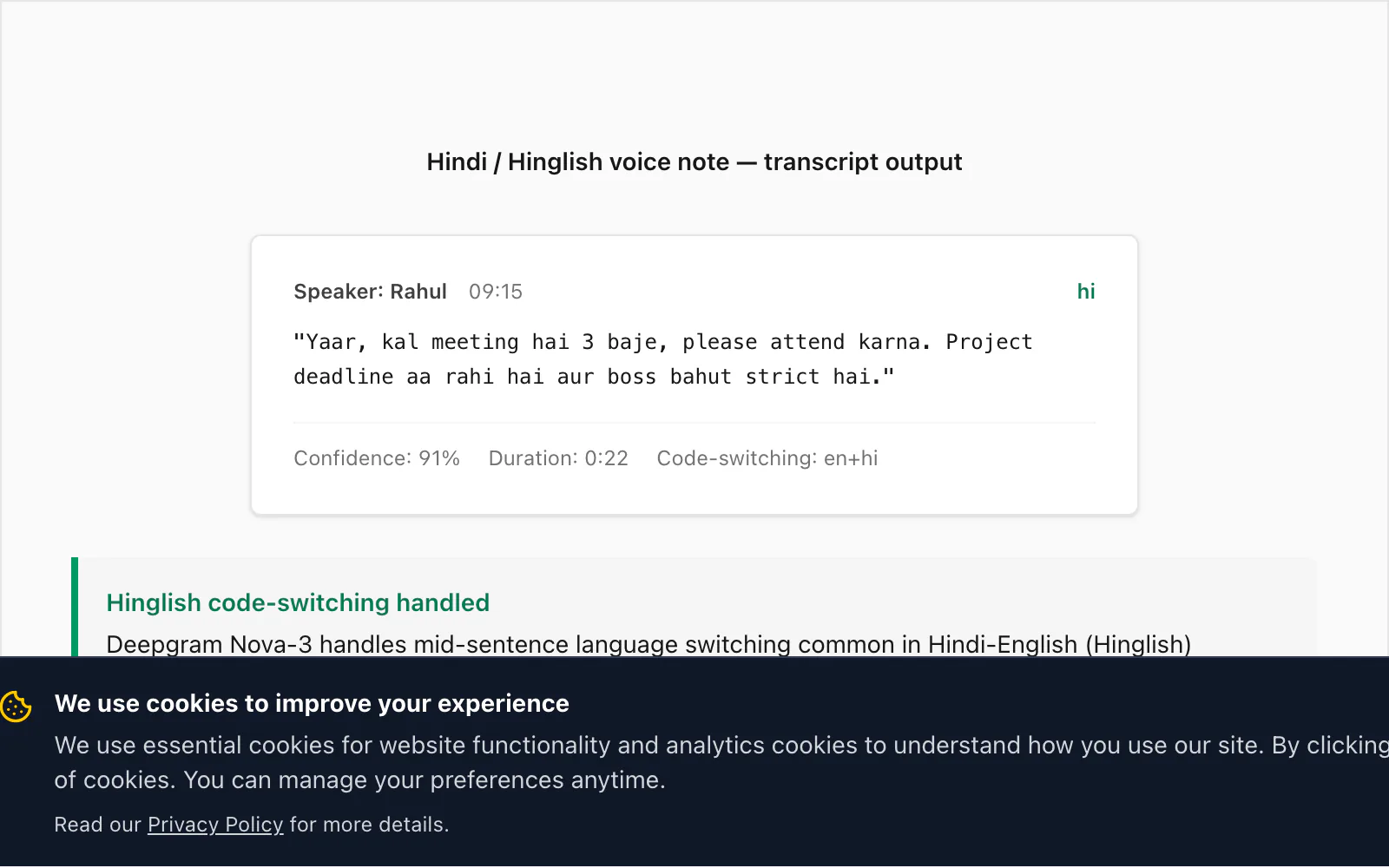
यह वह जगह है जहाँ Nova-3 speech-to-text engines की पुरानी generations से अपने आप को distinguish करता है। Hinglish — Hindi with embedded English words, phrases और sometimes full clauses — ChatToPDF के user base में मेरे देखे सबसे common real-world code-switching patterns में से एक है। Older STT engines (Deepgram का दो generations पहले का model सहित) typical Hinglish voice note में approximately 15% code-switched English insertions miss करते हैं। Nova-3 उस gap को mostly close करता है।
$49 Premium+Voice per chat conversion से एक real transcript:
🎤 [Voice note — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Code-switching यहाँ characteristic है: meeting, attend, project deadline और strict एक otherwise Hindi sentence में English insertions हैं। Nova-3 ने सभी को correctly transcribe किया। एक older Deepgram model जो मैंने same file पर test किया उसने meeting के लिए miiting produce किया (phonetic Hindi rendering), attend को entirely omit किया, और inconsistent capitalisation के साथ project ka deadline produce किया।
जब transcript workplace record के रूप में use हो रहा हो तो यह difference matter करता है। अगर कोई manager एक project commitment की documentation के रूप में voice note transcript review कर रहा है और deadline text में appear नहीं करता, तो यह minor accuracy quibble नहीं है — यह missing piece of information है।
Hindi specifically के बारे में एक note: अगर voice note Devanagari-dominant Hindi में है (formal, written-speech-style Hindi with minimal English), तो accuracy consistently strong रहती है। $49 Premium+Voice per chat conversion किसी भी Hindi voice notes transcribe करने के लिए right entry point है; $99 Power User per chat conversion same accuracy को बिना audio cap और queue priority के साथ cover करता है। $29 Premium per chat conversion voice notes को सिर्फ placeholders के रूप में preserve करता है — उस tier पर कोई transcription नहीं चलती।
$49 Premium+Voice tier — क्या है और क्या नहीं

$49 Premium+Voice per chat conversion वह tier है जो मैंने specifically voice-heavy chats के लिए बनाया। यहाँ exactly क्या include है और क्या नहीं।
$49 Premium+Voice per chat conversion में क्या है:
- Deepgram Nova-3 transcription — current-generation model जो clean audio पर 3–5% WER, strong accent handling और reliable code-switching support के साथ
- सभी 17 high-accuracy languages — English, Spanish, Portuguese, French, German, Italian, Arabic, Hindi, Indonesian, Turkish, Russian, Dutch, Japanese, Korean, Chinese, Vietnamese, Thai — plus Nova-3 की automatic language detection के ज़रिए 30+ और
- एक single chat में 8 hours तक audio — voice-heavy conversations की vast majority cover करता है
- कोई message ceiling नहीं — convert हो रहे chat में messages की कोई upper limit नहीं
- Transcripts पर sender attribution — PDF में हर transcript के साथ export metadata का WhatsApp sender name
- Timestamps preserve — original WhatsApp timestamp हर transcript के साथ appear करता है, transcription time नहीं
- तीन output formats — PDF, XLSX और CSV सभी शामिल; XLSX तब useful है जब sender और timestamp से filter या sort करना हो
- Seven-day source file retention — encrypted at rest (AES-256), in transit (TLS 1.3)
$49 Premium+Voice per chat conversion में क्या नहीं है:
- Real-time transcription — यह tier already-recorded voice notes को export ZIP से process करता है; यह live transcription service नहीं है
- Custom vocabulary lists — specific vocabulary पर accuracy improve करने के लिए names या technical terms की glossary upload नहीं कर सकते
- WhatsApp metadata से परे speaker identification — एक single voice note में जहाँ sender background में किसी और की बात सुनते हुए record करे, दोनों transcribe होते हैं लेकिन सिर्फ WhatsApp sender को attributed
- Automatic translation — transcript voice note की source language में appear करता है; ChatToPDF translate नहीं करता
इसके ऊपर का tier — $99 Power User per chat conversion — $49 Premium+Voice per chat conversion की सब कुछ के साथ priority queue processing और bulk-chat handling add करता है।
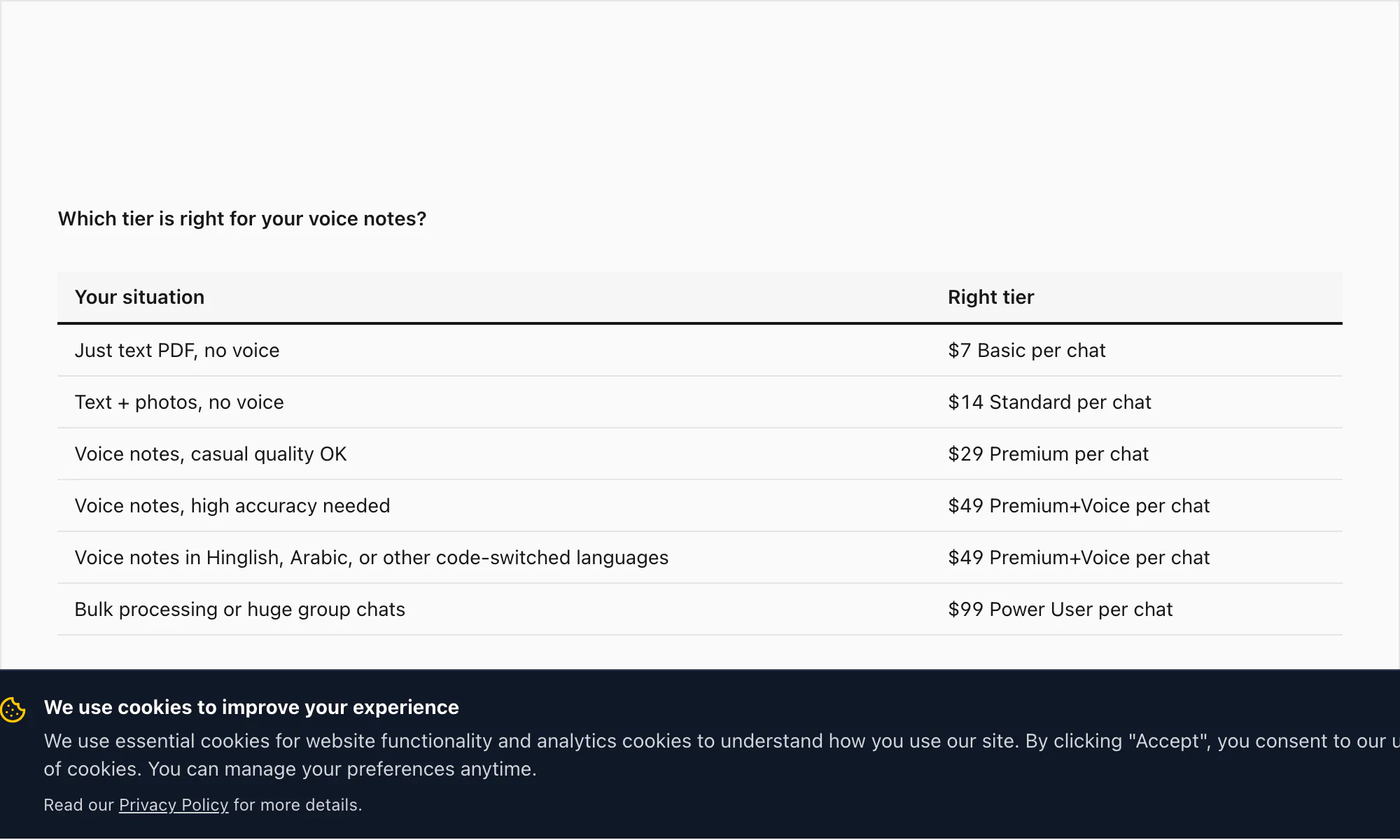
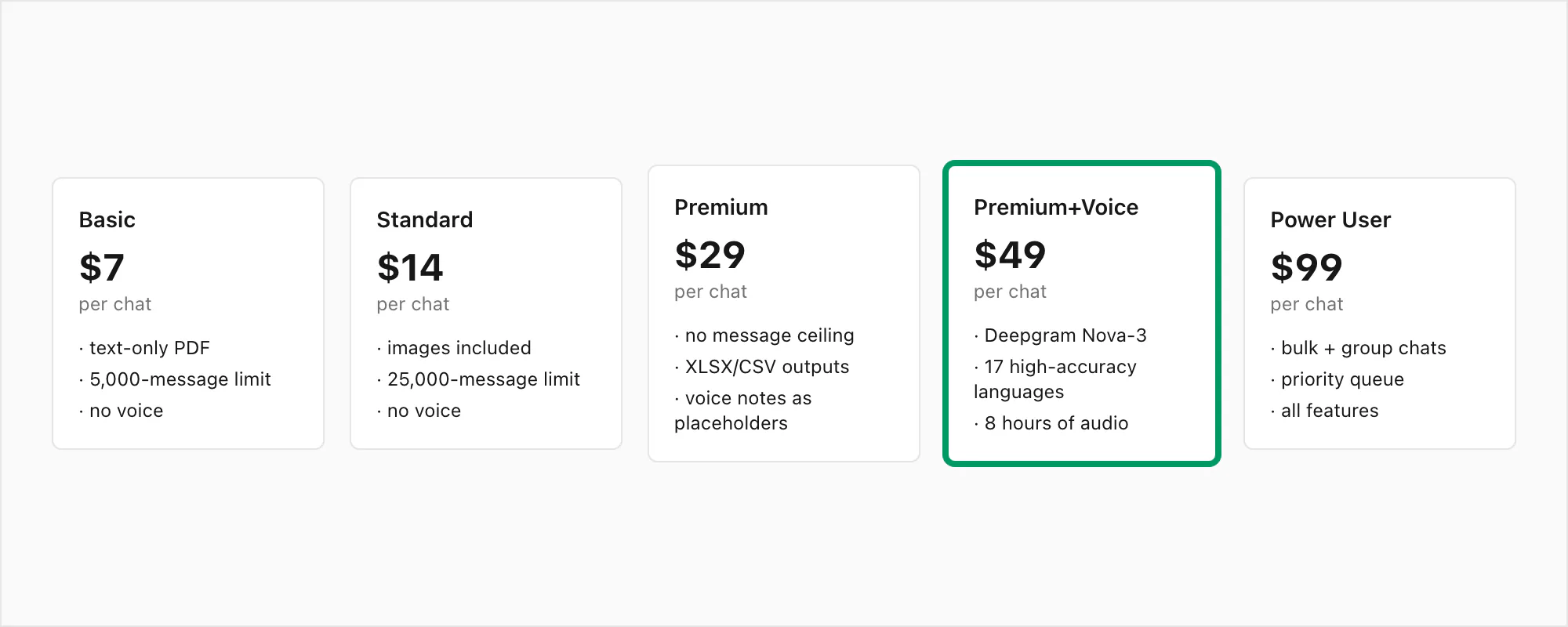
Reference के लिए, full tier stack: $7 Basic per chat conversion (text only, 5,000-message cap), $14 Standard per chat conversion (images, 25,000-message cap), $29 Premium per chat conversion (no cap, XLSX/CSV, voice notes preserved as placeholders), $49 Premium+Voice per chat conversion (Nova-3 transcription, 17-language high-accuracy, 8-hour audio cap), $99 Power User per chat conversion (Nova-3 transcription, no audio cap, priority queue, bulk scenarios)।
Real-time transcribe क्यों नहीं करता (और नहीं करूँगा)
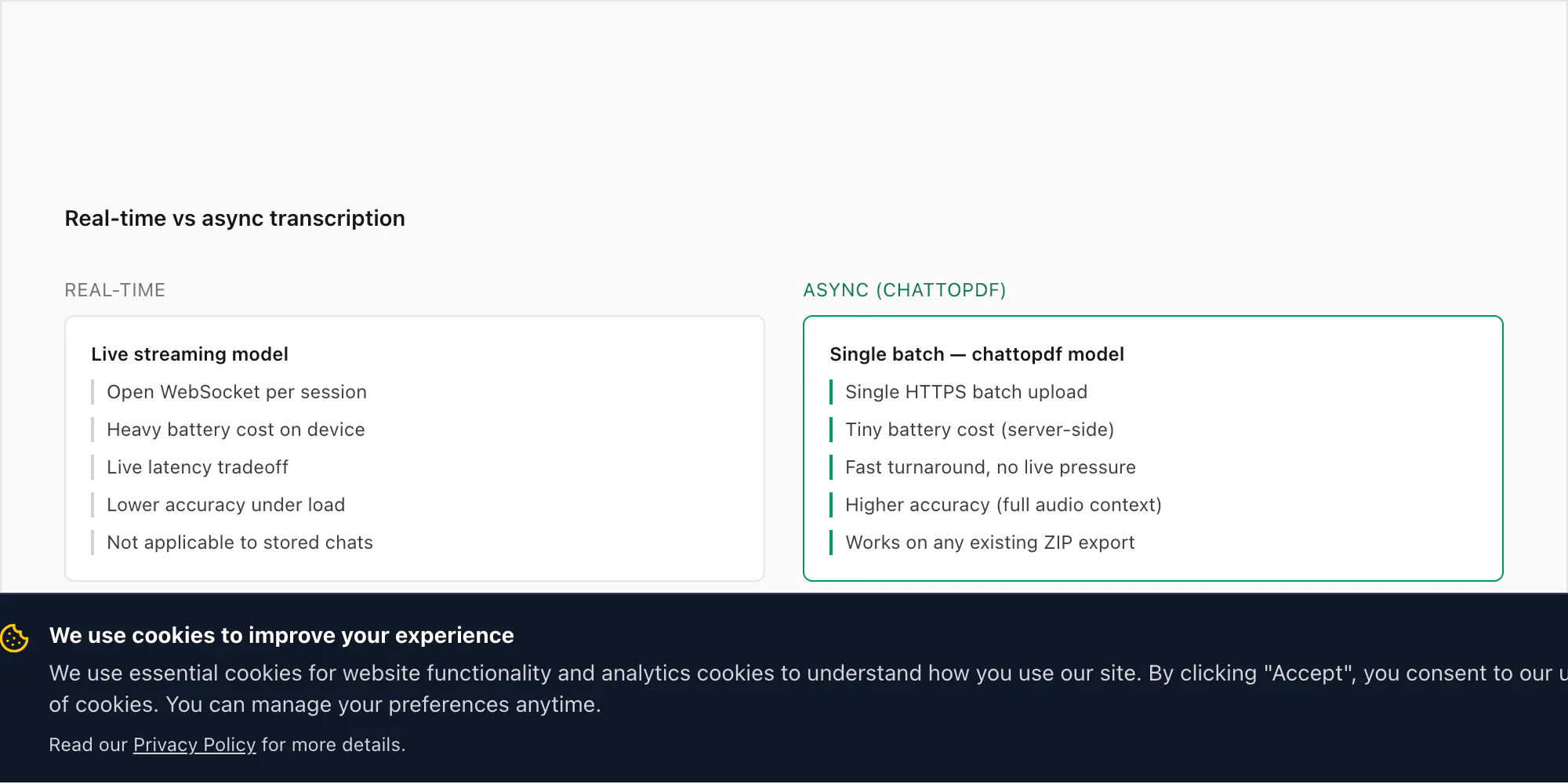
यह काफी often आता है कि इसका straight answer deserve करता है। लोग पूछते हैं कि ChatToPDF voice notes आने पर listen क्यों नहीं करता — हर एक को उसी moment transcribe करता जब send होती — ZIP export require करने की बजाय।
Short version: WhatsApp developers को incoming messages या audio real time में access नहीं देता। कोई official WhatsApp Business API endpoint नहीं है जो voice notes आने पर surface करे। WhatsApp पर real-time transcription build करने के लिए device पर app की local storage intercept करनी होगी, जो technically fragile और WhatsApp के platform policies से outside दोनों है।
लेकिन एक और practical reason है। WhatsApp audio transcribe करने का use case almost entirely retrospective है। कोई तीस voice notes receive करता है एक dispute के course में और readable record चाहता है। Business team voice notes project updates के लिए use करती है और उन्हें searchable चाहिए। Family phone upgrade से पहले archive करना चाहती है। इनमें से किसी में भी "right now, as it arrives" की ज़रूरत नहीं है।
Async batch processing ज़्यादा accurate भी है। Real-time speech-to-text latency constraints के तहत operate करती है जो model को faster (और less accurate) inference की तरफ push करती हैं। Deepgram का batch mode full audio file पर run होता है, जो model को future context use करने देता है। 30-second voice note पर real-time और batch modes के बीच WER में difference 2–4 percentage points हो सकता है।
Battery और network का सवाल भी है। एक open WebSocket connection जो real time में audio fragments stream करे battery को noticeably drain करेगी। इसे every received voice note के लिए active internet connection चाहिए होगी। और यह आपकी conversations का continuous data flow एक third-party server पर create करेगी — जो मैं users से accept करने के लिए comfortable नहीं हूँ।
Export-and-upload model clock time में slower है। लेकिन actual use cases के लिए, यह fine है।
Privacy: audio कहाँ जाता है और कहाँ नहीं
यह वह हिस्सा है जिसके बारे में मैं specific रहना चाहता हूँ क्योंकि voice notes की nature — real conversations की audio recordings — का मतलब है privacy stakes text messages से ज़्यादा ऊँचे हैं।
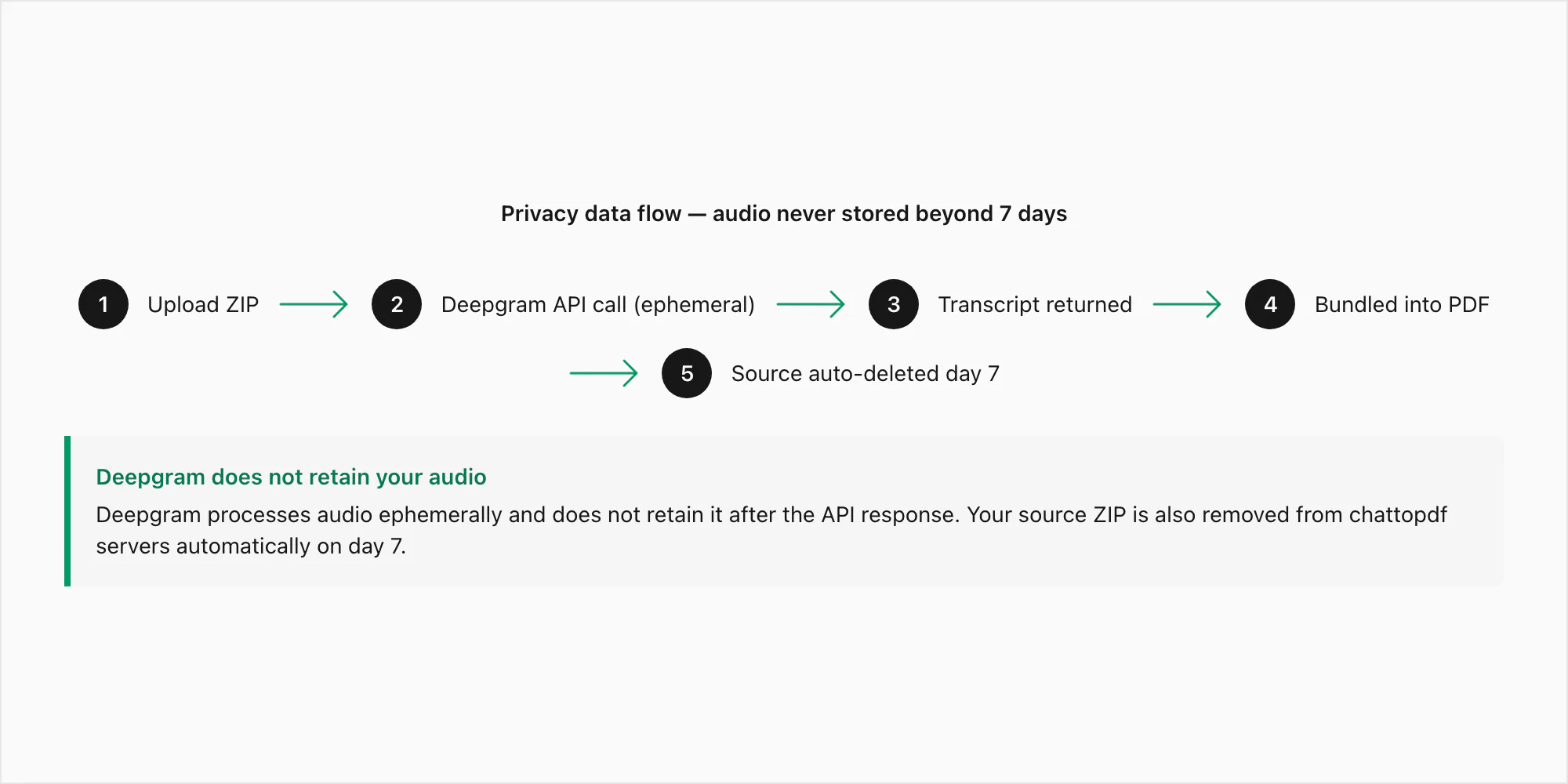
$49 Premium+Voice per chat conversion के ज़रिए submit किए गए voice note का exact data path:
Step 1 — Upload। आपकी ZIP file आपके browser से ChatToPDF के server पर HTTPS (TLS 1.3) के ज़रिए transmit होती है।
Step 2 — Extraction। .opus files ZIP से extract होती हैं। हर file को _chat.txt reference से filename pattern से match किया जाता है।
Step 3 — Deepgram API call। हर .opus file Deepgram के inference API पर authenticated HTTPS call के ज़रिए submit होती है। यह वह एकमात्र moment है जब audio bytes ChatToPDF के अपने infrastructure से बाहर जाते हैं। Deepgram की API submissions के लिए data policy specify करती है कि API के ज़रिए submit audio ephemerally process होती है — transcript generate करने के लिए use होती है और फिर discard होती है। Deepgram API-submitted audio retain नहीं करता और model training के लिए use नहीं करता।
Step 4 — Storage। Transcript PDF में bundle होकर AWS S3 पर AES-256 encryption के साथ stored होता है। Source ZIP, .opus files सहित, सात दिनों के लिए encrypted stored रहती है।
Step 5 — Delivery। PDF download link screen पर और email में appear करता है।
Step 6 — Auto-deletion। Job create होने के सात दिन बाद, source ZIP और output PDF automatically delete हो जाते हैं।
आपका audio कहाँ नहीं जाता: किसी analytics platform पर नहीं। ChatToPDF के models train करने के लिए नहीं (ChatToPDF models train नहीं करता)। ChatToPDF staff आपकी voice notes का text content देख नहीं सकता — processing fully automated है।
एकमात्र potential gap Deepgram step है। मैं ChatToPDF के servers पर क्या होता है पूरी तरह control कर सकता हूँ। Deepgram की internal processes के बारे में उनकी public data policy से परे representations नहीं कर सकता। अगर आपकी voice notes में legally privileged या genuinely classified information है, तो upload करने से पहले Deepgram के enterprise data processing terms review कराएं। Vast majority of use cases के लिए standard pipeline appropriate है।
Edge cases: background noise, multiple speakers, voice-changing effects
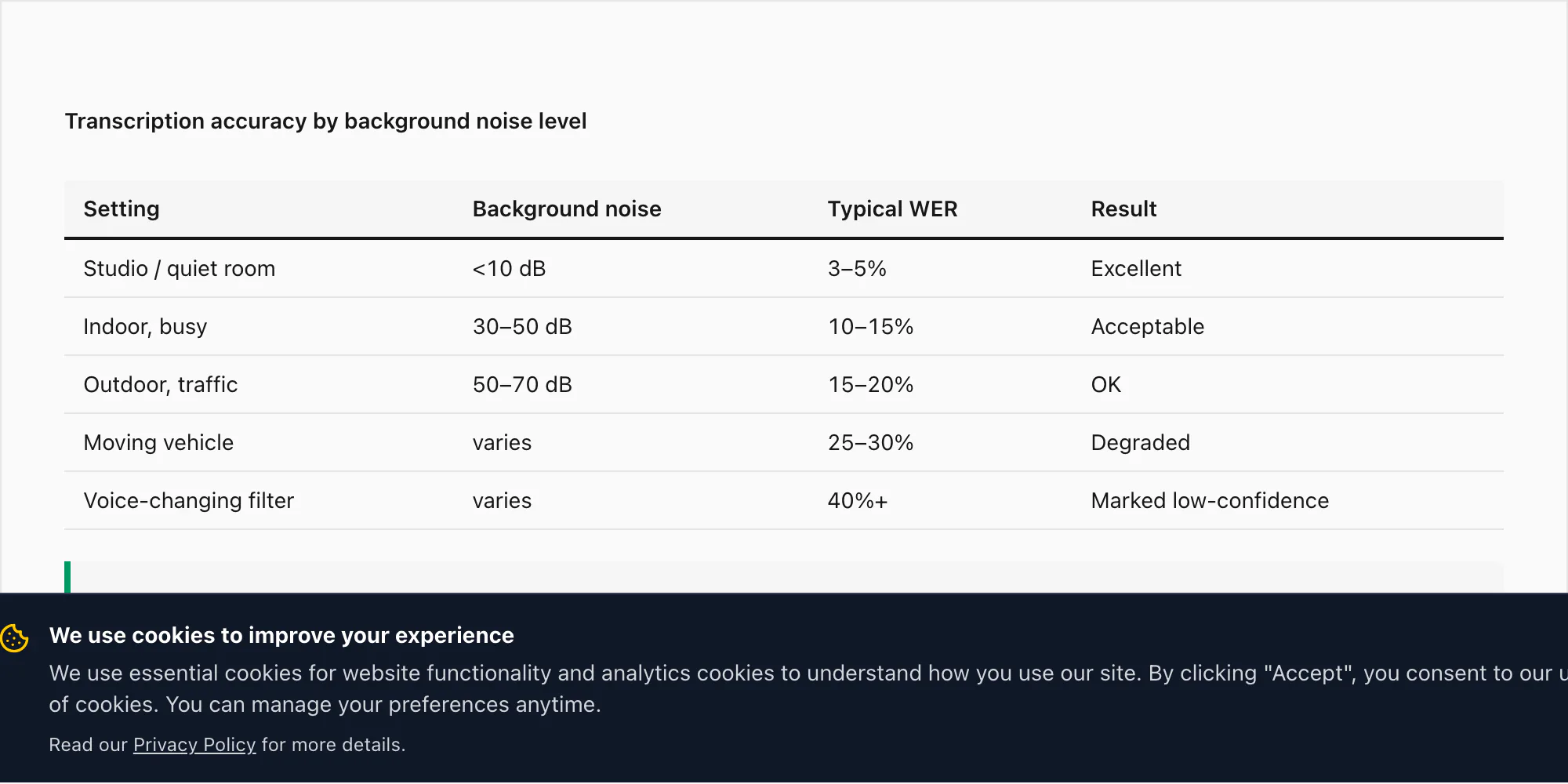
Real WhatsApp voice notes sound-proofed studios में record नहीं होतीं। वे cars, kitchens, street-level meetings और noisy cafés में record होती हैं। यहाँ हर scenario accuracy को कैसे affect करता है:
Environment के अनुसार background noise।
Quiet indoor environment में record — office, bedroom, still room — accuracy वैसी ही है जो मैंने language section में cite की: $49 Premium+Voice per chat conversion पर 17 high-accuracy languages के लिए 3–5% WER।
Busy indoor environment (restaurant, marketplace) $49 Premium+Voice per chat conversion पर WER को 10–15% तक raise कर सकती है। Deepgram का Nova-3 inference के दौरान noise cancellation apply करता है, जो help करता है, लेकिन competing audio का effect eliminate नहीं करता।
Outdoor recording — street noise, wind, traffic — same tier के लिए WER को 15–20% push कर सकती है।
Moving vehicle में record, road noise और engine sound के साथ, सबसे challenging scenario है। WER Nova-3 के साथ भी 25–30% तक पहुँच सकता है। यह transcription engine limitation नहीं है — यह 16 kHz पर phone mic पर captured audio की physics reflect करता है।
एक single voice note के अंदर multiple speakers।
जैसा earlier explain किया, हर WhatsApp voice note एक sender का है। ChatToPDF उस sender को transcript attribute करता है। लेकिन अगर sender background में किसी और की audible आवाज़ सुनते हुए record करे, Deepgram background voice भी transcribe करेगा। Transcript दोनों voices interleave करेगा, सभी WhatsApp sender को attributed।
ChatToPDF currently primary speaker isolate करके background voices discard नहीं कर सकता। Speaker diarisation एक feature है जिसे मैं future tier के लिए evaluate कर रहा हूँ।
Voice-changing effects।
कुछ WhatsApp users audio effects के साथ voice notes send करते हैं — WhatsApp का खुद का deep-voice filter (Android), या pitch-shifted audio। Deepgram का model natural speech पर trained है। Modified audio extreme cases में WER को 40% से ऊपर push कर सकता है।
Clips जहाँ confidence pipeline में मेरे set threshold से नीचे fall करती है — currently average word-confidence score 0.6 से कम के रूप में defined — ChatToPDF transcript को PDF में [low-confidence transcription — audio quality insufficient] के रूप में mark करता है text block output करने की बजाय जो authoritative लग सकता हो।
अक्सर पूछे जाने वाले सवाल
WhatsApp voice notes कौन-से file format use करती हैं, और क्या ChatToPDF इसे handle करता है?
WhatsApp voice notes Opus audio codec पर 16 kHz mono के रूप में record करता है, .opus files के रूप में save होती हैं। ChatToPDF .opus files को WhatsApp export ZIP से directly extract करता है और उन्हें Deepgram के inference API पर native format में submit करता है — कोई re-encoding step required नहीं। iPhone और Android exports दोनों .opus files produce करते हैं, इसलिए format handling दोनों platforms पर same है।
WhatsApp audio transcription कितनी accurate है?
Accuracy tier और audio quality पर depend करती है। $49 Premium+Voice per chat conversion Deepgram Nova-3 use करता है, जो 17 supported high-accuracy languages में clean, noise-free audio पर approximately 3–5% word error rate achieve करता है। $99 Power User per chat conversion same Nova-3 model को बिना audio cap और priority queue processing के साथ use करता है। $29 Premium per chat conversion transcribe नहीं करता — यह voice notes को PDF में placeholder references के रूप में preserve करता है। Low-confidence clips (0.6 से कम average word-confidence score) को PDF में [low-confidence transcription] के रूप में mark किया जाता है potentially misleading transcript present करने की बजाय।
क्या ChatToPDF English के अलावा languages में voice notes transcribe करता है?
हाँ। $49 Premium+Voice per chat conversion और $99 Power User per chat conversion 17 high-accuracy languages support करते हैं: English, Spanish, Portuguese, French, German, Italian, Arabic, Hindi, Indonesian, Turkish, Russian, Dutch, Japanese, Korean, Chinese, Vietnamese और Thai। दोनों tiers इन languages में Deepgram Nova-3 use करते हैं और wider accuracy range पर 30+ additional languages detect करते हैं। Language automatically detected होती है — upload से पहले specify नहीं करना। $29 Premium per chat conversion voice notes transcribe नहीं करता।
क्या voice transcripts चाहिए तो WhatsApp से export करने में कुछ अलग करना होगा?
हाँ — एक critical step। WhatsApp से chat export करते समय "Without Media" की बजाय "Including Media" चुनें। Voice notes (.opus files) export में सिर्फ तब include होती हैं जब Including Media select किया हो। अगर Without Media export किया, तो _chat.txt में references जैसे <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> होंगे लेकिन actual audio files नहीं। ChatToPDF voice note transcribe नहीं कर सकता जो उसके पास है ही नहीं। Full step-by-step export process के लिए WhatsApp chat export guide देखें।
क्या voice transcripts PDF में सही जगह appear होंगे?
हाँ। ChatToPDF _chat.txt में message log read करके conversation structure समझता है, filename से हर .opus reference को corresponding audio file से match करता है, और transcript को conversation में exactly उस position पर insert करता है जहाँ voice note send हुई थी। WhatsApp metadata का sender name और original timestamp दोनों transcript के साथ appear करते हैं।
Transcription complete होने के बाद audio files का क्या होता है?
आपकी audio files job create होने के सात दिन बाद ChatToPDF के servers पर encrypted at rest (AES-256) stored रहती हैं, फिर automatically delete हो जाती हैं। Audio bytes receive करने वाली एकमात्र third-party service Deepgram है, और सिर्फ transcription step के दौरान — Deepgram API के ज़रिए submit audio को ephemerally process करता है और retain नहीं करता। कोई human आपकी recordings नहीं सुनता।
क्या ChatToPDF same voice note में दो अलग-अलग लोगों को पहचान सकता है?
Currently नहीं। हर WhatsApp voice note उसे send करने वाले को attributed है, _chat.txt के sender information से। एक single voice note के अंदर, अगर sender और कोई दूसरा व्यक्ति दोनों बोलते हैं, तो दोनों voices transcribe होती हैं लेकिन WhatsApp sender को attributed। ChatToPDF currently individual audio clips के अंदर speaker diarisation run नहीं करता।
WhatsApp voice message ko text mein kaise convert kare?
WhatsApp voice notes को text में convert करने के लिए: chat को Including Media के साथ export करें (ताकि .opus audio files ZIP में आएं), फिर chattopdf.app पर upload करके $49 Premium+Voice tier चुनें। हर voice note conversation में अपनी सही जगह पर — sender का नाम और timestamp के साथ — readable text बन जाता है। 17 languages high accuracy पर, और Hindi (और Hinglish mixed) भी support है। WhatsApp का अपना built-in transcription एक-एक message ही करता है और export नहीं होता — पूरी chat एक साथ text में चाहिए तो यही सही तरीका है।
WhatsApp voice message ko download ya save kaise kare?
एक-दो voice messages के लिए: message को long-press करके Forward/Share से खुद को email कर लें, या Android पर file manager में WhatsApp/Media/WhatsApp Voice Notes folder से .opus files copy करें। पूरी chat की सारी voice notes एक साथ चाहिए तो chat को Export Chat → Include Media से export करें — ZIP के अंदर हर voice note .opus file के रूप में आ जाती है। ध्यान रहे .opus हर music player में नहीं चलती। अगर आवाज़ों को संभालकर रखना है तो chattopdf.app का $49 Premium+Voice tier हर voice note को PDF में उसकी जगह पर text बनाकर भी रख देता है — यानी बोली हुई बात पढ़ने लायक record बन जाती है, audio files अपने पास अलग रहती हैं।
Key takeaways
- WhatsApp audio transcribe करने के लिए, "Including Media" select करके chat export करें —
.opusvoice note files ZIP के अंदर होनी चाहिए - $29 Premium per chat conversion transcribe नहीं करता — voice notes को placeholder references preserve करता है; $49 Premium+Voice per chat conversion Deepgram Nova-3 चलाता है (clean audio पर 3–5% WER, 17 high-accuracy languages, 8 hours audio तक); $99 Power User same model uncapped और priority queue के साथ
- हर transcript conversation में exact position पर insert होता है WhatsApp sender के name और original timestamp के साथ
- Hinglish जैसी code-switching languages के लिए $49 Premium+Voice per chat conversion या higher चाहिए — Nova-3 Hindi voice notes में mid-sentence English insertions पर older STT engines के gap को mostly close करता है
- Background noise सबसे बड़ा accuracy variable है: studio conditions में 3–5% WER; outdoor या vehicle recordings में Nova-3 के साथ भी 20–30% WER
- Transcription के लिए Deepgram को submit audio ephemerally processed होती है — retained नहीं, training के लिए use नहीं; source files ChatToPDF servers से 7 दिन बाद auto-delete होती हैं
- जिन clips में average word-confidence 0.6 से कम हो उन्हें PDF में
[low-confidence transcription]mark किया जाता है silent incorrect transcript return करने की बजाय
Full chat-to-PDF workflow के लिए — iPhone और Android पर export कैसे करें, ZIP में क्या है, और सभी पाँच tiers non-voice conversions के लिए कैसे compare करते हैं — WhatsApp to PDF guide देखें। Android पर हैं और upload से पहले export को दूसरे device पर move करना है, तो WhatsApp Android to iPhone transfer guide वह process cover करती है।
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).