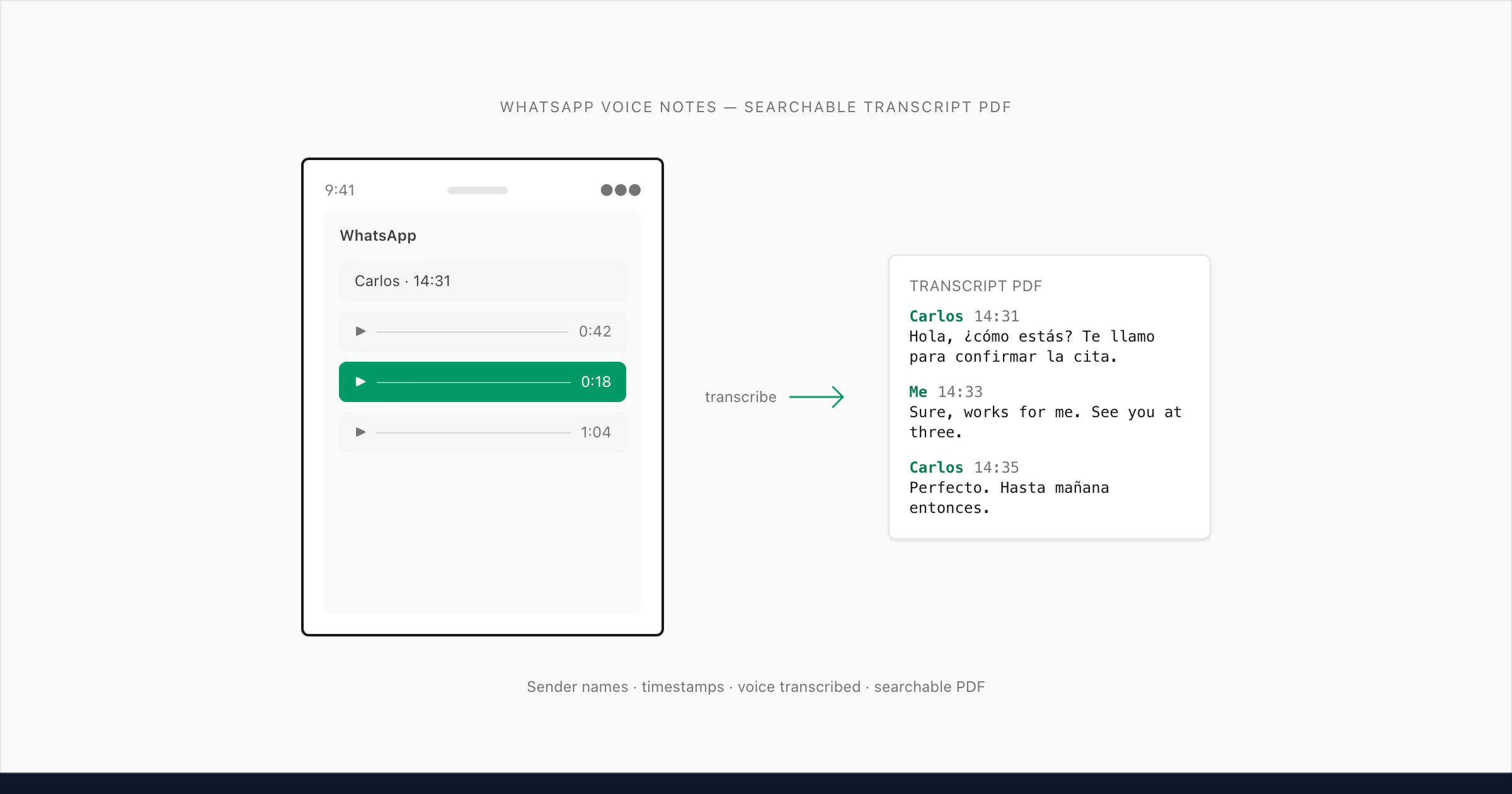
Apa yang sebenarnya dimaksud "transcribe WhatsApp audio" (dan mengapa lebih rumit dari kedengarannya)
Orang menggunakan frasa "transcribe WhatsApp audio" untuk setidaknya tiga hal yang berbeda. Sebagian ingin mentranskripsikan panggilan suara langsung — yang tidak diekspos WhatsApp melalui API developer mana pun dan secara teknis adalah kategori produk terpisah dari yang saya jelaskan di sini. Sebagian lagi ingin mengubah file audio yang mereka simpan dari WhatsApp menjadi teks, memperlakukan file .opus sebagai input mandiri. Dan sebagian lagi — kelompok terbesar — ingin setiap catatan suara dalam chat WhatsApp yang diekspor dikonversi menjadi teks yang bisa dibaca sehingga seluruh percakapan masuk akal sebagai sebuah dokumen.
ChatToPDF dibangun untuk kasus penggunaan ketiga itu. Masalah yang dipecahkannya spesifik: Anda mengekspor chat WhatsApp yang berisi pesan teks dan catatan suara, dan yang Anda terima kembali dari WhatsApp adalah ZIP berisi _chat.txt dan folder file media. File _chat.txt memiliki baris seperti <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> di mana catatan suara seharusnya berada. Tidak ada yang mengubahnya menjadi teks yang bisa dibaca kecuali Anda membangun sesuatu untuk itu.
Inilah bagian yang tidak ada yang beritahukan: bahkan ketika orang menemukan alat transkripsi, mereka sering menghadapi masalah struktural. Alat yang menangani file audio generik — unggah MP3, dapatkan teks kembali — tidak tahu di mana dalam percakapan audio itu termasuk. Mereka mentranskripsikan file tapi kehilangan konteksnya. Anda berakhir dengan blok teks terpisah tanpa nama pengirim, tanpa cap waktu, tanpa indikasi apa yang dikatakan sebelum atau sesudahnya. Untuk keperluan hukum, catatan bisnis, atau arsip keluarga, konteks itulah yang menjadi inti masalahnya.
Yang saya bangun melakukan hal berikut (that's me, Paul — I built ChatToPDF to solve exactly this): membaca _chat.txt untuk memahami struktur percakapan, mencocokkan setiap referensi .opus ke file audio yang tepat dalam ZIP, mentranskripsikan audio, dan menyisipkan transkrip kembali pada posisi yang tepat dalam percakapan — dengan nama pengirim dan cap waktu asli tetap terjaga. Hasilnya adalah satu PDF di mana pesan teks dan transkrip catatan suara bergantian secara alami, persis seperti percakapan berlangsung.
Itulah masalah yang dibahas panduan ini.
Catatan suara bukan file — melainkan stream dalam aplikasi
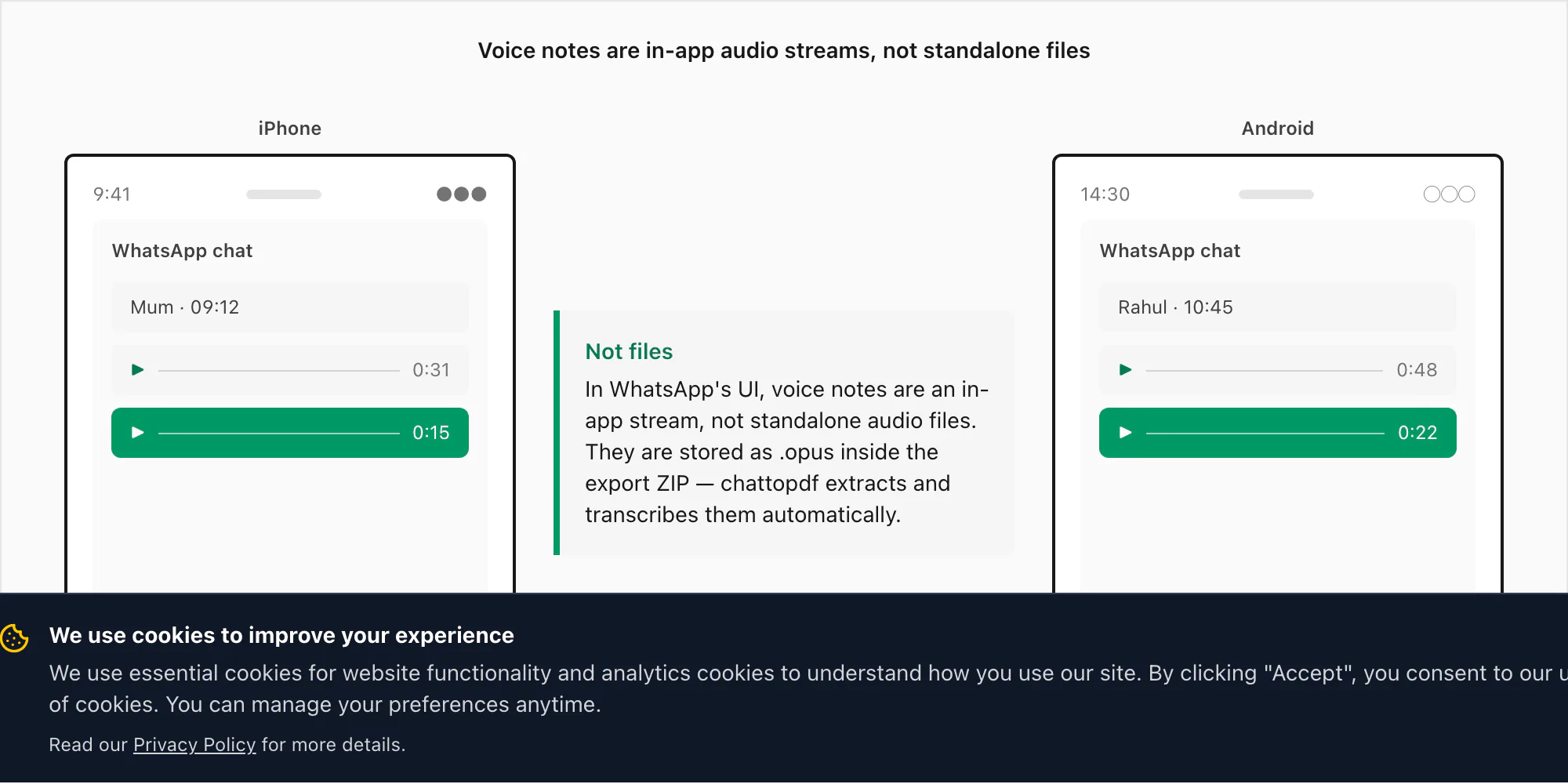
Catatan suara WhatsApp tampak seperti file audio di dalam aplikasi — bilah gelombang, durasi, tombol putar — tapi tidak disimpan seperti yang kebanyakan orang harapkan. Saat Anda merekam catatan suara di WhatsApp dengan menahan tombol mikrofon, WhatsApp mengodekan audio menggunakan codec Opus dan menyimpannya sebagai file .opus di direktori privat di perangkat Anda. Direktori itu tidak dapat diakses melalui penelusuran file normal di iPhone maupun Android. Anda tidak bisa menavigasi ke sana di aplikasi Files dan menemukan catatan suara Anda di sana.
Satu-satunya cara untuk mengekstrak file .opus tersebut adalah melalui menu Ekspor Chat WhatsApp sendiri, dengan "Sertakan Media" dipilih. Saat Anda mengekspor dengan cara itu, WhatsApp mengemas log pesan _chat.txt bersama folder media — dan di sanalah file .opus muncul. Di iOS, file-file tersebut masuk ke dalam ZIP. Di Android, versi WhatsApp yang lebih lama mengekspor ke folder di penyimpanan internal; versi yang lebih baru membuat ZIP melalui share sheet, sama seperti perilaku iOS.
Codec Opus itu sendiri perlu dipahami sekilas karena menjelaskan mengapa akurasi bisa bervariasi. Opus dirancang untuk voice-over-IP — latensi rendah, kompresi baik, kualitas baik bahkan pada bitrate rendah. WhatsApp menggunakan audio mono 16 kHz pada sekitar 16 kbps. File yang dihasilkan sangat kecil: catatan suara 60 detik biasanya berbobot antara 80 KB dan 120 KB. Ini efisien untuk data seluler, tapi 16 kHz mono pada 16 kbps bukan audio berkualitas studio. Dioptimalkan untuk kejelasan melalui koneksi seluler, bukan untuk akurasi transkripsi. Kebisingan latar, suara yang direkam saat berkendara, atau seseorang berbicara dari seberang ruangan dapat mendorong kualitas efektif lebih jauh ke bawah.
Inilah mengapa model transkripsi sangat penting. Mesin speech-to-text generik yang dilatih pada audio studio atau rekaman podcast akan kesulitan dengan Opus mono 16 kHz yang dikompres pada 16 kbps. Mesin yang saya pilih dipilih secara khusus karena menangani jenis audio ini dengan baik. Lebih lanjut tentang itu di bagian berikutnya.
Satu poin struktural lagi: setiap catatan suara WhatsApp adalah rekaman satu pengirim. Model push-to-talk WhatsApp berarti satu orang merekam, lalu berhenti, lalu orang lain merekam balasannya. Ini sebenarnya adalah keuntungan transkripsi — tidak seperti panggilan telepon yang direkam di mana dua suara tumpang tindih pada trek audio yang sama, setiap file .opus dalam ekspor WhatsApp milik tepat satu pengirim. ChatToPDF menggunakan metadata dari _chat.txt untuk mengaitkan setiap transkrip ke orang yang tepat, itulah cara Anda mendapatkan percakapan yang terbaca jelas bahkan ketika kedua orang bergiliran dalam catatan suara.
Mesin transkripsi yang saya pilih, dan alasannya
Saya mengevaluasi beberapa API transkripsi sebelum memilih Deepgram sebagai mesin di balik transkripsi suara ChatToPDF. Pesaing serius lainnya adalah AssemblyAI, Whisper (model open-source OpenAI), dan beberapa API speech generik dari penyedia cloud. Berikut alasan jujur di balik pilihan saya.
Whisper mengesankan untuk model gratis, tapi saya menjalankan tes akurasi pada sekumpulan file .opus WhatsApp sungguhan dalam Bahasa Inggris, Spanyol, Hindi, dan Arab, dan menunjukkan kelemahan konsisten pada alih kode (catatan suara yang mencampur dua bahasa di tengah kalimat) dan pada aksen non-AS Inggris. Ia juga tidak menawarkan SLA komersial atau jaminan uptime, yang penting ketika pengguna berbayar sedang menunggu hasilnya.
AssemblyAI sungguh baik dan saya menggunakannya dalam prototipe awal. Akurasi pada Bahasa Inggris sebanding dengan Deepgram, tapi keluasan dukungan bahasa dan konsistensi respons API pada audio berkode Opus pada 16 kHz mono membuat Deepgram menjadi pilihan yang lebih baik untuk kasus penggunaan multibahasa yang saya bangun.
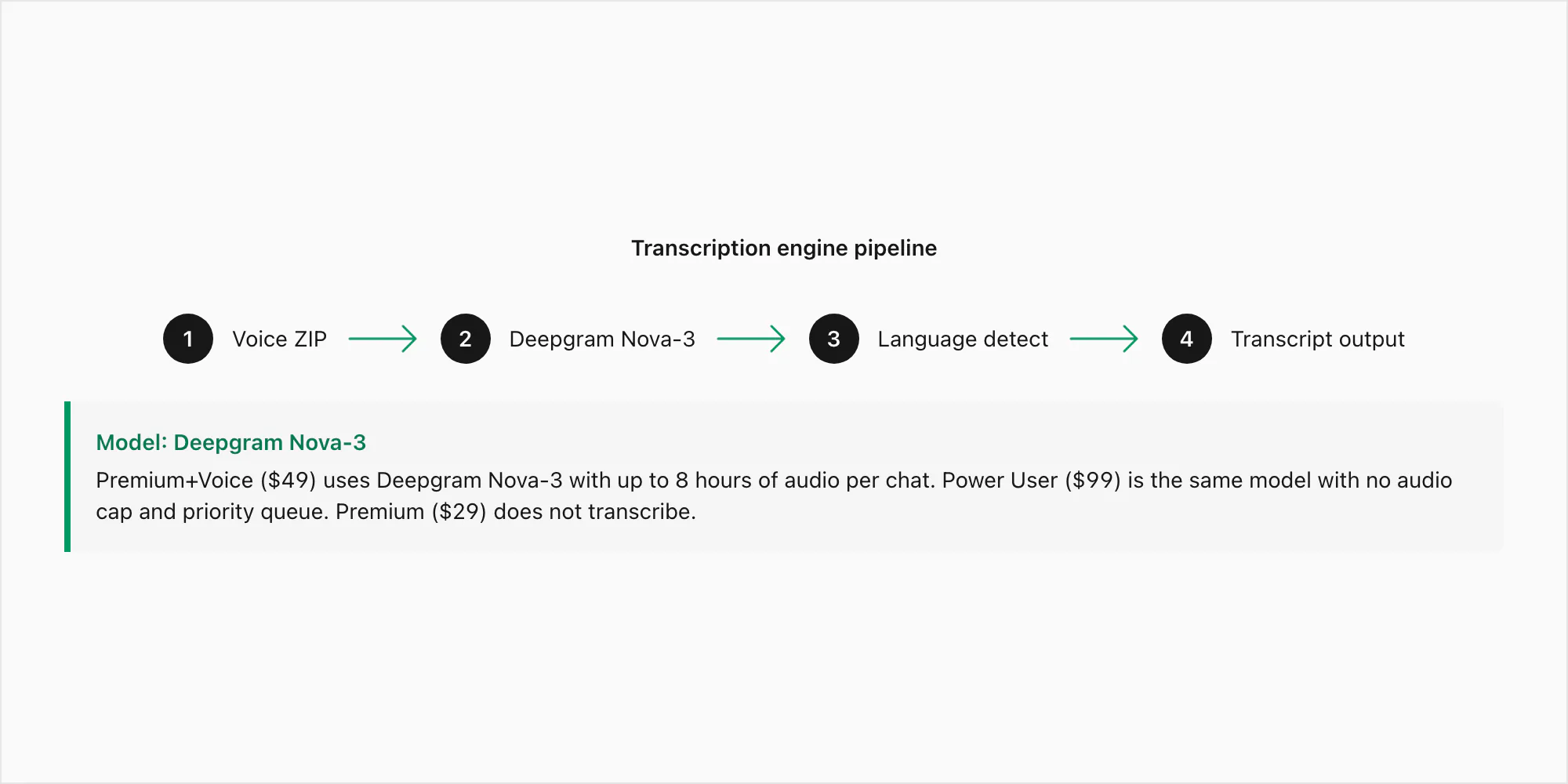
Deepgram Nova-3 adalah model generasi terkini dengan word error rate sekitar 3–5% pada audio bersih dan bebas kebisingan dalam Bahasa Inggris, dan 8–15% pada rekaman yang lebih berisik. Angka-angka tersebut bertahan pada Opus mono 16 kHz, yang merupakan format yang penting untuk ekspor WhatsApp. Nova-3 adalah model yang digunakan untuk konversi $49 Premium+Voice per chat dan konversi $99 Power User per chat — perbedaan antara dua tier tersebut adalah batas audio (8 jam vs tidak terbatas) dan prioritas antrian, bukan modelnya.
Di mana Nova-3 secara nyata mengungguli mesin speech-to-text yang lebih lama adalah di tiga tempat: aksen regional (Inggris Afrika Selatan, Inggris India, Portugis Brasil), kosakata teknis (nama, alamat, istilah produk yang mungkin salah didengar oleh model generik), dan audio beralih kode di mana pembicara berpindah antara bahasa dalam satu catatan suara. Itulah mode kegagalan spesifik yang memotivasi pilihan mesin. Konversi $29 Premium per chat tidak menyertakan transkripsi sama sekali — ia menyimpan catatan suara sebagai referensi placeholder dalam PDF tanpa menjalankan audio melalui model mana pun.
Pipeline bekerja seperti ini: ZIP Anda tiba di server ChatToPDF, file .opus diekstrak, masing-masing dikirimkan ke API Deepgram melalui panggilan HTTPS terautentikasi dengan deteksi bahasa disetel ke otomatis, dan transkrip kembali — biasanya dalam dua hingga lima detik per menit audio. Transkrip kemudian dijahit kembali ke dalam percakapan pada posisi yang tepat sebelum PDF dirender.
Satu pilihan disengaja dalam pipeline: saya tidak melakukan pra-pemrosesan atau pengkodean ulang audio .opus sebelum mengirimkannya ke Deepgram. Beberapa alat mengonversi Opus ke WAV atau MP3 terlebih dahulu, dengan alasan bahwa format yang berbeda mungkin meningkatkan akurasi. Dalam praktiknya, API Deepgram menangani Opus secara native dan mengonversi menambahkan latensi tanpa meningkatkan hasil pada jenis audio ini. File .opus mentah langsung dikirim ke endpoint inferensi.
Akurasi pada 17 bahasa yang didukung ChatToPDF saat ini
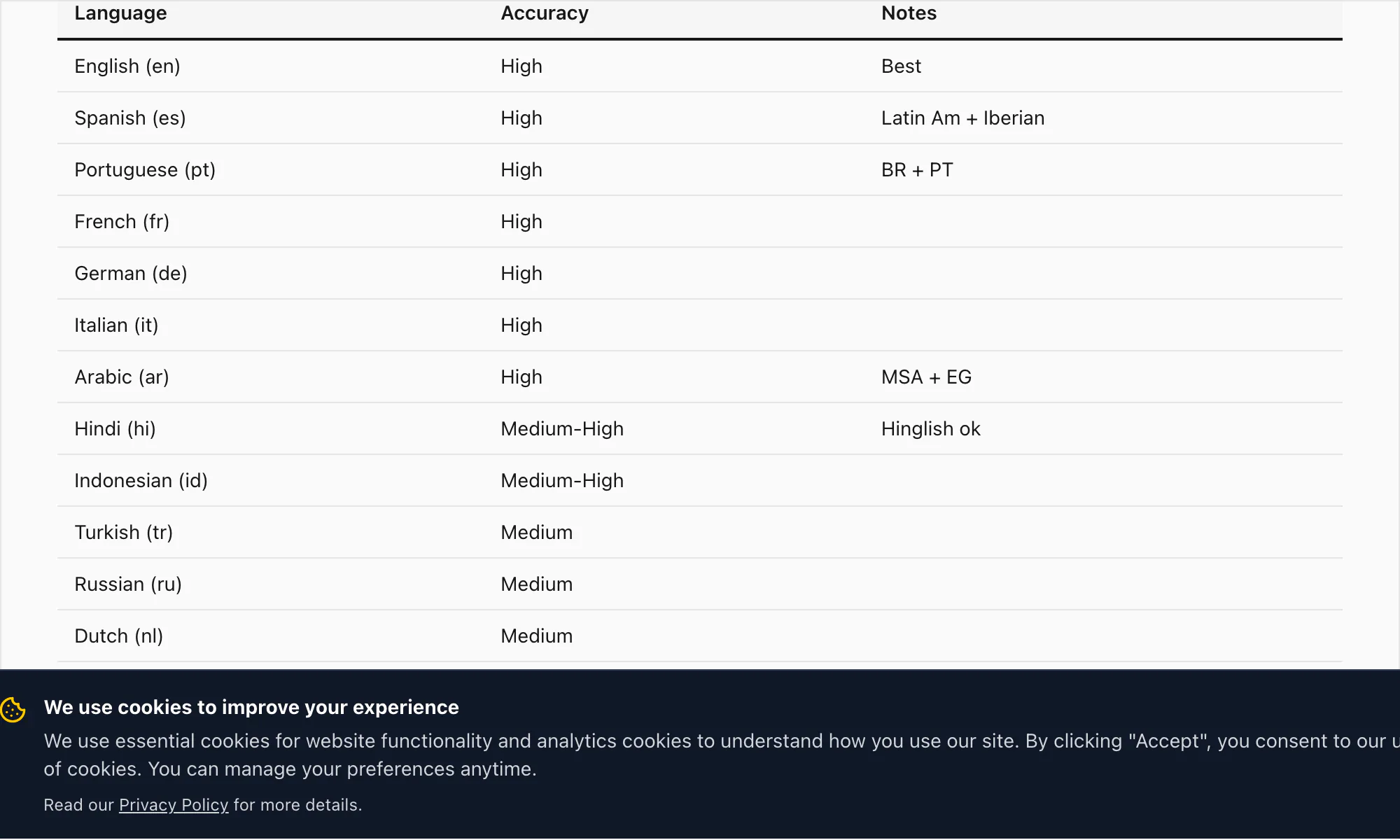
Tier bahasa akurasi tinggi ChatToPDF mencakup 17 bahasa. Inilah bahasa-bahasa yang kualitas transkripsinya cukup saya percaya untuk menyebutnya siap produksi untuk dokumen, catatan hukum, dan penggunaan bisnis:
Bahasa Inggris (en) — WER 3–5% pada audio bersih. Mencakup varian Inggris Britania, AS, Australia, Afrika Selatan, dan India. Semua varian Bahasa Inggris ditangani oleh model Nova-3 yang sama pada konversi $49 Premium+Voice per chat.
Bahasa Spanyol (es) — WER 4–6% pada konversi $49 Premium+Voice per chat. Menangani varian Amerika Latin dan Kastilia. Kebingungan homonim umum (haya/halla, tubo/tuvo) sebagian dimitigasi oleh inferensi konteks.
Bahasa Portugis (pt) — WER 4–7%. Mencakup Portugis Brasil dan Eropa. Alih kode antara Portugis dan Inggris adalah pola umum dalam chat WhatsApp Brasil; Nova-3 menangani ini dengan baik.
Bahasa Prancis (fr) — WER 4–6%. Prancis standar dan Kanada.
Bahasa Jerman (de) — WER 4–6%. Kata majemuk ditranskripsikan secara akurat pada Nova-3, termasuk bentuk majemuk panjang yang khas dalam kosakata bisnis dan hukum.
Bahasa Italia (it) — WER 5–7%.
Bahasa Arab (ar) — WER 7–10%. Bahasa Arab Standar Modern ditranskripsikan dengan baik; Arab dialek (Mesir, Teluk, Levant) memiliki variasi lebih lebar. Konversi $49 Premium+Voice per chat adalah tier yang direkomendasikan untuk catatan suara bahasa Arab.
Bahasa Hindi (hi) — WER 6–9% pada Hindi murni. Hinglish yang beralih kode (Hindi dengan sisipan Inggris) adalah tempat Nova-3 membuat perbedaan terbesar dibanding mesin transkripsi yang lebih lama — lebih lanjut tentang ini di bagian contoh transkrip di bawah.
Bahasa Indonesia (id) — WER 5–8%. Salah satu bahasa paling umum dalam basis pengguna ChatToPDF, mengingat penetrasi WhatsApp yang tinggi di Asia Tenggara.
Bahasa Turki (tr) — WER 5–8%.
Bahasa Rusia (ru) — WER 5–8%.
Bahasa Belanda (nl) — WER 4–6%.
Bahasa Jepang (ja) — WER 7–10%. Kata pinjaman katakana dan nama diri dapat menimbulkan kesalahan; akurasi keseluruhan kuat untuk percakapan sehari-hari.
Bahasa Korea (ko) — WER 6–9%.
Bahasa Mandarin (zh) — WER 7–10%. Dialek regional dan homonim tonal dapat memengaruhi akurasi pada rekaman yang menantang.
Bahasa Vietnam (vi) — WER 7–10%.
Bahasa Thai (th) — WER 8–12%. Tanda nada dan gugus konsonan dalam ucapan cepat adalah tantangan utama.
Di luar 17 bahasa ini, Deepgram Nova-3 mendukung 30+ bahasa tambahan dengan rentang akurasi yang lebih lebar. Jika bahasa Anda tidak ada dalam daftar akurasi tinggi di atas, konversi $49 Premium+Voice per chat tetap menghasilkan transkrip terbaik menggunakan deteksi bahasa yang lebih luas dari Nova-3 — cukup ekspektasikan akurasi lebih dekat ke 15–20% WER pada audio yang menantang dalam bahasa tingkat bawah.
Deteksi bahasa otomatis aktif secara default. ChatToPDF mengirimkan setiap file .opus ke Deepgram tanpa menentukan bahasa, dan Deepgram mendeteksi bahasa dominan dalam beberapa detik pertama. Ini akurat untuk rekaman satu bahasa. Untuk alih kode yang berat — catatan suara yang benar-benar 50/50 dua bahasa — detektor memilih satu sebagai utama dan menerapkan model itu ke seluruh klip. Anda akan melihat beberapa kehilangan akurasi pada bahasa sekunder dalam kasus tersebut.
Contoh transkrip: catatan suara Spanyol → teks (contoh nyata)
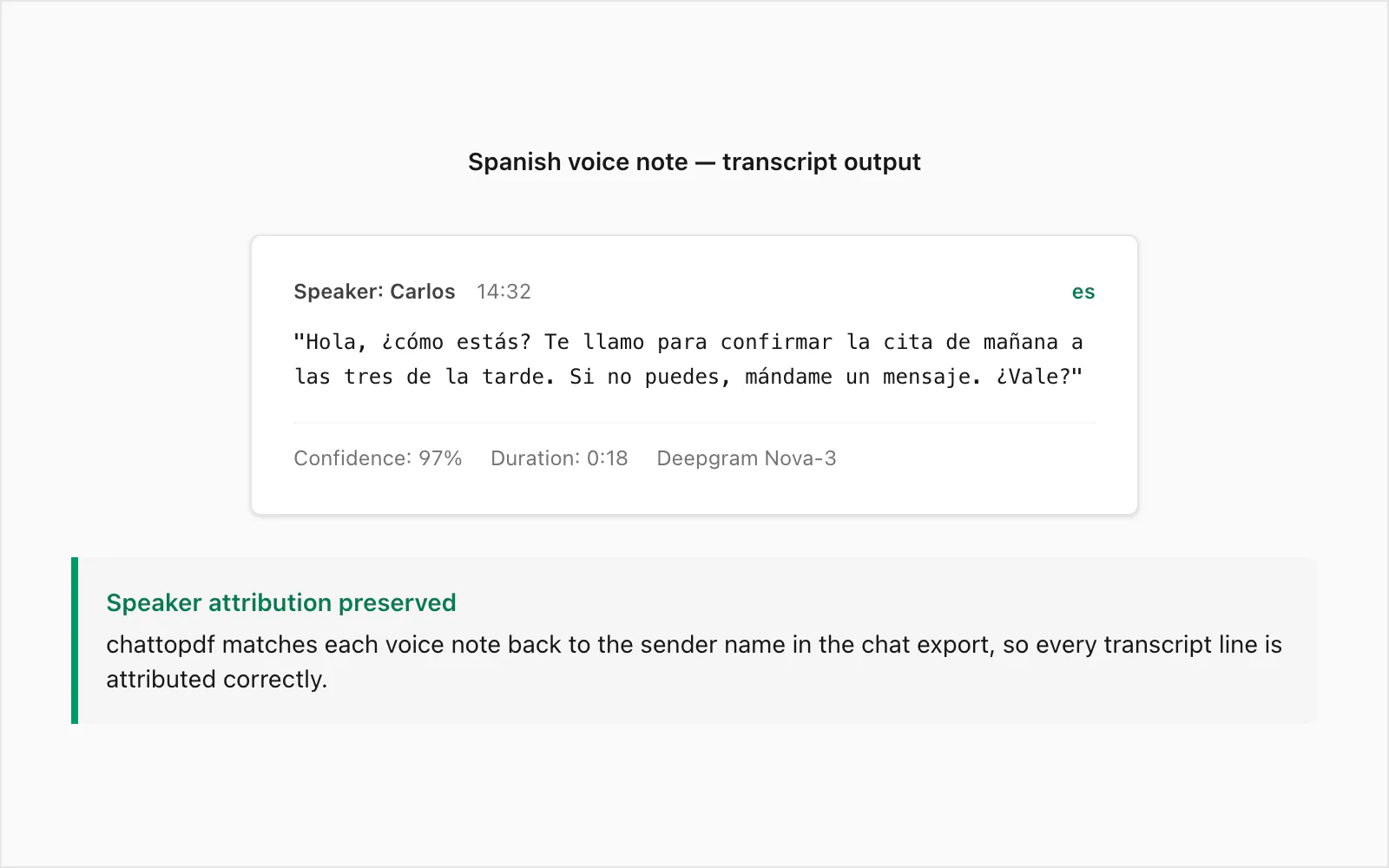
Ini adalah catatan suara WhatsApp nyata yang ditranskripsikan pada level konversi $49 Premium+Voice per chat. Pengirim adalah penutur asli Spanyol Kolombia, direkam di perangkat Android dalam lingkungan dalam ruangan yang tenang. Durasi: 18 detik. Ukuran file: sekitar 28 KB dalam format .opus.
Audio asli (parafrase): Catatan suara kasual yang mengonfirmasi janji hari berikutnya, mengungkapkan kekhawatiran tentang kesehatan orang lain, dan meminta balasan teks jika rencana berubah.
Output transkrip dalam PDF:
🎤 [Catatan suara — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
Pengirim ditribusikan dalam PDF dengan nama dari _chat.txt, cap waktu adalah yang direkam WhatsApp saat catatan suara dikirim, dan transkrip berada inline di antara pesan teks tepat sebelum dan sesudahnya dalam percakapan.
Beberapa hal yang perlu diperhatikan dari contoh ini. Penanda register formal ¿Vale? — lebih dekat ke "Oke?" atau "Baik?" dalam arti — ditranskripsikan dengan benar alih-alih dikacaukan dengan bale atau dihilangkan. Ekspresi waktu a las tres de la tarde ("pukul tiga sore") dirender secara akurat, yang penting untuk konfirmasi penjadwalan di mana kesalahan akan menyesatkan. Infleksi naik yang diucapkan pada ¿cómo estás? tidak cukup ambigu untuk menghasilkan kesalahan transkripsi.
Di mana akurasi Spanyol tidak berjalan baik? Kesalahan paling umum yang saya lihat adalah homonim: haya (subjunctive dari haber) versus halla (dari hallar, untuk menemukan), tubo (tabung) versus tuvo (past tense dari tener). Dalam ucapan kasual yang cepat, keduanya identik secara fonetis. Nova-3 menggunakan konteks sekitarnya untuk menyimpulkan ejaan yang benar sebagian besar waktu, tapi tidak sempurna. Dalam dokumen yang akan digunakan sebagai catatan hukum, saya merekomendasikan tinjauan manusia ringan terhadap catatan suara mana pun di mana transkrip akan dikutip secara verbatim.
Jika Anda tidak membutuhkan transkripsi sama sekali — misalnya, Anda hanya ingin pesan teks dikonversi ke PDF dan puas dengan referensi placeholder untuk catatan suara — konversi $29 Premium per chat menangani kasus tersebut dengan harga lebih rendah. Konversi $49 Premium+Voice per chat adalah langkah yang tepat ketika Anda membutuhkan ucapan Spanyol yang sebenarnya muncul sebagai teks yang bisa dibaca dalam dokumen.
Contoh transkrip: Hindi (campuran Hinglish) → teks (contoh nyata)
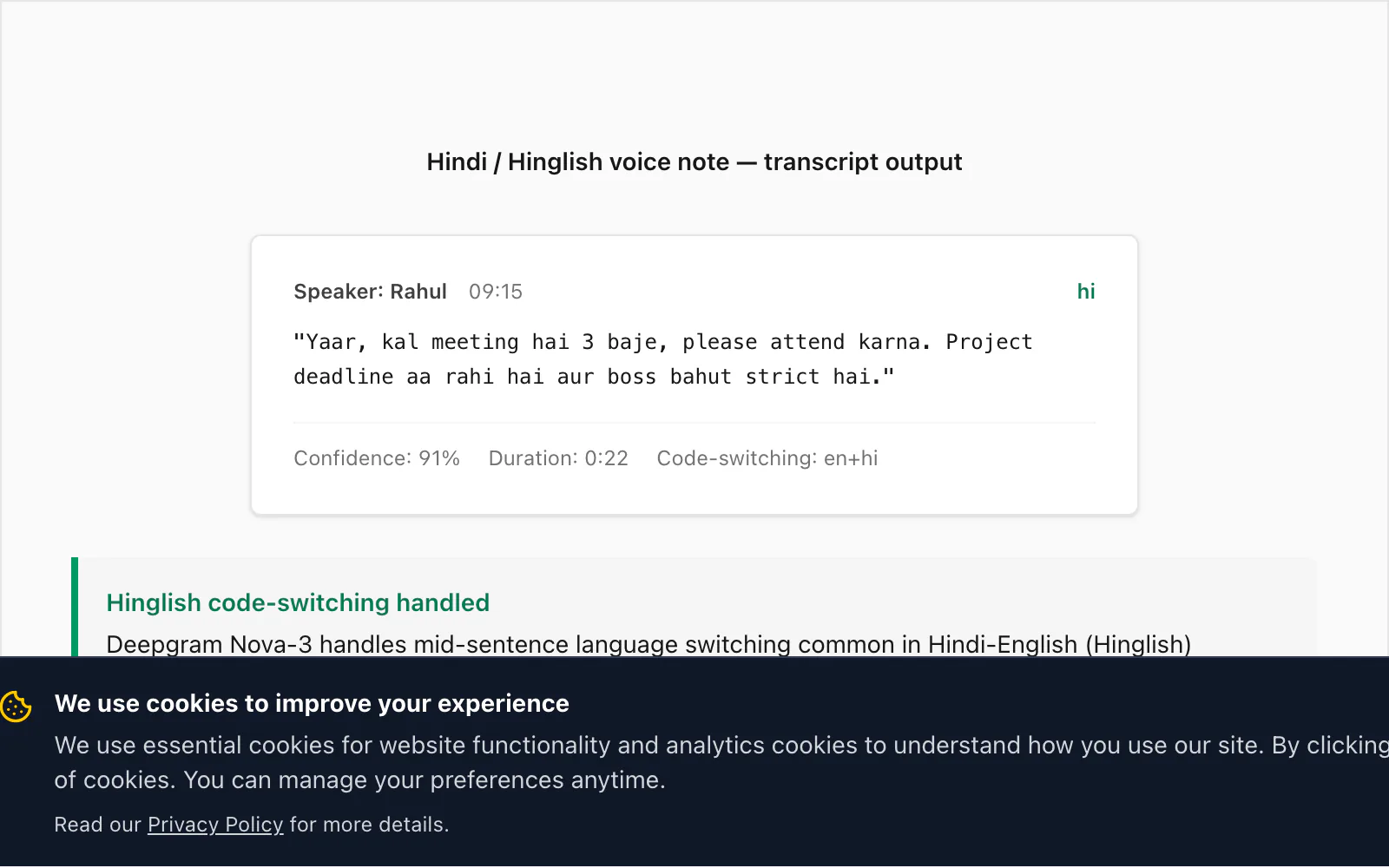
Di sinilah Nova-3 membedakan dirinya dari generasi mesin speech-to-text sebelumnya. Hinglish — Hindi dengan kata-kata, frasa, dan terkadang klausa penuh bahasa Inggris yang tertanam — adalah salah satu pola alih kode dunia nyata paling umum yang saya lihat di basis pengguna ChatToPDF. Mesin STT yang lebih lama (termasuk model yang Deepgram sendiri rilis dua generasi lalu) melewatkan sekitar 15% sisipan Inggris yang beralih kode dalam catatan suara Hinglish tipikal. Nova-3 menutup sebagian besar gap itu.
Berikut transkrip nyata dari konversi $49 Premium+Voice per chat:
🎤 [Catatan suara — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Terjemahan: "Bro, ada rapat besok jam 3, tolong hadir. Tenggat proyek sudah mendekat dan bosnya sangat ketat."
Alih kode di sini khas: meeting, attend, project deadline, dan strict adalah sisipan Inggris dalam kalimat Hindi. Nova-3 mentranskripsikan semuanya dengan benar. Model Deepgram yang lebih lama yang saya uji terhadap file yang sama menghasilkan miiting untuk meeting (rendering Hindi fonetis), menghilangkan attend sepenuhnya, dan menghasilkan project ka deadline dengan kapitalisasi yang tidak konsisten. Perbedaan itulah yang memotivasi peningkatan model dalam pipeline.
Perbedaan itu penting ketika Anda menggunakan transkrip sebagai catatan tempat kerja. Jika manajer seseorang meninjau transkrip catatan suara sebagai dokumentasi komitmen proyek dan kata deadline tidak muncul dalam teks, itu bukan persoalan akurasi kecil — itu informasi yang hilang.
Atribusi pengirim bekerja sama dengan Spanyol: nama dari _chat.txt muncul dalam PDF bersama transkrip Deepgram, dan cap waktu dari metadata WhatsApp mengaitkannya ke posisi yang tepat dalam percakapan.
Satu catatan khusus tentang Hindi: jika catatan suara dalam bahasa Hindi dominan Devanagari (Hindi formal, bergaya ucapan tertulis dengan minimal Inggris), akurasi konsisten kuat di seluruh tier yang didukung. Konversi $49 Premium+Voice per chat adalah titik masuk yang tepat untuk catatan suara Hindi yang ingin Anda transkripsi; konversi $99 Power User per chat mencakup akurasi yang sama tanpa batas audio dan prioritas antrian. Konversi $29 Premium per chat menyimpan catatan suara hanya sebagai placeholder — tidak ada transkripsi yang berjalan pada tier tersebut.
Tier $49 Premium+Voice — isi dan yang tidak termasuk

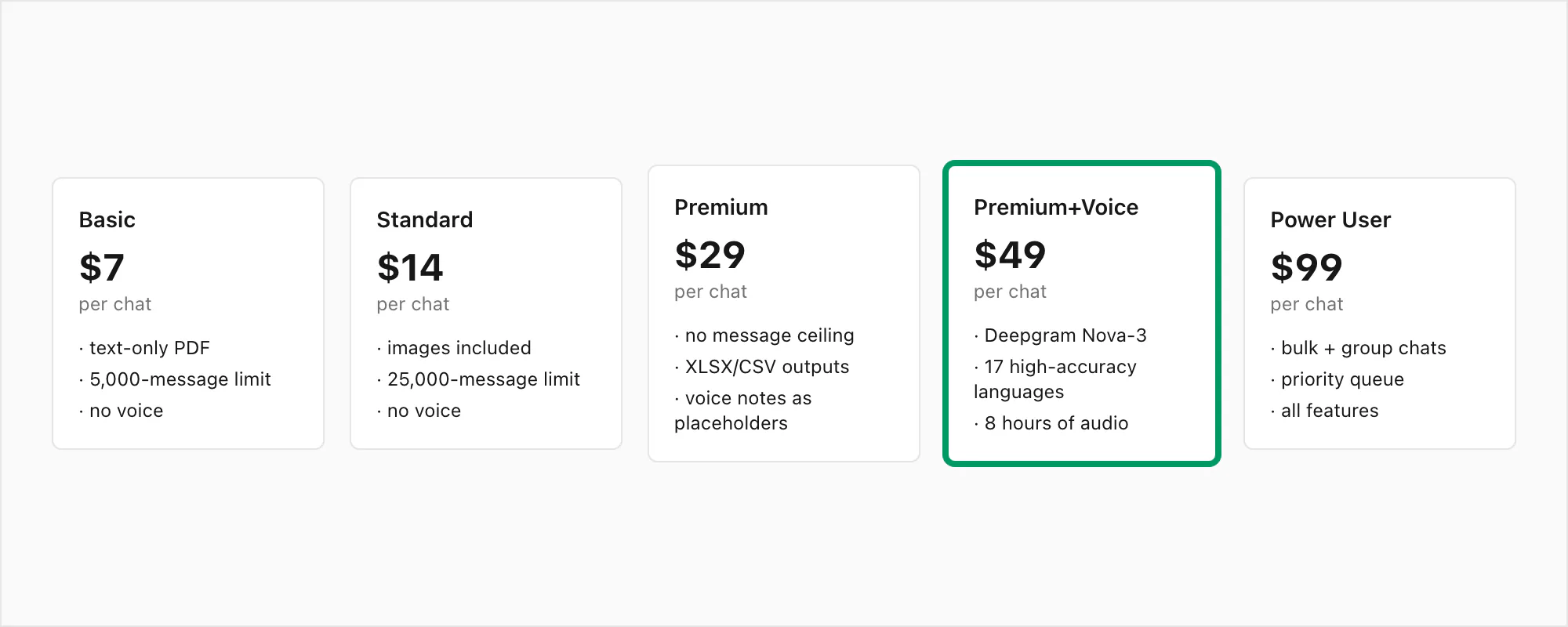
Konversi $49 Premium+Voice per chat adalah tier yang saya bangun khusus untuk chat dengan banyak suara. Berikut persis apa yang termasuk dan yang tidak.
Yang ada dalam konversi $49 Premium+Voice per chat:
- Transkripsi Deepgram Nova-3 — model generasi terkini dengan WER 3–5% pada audio bersih, penanganan aksen yang kuat, dan dukungan alih kode yang andal
- Semua 17 bahasa akurasi tinggi — Bahasa Inggris, Spanyol, Portugis, Prancis, Jerman, Italia, Arab, Hindi, Indonesia, Turki, Rusia, Belanda, Jepang, Korea, Mandarin, Vietnam, Thai — ditambah 30+ bahasa lainnya melalui deteksi bahasa otomatis Nova-3
- Hingga 8 jam audio dalam satu chat — mencakup sebagian besar percakapan dengan banyak suara; jika chat Anda melebihi 8 jam total audio yang direkam, konversi $99 Power User per chat menghapus batas itu
- Tidak ada batas pesan — tidak ada batas atas jumlah pesan dalam chat yang Anda konversi
- Atribusi pengirim pada transkrip — setiap transkrip dalam PDF memuat nama pengirim WhatsApp dari metadata ekspor
- Cap waktu tetap terjaga — cap waktu WhatsApp asli muncul bersama setiap transkrip, bukan waktu transkripsi
- Tiga format output — PDF, XLSX, dan CSV semuanya termasuk; XLSX berguna jika Anda ingin memfilter atau mengurutkan berdasarkan pengirim dan cap waktu
- Retensi file sumber tujuh hari — terenkripsi saat tersimpan (AES-256), dalam transit (TLS 1.3)
Yang tidak ada dalam konversi $49 Premium+Voice per chat:
- Transkripsi real time — tier ini memproses catatan suara yang sudah direkam dari ZIP ekspor; ini bukan layanan transkripsi langsung (saya jelaskan alasannya di bagian berikutnya)
- Daftar kosakata kustom — Anda tidak bisa mengunggah glosarium nama atau istilah teknis untuk meningkatkan akurasi pada kosakata spesifik; model tujuan umum Deepgram menangani sebagian besar nama dengan benar tapi kadang salah mendengar nama diri yang langka
- Identifikasi pembicara di luar metadata WhatsApp — dalam satu catatan suara di mana pengirim merekam sementara orang lain berbicara di latar belakang, keduanya ditranskripsikan tapi hanya dikaitkan ke pengirim WhatsApp. ChatToPDF tidak menjalankan diarisasi pembicara pada audio itu sendiri.
- Terjemahan otomatis — transkrip muncul dalam bahasa sumber catatan suara. Jika catatan suara dalam Bahasa Spanyol, transkripnya dalam Bahasa Spanyol. ChatToPDF tidak menerjemahkan transkrip.
Tier di atasnya — konversi $99 Power User per chat — mencakup semua yang ada dalam konversi $49 Premium+Voice per chat ditambah pemrosesan antrian prioritas dan penanganan chat massal. Jika Anda mengonversi satu chat dan kecepatan tidak kritis (sebagian besar konversi selesai dalam tiga menit), konversi $49 Premium+Voice per chat adalah level yang tepat.
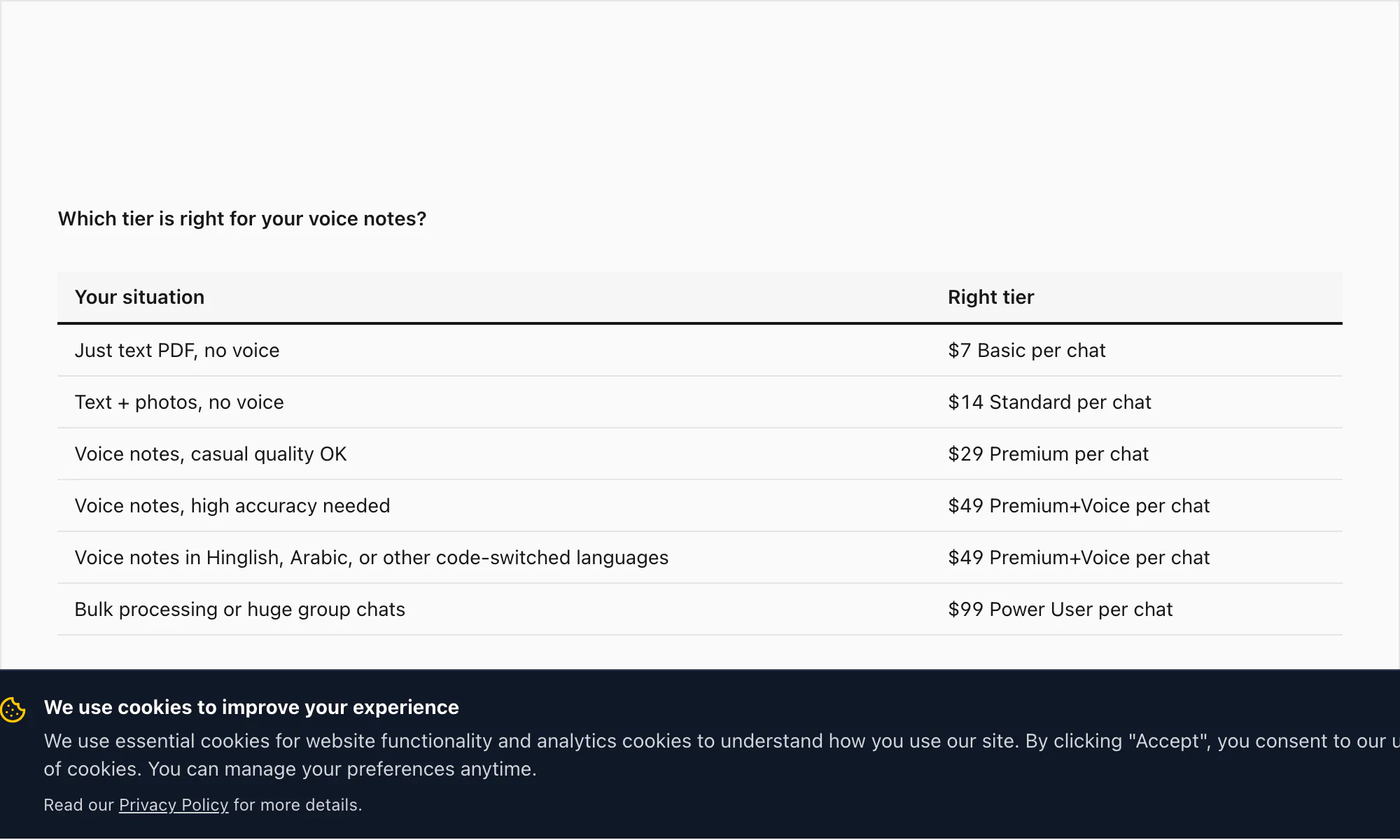
Untuk referensi, tumpukan tier lengkap: konversi $7 Basic per chat (hanya teks, batas 5.000 pesan), konversi $14 Standard per chat (gambar, batas 25.000 pesan), konversi $29 Premium per chat (tanpa batas, XLSX/CSV, catatan suara disimpan sebagai placeholder), konversi $49 Premium+Voice per chat (transkripsi Nova-3, 17 bahasa akurasi tinggi, batas audio 8 jam), konversi $99 Power User per chat (transkripsi Nova-3, tanpa batas audio, antrian prioritas, skenario massal).
Mengapa saya tidak transkripsi real time (dan tidak akan menambahkannya)
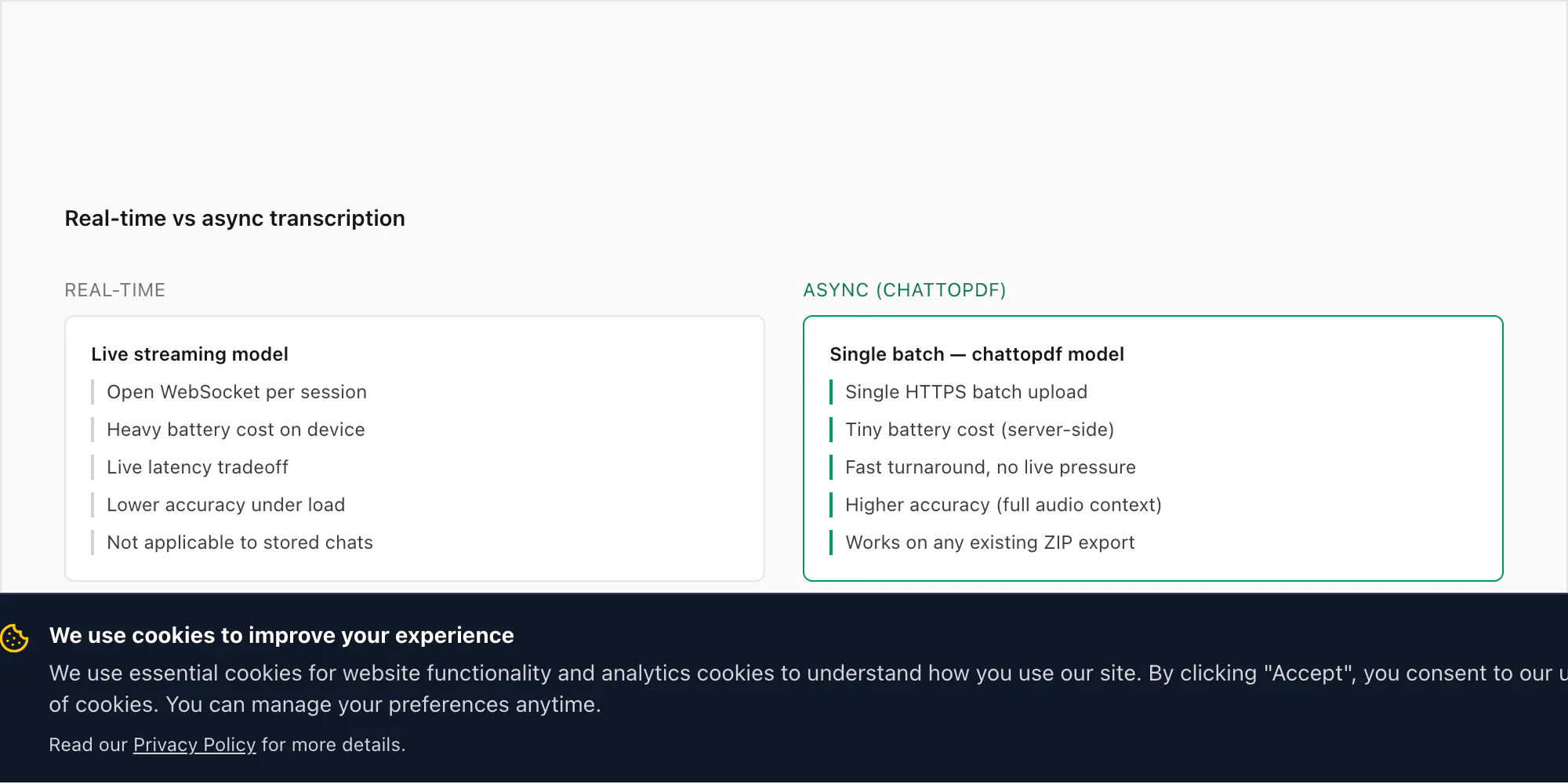
Ini sering cukup ditanyakan sehingga layak mendapat jawaban langsung. Orang bertanya mengapa ChatToPDF tidak mendengarkan catatan suara saat tiba — mentranskripsikan masing-masing di saat dikirim — daripada memerlukan ekspor ZIP setelah itu.
Versi singkatnya: WhatsApp tidak memberi pengembang akses ke pesan masuk atau audio secara real time. Tidak ada endpoint API WhatsApp Business resmi yang memunculkan catatan suara saat tiba. Satu-satunya jalur akses pihak ketiga yang didukung adalah melalui mekanisme Ekspor Chat, yang merupakan snapshot riwayat percakapan pada satu titik waktu. Membangun transkripsi real time di atas WhatsApp akan memerlukan penyadapan penyimpanan lokal aplikasi di perangkat, yang secara teknis rapuh dan di luar kebijakan platform WhatsApp.
Tapi ada alasan yang lebih praktis mengapa saya tidak mencoba membangun di sekitar batasan itu. Kasus penggunaan untuk mentranskripsikan audio WhatsApp hampir seluruhnya bersifat retrospektif. Seseorang menerima tiga puluh catatan suara sepanjang perselisihan dan menginginkan catatan yang bisa dibaca. Tim bisnis menggunakan catatan suara untuk pembaruan proyek dan perlu dicari. Keluarga mengirim catatan suara selama bertahun-tahun dan ingin mengarsipkannya sebelum ganti ponsel. Tidak satu pun dari ini yang melibatkan persyaratan "sekarang, saat tiba." Semuanya adalah "saya punya kumpulan rekaman yang perlu dikonversi."
Pemrosesan batch asinkron juga lebih akurat. Speech-to-text real time beroperasi di bawah batasan latensi yang mendorong model menuju inferensi yang lebih cepat (dan kurang akurat). Mode batch Deepgram berjalan pada file audio lengkap, yang memungkinkan model menggunakan konteks masa depan — apa yang datang setelah sebuah kata — untuk menyelesaikan fonem yang ambigu. Pada catatan suara 30 detik, perbedaan WER antara mode real time dan batch bisa 2–4 poin persentase. Itu bermakna pada skala akurasi.
Ada juga pertanyaan baterai dan jaringan. Menjalankan koneksi WebSocket terbuka yang mengalirkan fragmen audio ke API inferensi secara real time akan menguras baterai ponsel secara terlihat selama percakapan panjang. Ini akan memerlukan koneksi internet aktif untuk setiap catatan suara yang diterima, bukan hanya saat Anda memilih untuk mengonversi. Dan ini akan menciptakan aliran data berkelanjutan dari percakapan Anda ke server pihak ketiga — yang tidak nyaman saya minta pengguna terima.
Model ekspor-dan-unggah lebih lambat dalam waktu jam — Anda harus menunggu hingga siap mengonversi, lalu menjalankan ekspor, lalu mengunggah. Tapi untuk kasus penggunaan yang sebenarnya dimiliki orang, itu tidak masalah. Tidak ada yang mencoba mentranskripsikan catatan suara yang mereka terima tiga detik lalu untuk dokumen real time. Mereka mengonversi chat yang ingin mereka simpan.
Privasi: ke mana audio Anda pergi dan tidak pergi
Inilah bagian yang ingin saya jelaskan secara spesifik karena sifat catatan suara — rekaman audio dari percakapan nyata — berarti taruhan privasi lebih tinggi dari pesan teks saja.
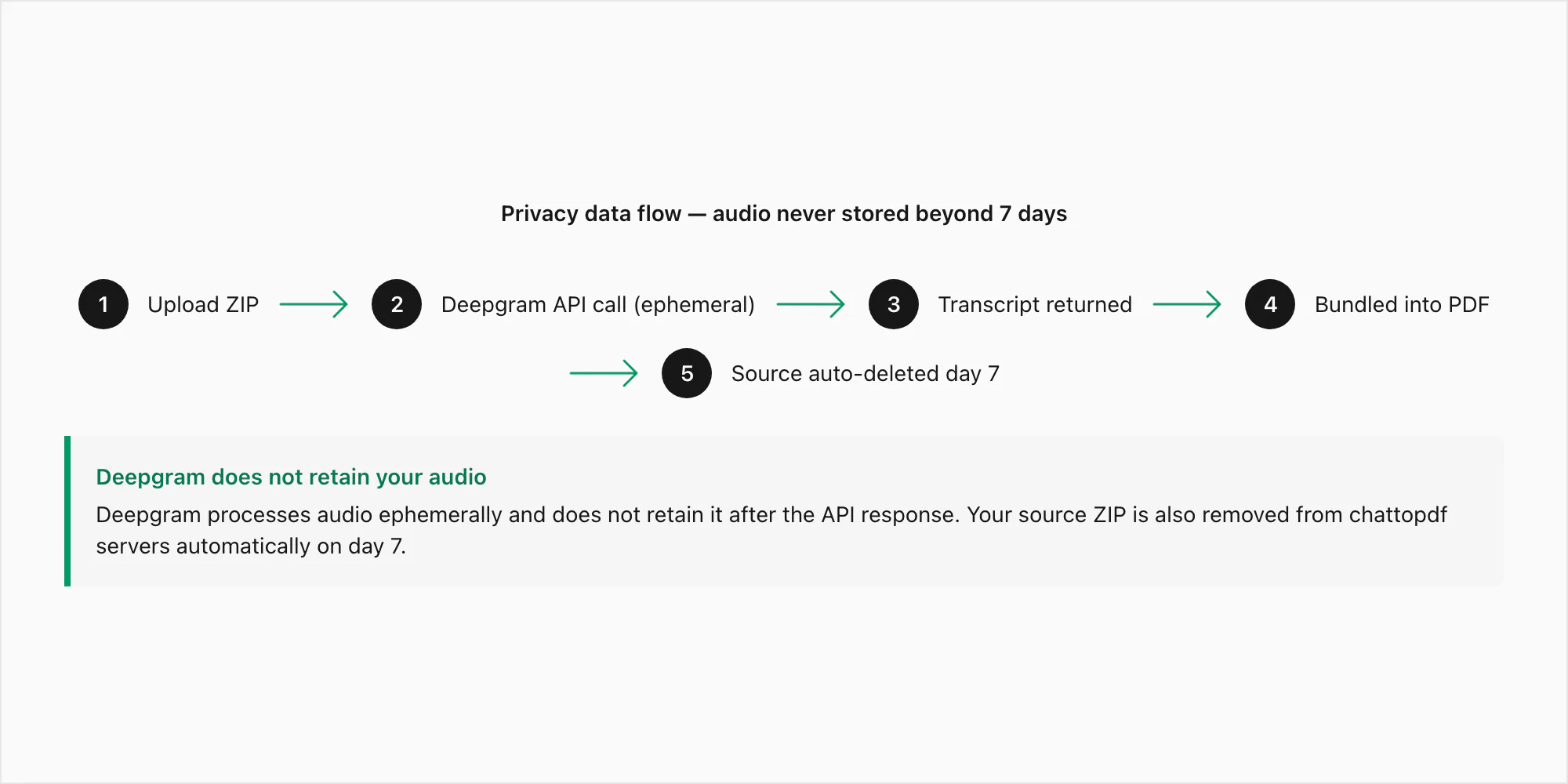
Berikut jalur data yang tepat untuk catatan suara yang dikirimkan melalui konversi $49 Premium+Voice per chat:
Langkah 1 — Unggah. File ZIP Anda ditransmisikan dari browser Anda ke server ChatToPDF melalui HTTPS (TLS 1.3). Koneksi dienkripsi dalam transit. ZIP mendarat di direktori pemrosesan sementara, bukan penyimpanan permanen, sementara ekstraksi berjalan.
Langkah 2 — Ekstraksi. File .opus diekstrak dari ZIP. Setiap file dicocokkan dengan referensi _chat.txt-nya berdasarkan pola nama file. Pada titik ini, file audio hanya ada di server pemrosesan ChatToPDF.
Langkah 3 — Panggilan API Deepgram. Setiap file .opus dikirimkan ke API inferensi Deepgram melalui panggilan HTTPS terautentikasi. Ini adalah satu momen di mana byte audio meninggalkan infrastruktur ChatToPDF sendiri. Kebijakan data Deepgram untuk pengiriman API menyatakan bahwa audio yang dikirimkan melalui API diproses secara ephemeral — digunakan untuk menghasilkan transkrip dan kemudian dibuang. Deepgram tidak menyimpan audio yang dikirimkan melalui API dan tidak menggunakannya untuk pelatihan model. Teks transkrip adalah yang dikembalikan.
Langkah 4 — Penyimpanan. Transkrip dikumpulkan ke dalam PDF dan disimpan terenkripsi saat tersimpan (AES-256) di AWS S3. ZIP sumber, termasuk file .opus, juga disimpan terenkripsi selama tujuh hari.
Langkah 5 — Pengiriman. Tautan unduhan PDF muncul di layar dan di email Anda. Tautan terikat ke ID pekerjaan Anda. Tidak dapat ditebak dan tidak diindeks di mana pun.
Langkah 6 — Penghapusan otomatis. Tujuh hari setelah pekerjaan dibuat, ZIP sumber dan PDF output dihapus dari penyimpanan secara otomatis. Ini adalah pekerjaan penghapusan terjadwal, bukan proses manual. Tidak ada pengecualian dan tidak ada perpanjangan.
Ke mana audio Anda tidak pergi: tidak pergi ke platform analitik mana pun. Tidak digunakan untuk melatih model ChatToPDF (ChatToPDF tidak melatih model). Konten teks catatan suara Anda tidak terlihat oleh staf ChatToPDF — pemrosesan sepenuhnya otomatis. Tidak ada pihak ketiga yang menerima teks pesan chat Anda.
Satu potensi kesenjangan dalam deskripsi ini adalah langkah Deepgram. Saya bisa sepenuhnya mengontrol apa yang terjadi di server ChatToPDF. Saya tidak bisa membuat pernyataan tentang proses internal Deepgram di luar apa yang dikatakan kebijakan data publik mereka. Jika catatan suara Anda berisi informasi yang memiliki hak istimewa hukum atau benar-benar diklasifikasikan, saya menyarankan tim hukum Anda meninjau ketentuan pemrosesan data enterprise Deepgram sebelum mengunggah. Untuk sebagian besar kasus penggunaan — percakapan pribadi, chat tim bisnis, arsip catatan suara keluarga — pipeline standar sudah sesuai.
Kasus tepi: kebisingan latar, banyak pembicara, efek perubahan suara
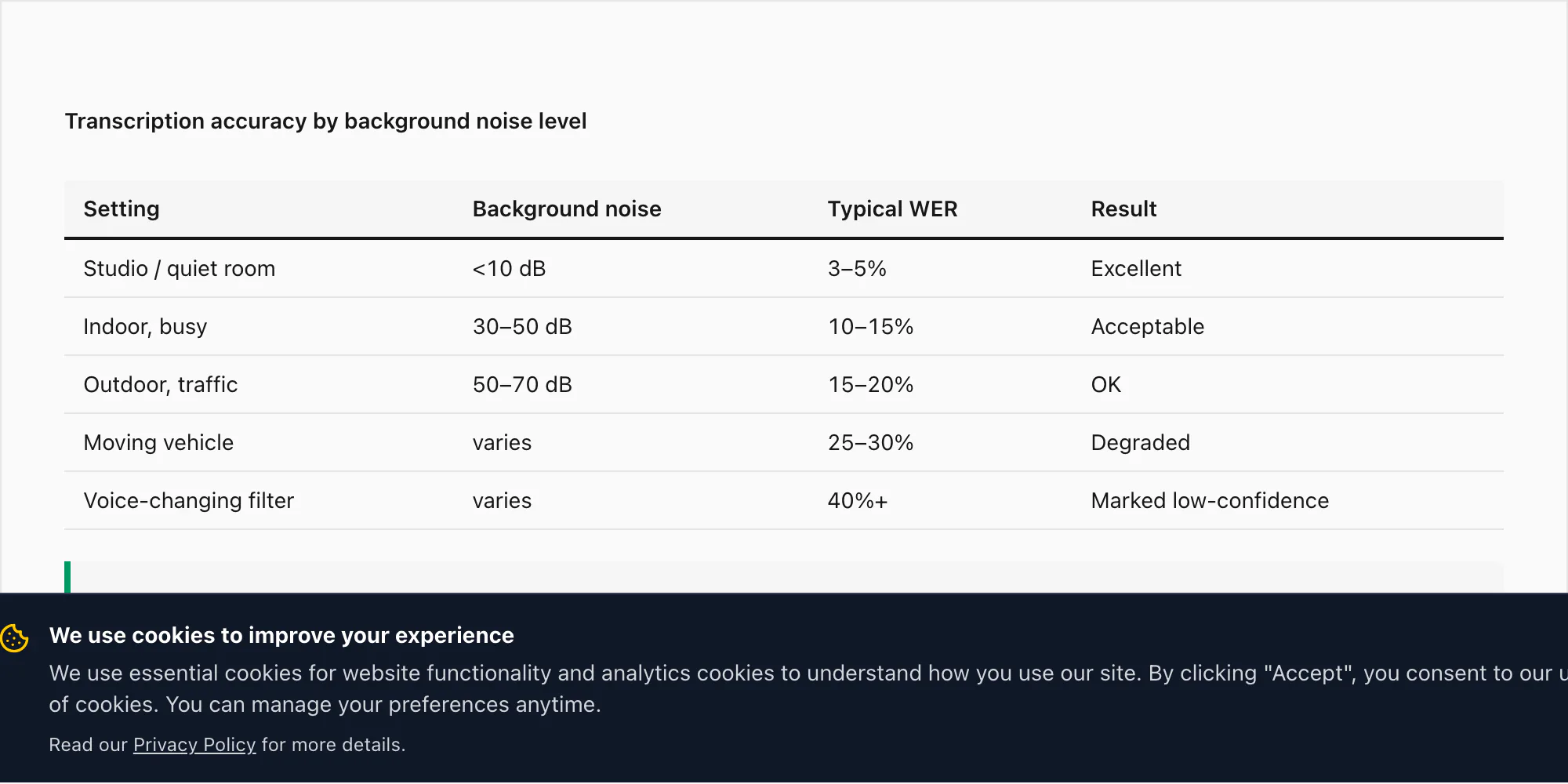
Catatan suara WhatsApp nyata tidak direkam di studio kedap suara. Direkam di dalam mobil, dapur, pertemuan di jalan, dan kafe yang ramai. Berikut cara masing-masing skenario tersebut memengaruhi akurasi transkripsi, dan apa yang dilakukan ChatToPDF ketika akurasi turun ke tingkat yang tidak dapat diterima.
Kebisingan latar berdasarkan lingkungan.
Catatan suara yang direkam dalam lingkungan dalam ruangan yang tenang — kantor, kamar tidur, ruangan yang diam — berkinerja pada tingkat akurasi yang saya sebutkan di bagian bahasa di atas: WER 3–5% pada konversi $49 Premium+Voice per chat untuk 17 bahasa akurasi tinggi.
Catatan suara dari lingkungan dalam ruangan yang ramai (restoran, pasar, kantor yang sibuk) dapat melihat WER naik menjadi 10–15% pada konversi $49 Premium+Voice per chat. Pembatalan kebisingan Nova-3 Deepgram diterapkan selama inferensi, yang membantu, tapi tidak menghilangkan efek audio yang bersaing.
Rekaman di luar ruangan — kebisingan jalanan, angin, lalu lintas — dapat mendorong WER ke 15–20% untuk tier yang sama.
Catatan suara yang direkam selama perjalanan kendaraan yang bergerak, dengan kebisingan jalan dan suara mesin, adalah skenario tunggal paling menantang yang pernah saya uji. WER pada ini bisa mencapai 25–30% bahkan dengan Nova-3. Ini bukan batasan mesin transkripsi — ini mencerminkan fisika audio yang ditangkap oleh mikrofon ponsel pada 16 kHz dalam lingkungan yang bising. Kualitas audio yang masuk menentukan kualitas transkrip yang keluar.
Banyak pembicara dalam satu catatan suara.
Seperti yang dijelaskan sebelumnya, setiap catatan suara WhatsApp milik satu pengirim — orang yang menekan tombol push-to-talk. ChatToPDF mengaitkan transkrip ke pengirim tersebut. Namun, jika pengirim merekam sementara orang lain berbicara dengan jelas di latar belakang (percakapan telepon yang sedang dilakukan pengirim, TV yang diputar di latar belakang yang mencakup suara, orang lain di ruangan yang sama berbicara keras), Deepgram akan mentranskripsikan suara latar belakang juga — ia tidak diam-diam membuang pembicara non-utama. Transkrip akan mencampurkan kedua suara, dikaitkan ke pengirim WhatsApp. Ini dapat menghasilkan output yang membingungkan ketika ucapan latar belakang cukup dapat didengar untuk ditranskripsikan.
ChatToPDF saat ini tidak dapat mengisolasi pembicara utama dan membuang suara latar belakang dalam satu klip .opus. Diarisasi pembicara — mengidentifikasi segmen audio mana yang berasal dari orang mana dalam file audio yang sama — adalah fitur yang sedang saya evaluasi untuk tier mendatang, tapi memerlukan infrastruktur tambahan dan tidak ada dalam rilis saat ini.
Efek perubahan suara.
Beberapa pengguna WhatsApp mengirim catatan suara dengan efek audio yang diterapkan — filter suara dalam yang tersedia di WhatsApp sendiri (Android), perubahan suara gaya Snapchat sebelum berbagi, atau hanya audio yang telah diubah nada atau ditambahkan reverb sebelum dikirim. Model Deepgram dilatih pada ucapan alami. Audio yang dimodifikasi dapat mendorong WER di atas 40% dalam kasus ekstrem — catatan suara yang dikirim melalui filter bass dalam untuk membuat seseorang terdengar seperti robot sebagian besar akan gagal ditranskripsikan.
Untuk klip di mana kepercayaan jatuh di bawah ambang batas yang saya tetapkan dalam pipeline — saat ini didefinisikan sebagai skor kepercayaan kata rata-rata di bawah 0,6 di seluruh klip — ChatToPDF menandai transkrip dalam PDF sebagai [transkripsi kepercayaan rendah — kualitas audio tidak memadai] daripada mengeluarkan blok teks yang mungkin dianggap otoritatif. Anda akan melihat penanda ini dalam PDF akhir bersama posisi catatan suara dalam percakapan. Lebih baik menandai hasil yang tidak pasti daripada mengembalikan transkrip yang terlihat masuk akal tapi 40% salah.
FAQ
Format file apa yang digunakan catatan suara WhatsApp, dan apakah ChatToPDF menanganinya?
WhatsApp merekam catatan suara menggunakan codec audio Opus pada 16 kHz mono, disimpan sebagai file .opus. ChatToPDF mengekstrak file .opus langsung dari ZIP ekspor WhatsApp Anda dan mengirimkannya ke API inferensi Deepgram dalam format native mereka — tidak diperlukan langkah pengkodean ulang. Ekspor iPhone maupun Android menghasilkan file .opus, sehingga penanganan format sama pada kedua platform.
Seberapa akurat transkripsi audio WhatsApp?
Akurasi bergantung pada tier dan kualitas audio. Konversi $49 Premium+Voice per chat menggunakan Deepgram Nova-3, yang mencapai sekitar 3–5% word error rate pada audio bersih dan bebas kebisingan dalam 17 bahasa akurasi tinggi yang didukung. Konversi $99 Power User per chat menggunakan model Nova-3 yang sama tanpa batas audio dan pemrosesan antrian prioritas. Konversi $29 Premium per chat tidak mentranskripsikan — ia menyimpan catatan suara sebagai referensi placeholder dalam PDF. Kebisingan latar, aksen, dan alih kode antara bahasa semuanya memengaruhi akurasi pada tier yang mentranskripsikan. Saya menandai klip kepercayaan rendah (di bawah skor kepercayaan kata rata-rata 0,6) sebagai [transkripsi kepercayaan rendah] dalam PDF daripada menyajikan transkrip yang berpotensi menyesatkan.
Apakah ChatToPDF mentranskripsikan catatan suara dalam bahasa selain Bahasa Inggris?
Ya. Konversi $49 Premium+Voice per chat dan konversi $99 Power User per chat mendukung 17 bahasa akurasi tinggi: Bahasa Inggris, Spanyol, Portugis, Prancis, Jerman, Italia, Arab, Hindi, Indonesia, Turki, Rusia, Belanda, Jepang, Korea, Mandarin, Vietnam, dan Thai. Kedua tier menggunakan Deepgram Nova-3 di seluruh bahasa ini dan mendeteksi 30+ bahasa tambahan dengan rentang akurasi lebih lebar. Bahasa terdeteksi secara otomatis — Anda tidak perlu menentukannya sebelum mengunggah. Konversi $29 Premium per chat tidak mentranskripsikan catatan suara — ia menyimpannya sebagai referensi placeholder dalam PDF.
Apakah saya perlu melakukan sesuatu yang berbeda saat mengekspor dari WhatsApp jika ingin transkrip suara?
Ya — satu langkah kritis. Saat mengekspor chat dari WhatsApp, pilih "Sertakan Media" daripada "Tanpa Media." Catatan suara (file .opus) hanya disertakan dalam ekspor saat Anda memilih Sertakan Media. Jika Anda mengekspor Tanpa Media, _chat.txt akan berisi referensi seperti <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> tapi tidak ada file audio yang sebenarnya. ChatToPDF tidak bisa mentranskripsikan catatan suara yang tidak dimilikinya. Lihat panduan ekspor chat WhatsApp untuk proses ekspor langkah demi langkah secara lengkap.
Apakah transkrip suara akan muncul di tempat yang tepat dalam PDF?
Ya. ChatToPDF membaca log pesan dalam _chat.txt untuk memahami struktur percakapan, mencocokkan setiap referensi .opus ke file audio yang sesuai berdasarkan nama file, dan menyisipkan transkrip tepat pada posisi dalam percakapan di mana catatan suara dikirim. Nama pengirim dari metadata WhatsApp dan cap waktu asli keduanya muncul bersama transkrip. Outputnya adalah satu dokumen di mana pesan teks dan transkrip catatan suara bergantian dalam urutan kronologis yang benar.
Apa yang terjadi pada file audio saya setelah transkripsi selesai?
File audio Anda disimpan terenkripsi saat tersimpan (AES-256) di server ChatToPDF selama tujuh hari setelah pekerjaan dibuat, kemudian dihapus secara otomatis. Satu-satunya layanan pihak ketiga yang menerima byte audio adalah Deepgram, dan hanya selama langkah transkripsi — Deepgram memproses audio yang dikirimkan melalui API secara ephemeral dan tidak menyimpannya. Tidak ada manusia yang mendengarkan rekaman Anda. Transkrip itu sendiri dihapus bersama file sumber pada tanda tujuh hari. Untuk detail lebih lanjut tentang alur data lengkap, lihat bagian privasi WhatsApp to PDF.
Bisakah ChatToPDF membedakan dua orang berbeda yang berbicara dalam satu catatan suara?
Belum saat ini. Setiap catatan suara WhatsApp dikaitkan ke orang yang mengirimnya, menggunakan informasi pengirim dari _chat.txt. Dalam satu catatan suara, jika pengirim dan orang lain keduanya berbicara (misalnya, pengirim sedang melakukan percakapan telepon saat merekam), kedua suara ditranskripsikan tapi dikaitkan ke pengirim WhatsApp. ChatToPDF saat ini tidak menjalankan diarisasi pembicara di dalam klip audio individual. Untuk catatan suara di mana suara latar belakang dapat didengar dan dimengerti, Anda mungkin melihat ucapan yang bercampur dalam transkrip.
Bagaimana cara mengubah voice note WhatsApp menjadi teks?
Untuk mengubah voice note WhatsApp menjadi teks: ekspor chat dengan Sertakan Media (agar file audio .opus ikut dalam ZIP), lalu unggah ke chattopdf.app dan pilih tier $49 Premium+Voice. Setiap voice note menjadi teks yang bisa dibaca di posisinya dalam percakapan — lengkap dengan nama pengirim dan timestamp. 17 bahasa dengan akurasi tinggi, dan Bahasa Indonesia juga didukung. Transkripsi bawaan WhatsApp hanya memproses satu pesan dan tidak bisa diekspor — kalau butuh seluruh chat sekaligus dalam bentuk teks, inilah caranya.
Apakah WhatsApp punya fitur voice to text bawaan?
Ada — di versi WhatsApp terbaru Anda bisa menekan lama sebuah voice note lalu memilih Transkrip (aktifkan dulu di Setelan → Chat → Transkrip pesan suara; ketersediaan bahasanya terbatas dan fiturnya belum muncul di semua perangkat). Itu gratis dan cukup untuk membaca satu-dua pesan suara. Bedanya dengan ChatToPDF: fitur bawaan bekerja satu pesan demi satu pesan di dalam aplikasi, sedangkan tier $49 Premium+Voice di chattopdf.app mentranskripsikan semua voice note dalam satu chat sekaligus dan menaruh teksnya di posisi yang tepat dalam PDF — jadi hasilnya berupa arsip yang bisa dibaca, dicari, dan dicetak, bukan sekadar transkrip sekali lihat.
Key takeaways
- Untuk transcribe WhatsApp audio, ekspor chat dengan "Sertakan Media" dipilih — file catatan suara
.opusharus ada di dalam ZIP - Konversi $29 Premium per chat tidak mentranskripsikan — ia menyimpan catatan suara sebagai referensi placeholder; konversi $49 Premium+Voice per chat menjalankan Deepgram Nova-3 (WER 3–5% pada audio bersih, 17 bahasa akurasi tinggi, hingga 8 jam audio); konversi $99 Power User per chat adalah model yang sama tanpa batas dengan antrian prioritas
- Setiap transkrip disisipkan pada posisi tepat dalam percakapan dengan nama pengirim WhatsApp dan cap waktu asli tetap terjaga
- Bahasa beralih kode seperti Hinglish memerlukan konversi $49 Premium+Voice per chat atau lebih tinggi — Nova-3 menutup sebagian besar gap yang dibuka mesin STT lama pada sisipan Inggris di tengah kalimat dalam catatan suara Hindi
- Kebisingan latar adalah variabel akurasi terbesar: kondisi studio menghasilkan WER 3–5%; rekaman di luar ruangan atau kendaraan dapat mencapai WER 20–30% bahkan pada Nova-3
- Audio yang dikirimkan ke Deepgram untuk transkripsi diproses secara ephemeral — tidak disimpan dan tidak digunakan untuk pelatihan; file sumber otomatis terhapus dari server ChatToPDF setelah 7 hari
- Klip di mana kepercayaan kata rata-rata jatuh di bawah 0,6 ditandai
[transkripsi kepercayaan rendah]dalam PDF daripada diam-diam mengembalikan transkrip yang berpotensi salah
Untuk alur chat-ke-PDF lengkap — termasuk cara mengekspor di iPhone dan Android, apa yang dikandung ZIP, dan cara perbandingan semua lima tier untuk konversi tanpa suara — lihat panduan WhatsApp to PDF. Jika Anda di Android dan perlu memindahkan ekspor ke perangkat lain sebelum mengunggah, panduan transfer WhatsApp Android ke iPhone mencakup proses tersebut.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).