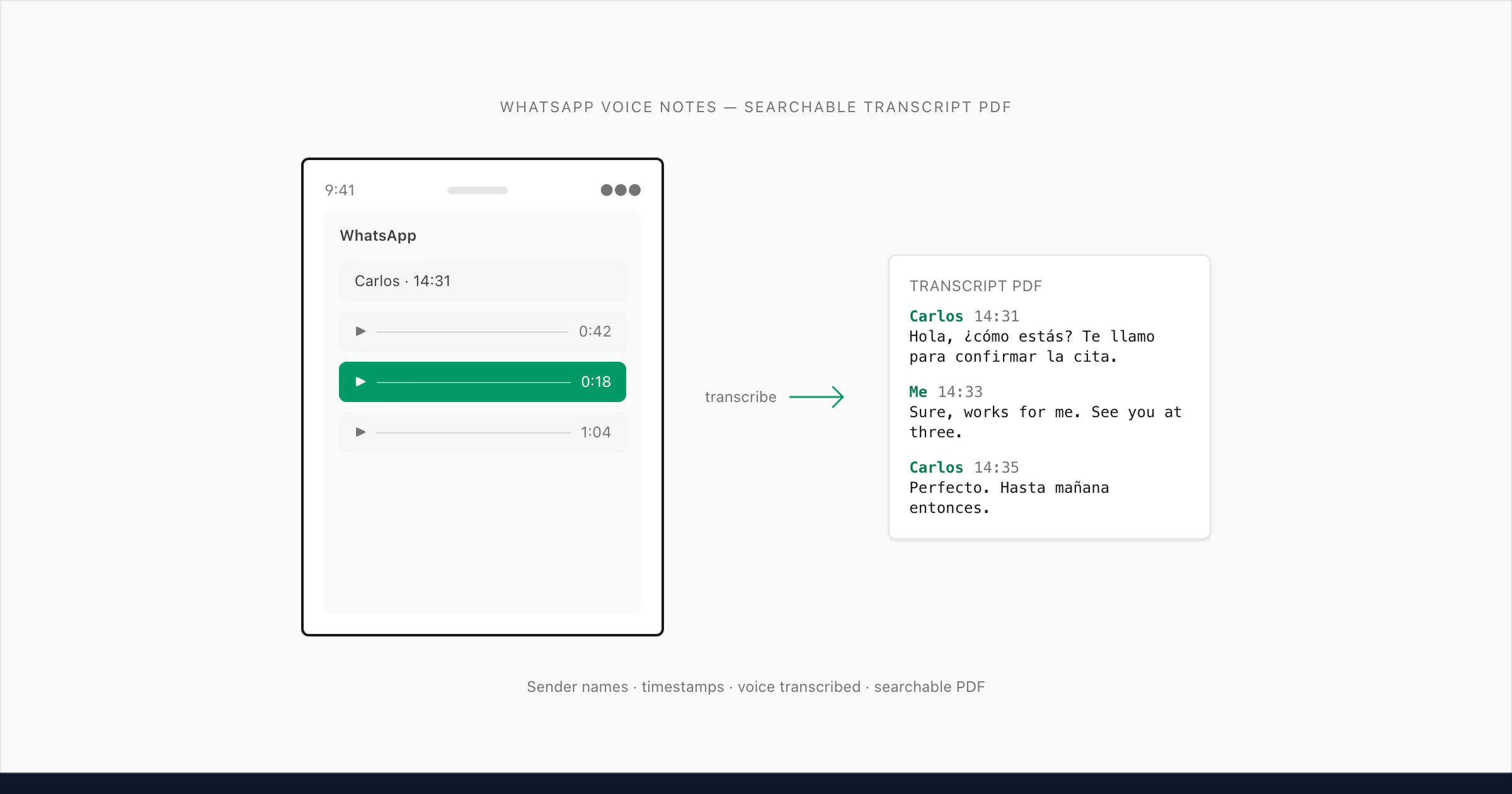
O que "transcribe WhatsApp audio" realmente significa (e por que é mais difícil do que parece)
As pessoas usam a expressão "transcribe WhatsApp audio" para se referir a pelo menos três coisas diferentes. Algumas querem transcrever chamadas de voz ao vivo — o que o WhatsApp não expõe por nenhuma API de desenvolvedor e que é tecnicamente uma categoria de produto separada do que descrevo aqui. Outras querem converter arquivos de áudio que salvaram do WhatsApp para texto, tratando o arquivo .opus como entrada independente. E outras — o maior grupo — querem que cada nota de voz dentro de um chat exportado do WhatsApp seja convertida para texto legível, de modo que a conversa inteira faça sentido como documento.
O ChatToPDF foi criado para esse terceiro caso. O problema que ele resolve é específico: você exporta um chat do WhatsApp que contém mensagens de texto e notas de voz, e o que você recebe do WhatsApp é um ZIP contendo um _chat.txt e uma pasta de arquivos de mídia. O _chat.txt tem linhas como <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> onde a nota de voz pertence. Nada converte essas referências em texto legível para você a menos que você construa algo para fazer isso.
Aqui está o que ninguém te conta: mesmo quando as pessoas encontram uma ferramenta de transcrição, frequentemente se deparam com um problema estrutural. As ferramentas que lidam com arquivos de áudio genéricos — faça upload de um MP3, receba texto de volta — não sabem onde na conversa aquele áudio pertence. Elas transcrevem o arquivo mas perdem o contexto. Você acaba com um bloco de texto separado sem nome de remetente, sem horário, sem indicação do que foi dito antes ou depois. Para um processo jurídico, um registro empresarial ou um arquivo familiar, esse contexto é o ponto central.
O que construí faz o seguinte: lê o _chat.txt para entender a estrutura da conversa, combina cada referência .opus com o arquivo de áudio correto no ZIP, transcreve o áudio e insere a transcrição de volta na posição exata correta na conversa — com o nome do remetente e o horário original do WhatsApp preservados. Esse detalhe me preocupou muito durante o desenvolvimento porque, sem ele, o contexto se perde. O resultado é um único PDF onde mensagens de texto e transcrições de notas de voz se alternam naturalmente, exatamente como a conversa aconteceu.
É esse o problema sobre o qual trata este guia.
Notas de voz não são arquivos — são um stream interno do app
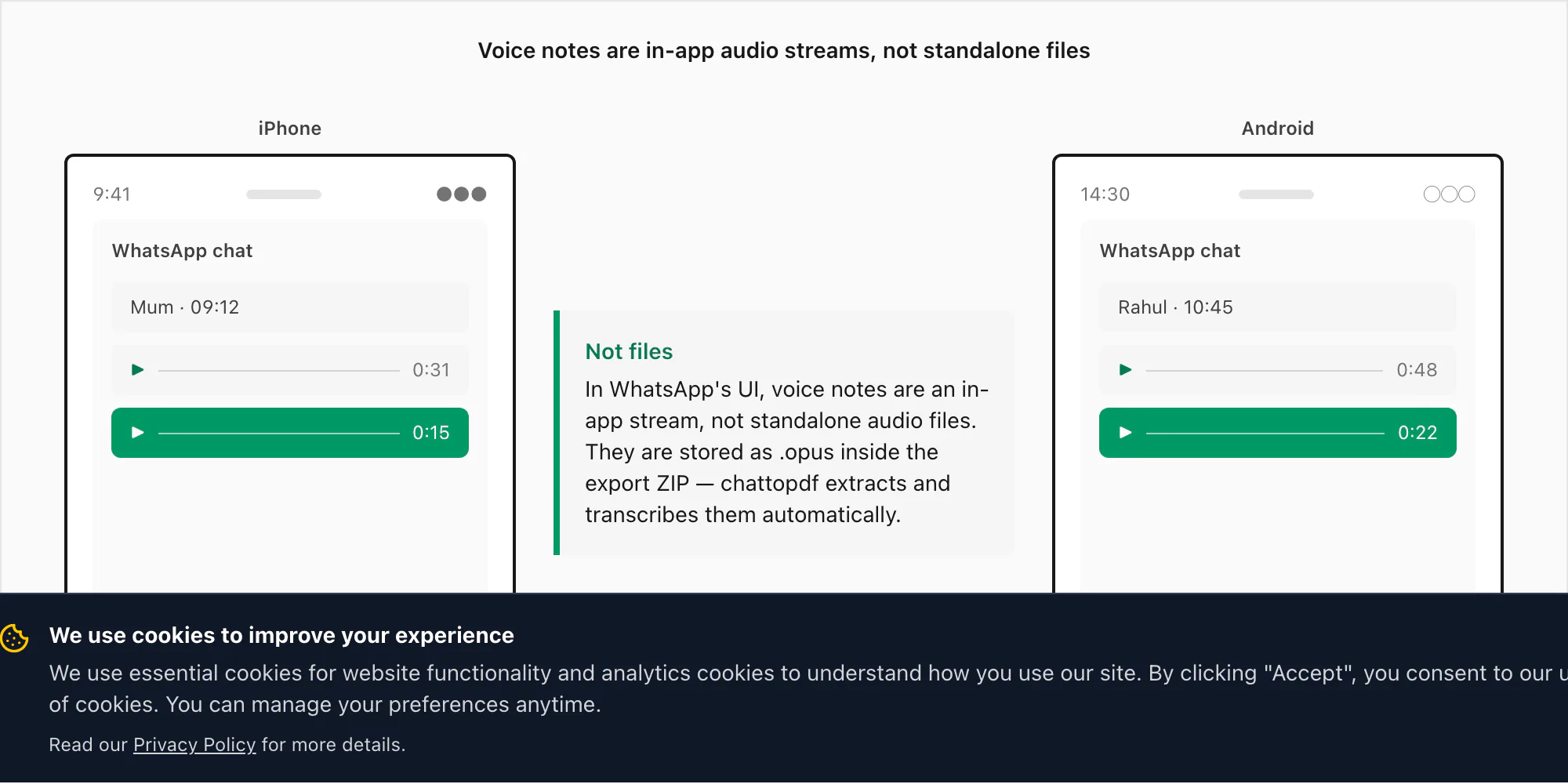
As notas de voz do WhatsApp parecem arquivos de áudio dentro do app — uma barra de forma de onda, uma duração, um botão de reprodução — mas não são armazenadas do jeito que a maioria das pessoas espera. Quando você grava uma nota de voz no WhatsApp pressionando o botão do microfone, o WhatsApp codifica o áudio usando o codec Opus e salva como um arquivo .opus em um diretório privado no dispositivo. Esse diretório não é acessível por navegação de arquivos normal no iPhone ou no Android. Você não pode navegar até ele no app Arquivos e encontrar suas notas de voz ali.
A única forma de extrair esses arquivos .opus é pelo menu Exportar conversa do WhatsApp, com "Incluir mídia" selecionado. Quando você exporta dessa forma, o WhatsApp empacota o registro de mensagens _chat.txt junto com a pasta de mídia — e é aí que os arquivos .opus aparecem. No iOS, eles ficam dentro do ZIP. No Android, versões mais antigas do WhatsApp exportavam para uma pasta no armazenamento interno; versões mais novas criam um ZIP pela tela de compartilhamento, igual ao iOS.
Vale entender brevemente o codec Opus porque ele explica por que a precisão pode variar. O Opus foi projetado para voz sobre IP — baixa latência, boa compressão, boa qualidade mesmo em baixas taxas de bits. O WhatsApp usa áudio mono de 16 kHz a cerca de 16 kbps. Os arquivos resultantes são minúsculos: uma nota de voz de 60 segundos geralmente pesa entre 80 KB e 120 KB. Isso é eficiente para dados móveis, mas 16 kHz mono a 16 kbps não é áudio de qualidade de estúdio. É otimizado para inteligibilidade em uma conexão móvel, não para precisão de transcrição. Ruído de fundo, voz gravada enquanto dirige ou alguém falando do outro lado do cômodo podem reduzir a qualidade efetiva ainda mais.
Por isso o modelo de transcrição importa. Um motor genérico de fala para texto treinado em áudio de estúdio ou gravações de podcast vai ter dificuldade com Opus mono de 16 kHz comprimido a 16 kbps. O motor que escolhi foi selecionado especificamente porque lida bem com esse tipo de áudio. Mais sobre isso na próxima seção.
Mais um ponto estrutural: cada nota de voz do WhatsApp é uma gravação de único remetente. O modelo push-to-talk do WhatsApp significa que uma pessoa grava, então para, então a outra pessoa grava sua resposta. Isso é na verdade uma vantagem para transcrição — ao contrário de uma chamada gravada onde duas vozes se sobrepõem na mesma faixa de áudio, cada arquivo .opus em uma exportação do WhatsApp pertence a exatamente um remetente. O ChatToPDF usa os metadados do _chat.txt para atribuir cada transcrição à pessoa correta, que é como você obtém uma conversa que se lê claramente mesmo quando as pessoas se alternam em notas de voz.
O motor de transcrição que escolhi, e por quê
Avaliei várias APIs de transcrição antes de escolher o Deepgram como motor por trás da transcrição de voz do ChatToPDF. Os outros candidatos sérios foram AssemblyAI, Whisper (o modelo de código aberto da OpenAI) e algumas APIs genéricas de fala de provedores de nuvem. Aqui está o raciocínio honesto por trás da minha escolha.
O Whisper é impressionante para um modelo gratuito, mas rodei testes de precisão em um conjunto de arquivos .opus reais do WhatsApp em inglês, espanhol, hindi e árabe, e ele mostrou pontos fracos consistentes na alternância de código (uma nota de voz que mistura dois idiomas no meio de uma frase) e em sotaques de inglês não americano. Também não oferece SLAs comerciais ou garantias de disponibilidade, o que importa quando usuários pagantes estão esperando pela saída.
O AssemblyAI é genuinamente bom e o usei em um protótipo inicial. A precisão no inglês era comparável à do Deepgram, mas a amplitude do suporte de idiomas e a consistência de resposta da API em áudio codificado em Opus a 16 kHz mono tornaram o Deepgram a melhor opção para o caso de uso multilíngue que estava construindo.
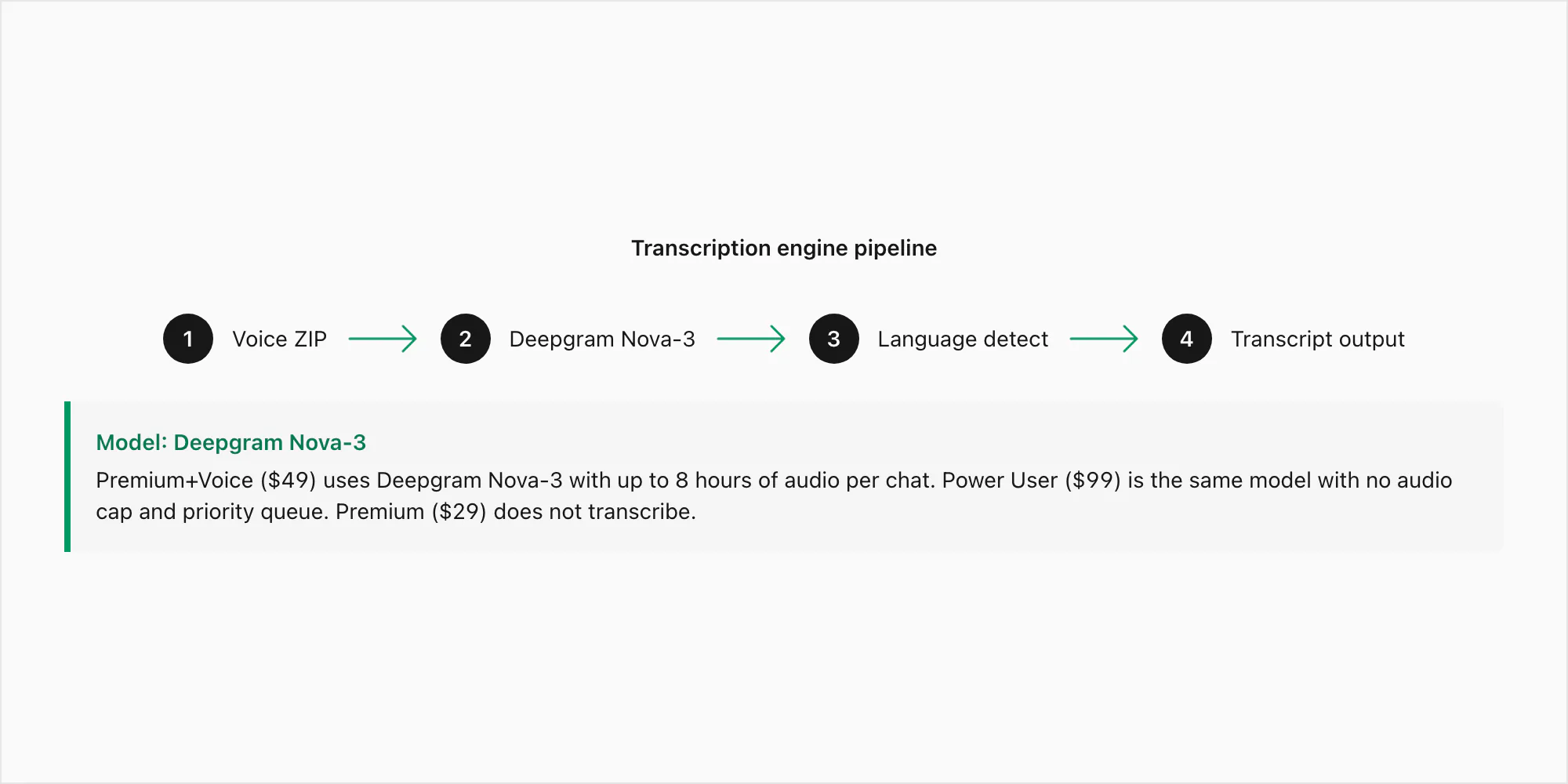
O Deepgram Nova-3 é o modelo da geração atual com uma taxa de erro de palavras de aproximadamente 3–5% em áudio limpo e sem ruído em inglês e de 8–15% em gravações mais ruidosas. Esses números se mantêm em Opus mono de 16 kHz, que é o formato que importa para exportações do WhatsApp. O Nova-3 é o modelo usado tanto para a conversão $49 Premium+Voice por chat quanto para a conversão $99 Power User por chat — a diferença entre esses planos é o limite de áudio (8 horas versus ilimitado) e a prioridade da fila, não o modelo.
Onde o Nova-3 supera visivelmente motores de fala para texto mais antigos é em três pontos: sotaques regionais (inglês sul-africano, inglês indiano, português brasileiro), vocabulário técnico (nomes, endereços, termos de produtos que um modelo genérico interpretaria errado) e áudio com alternância de código onde um falante muda de idioma dentro de uma única nota de voz. Esses são os modos de falha específicos que motivaram a escolha do motor. A conversão $29 Premium por chat não inclui transcrição alguma — preserva as notas de voz como marcadores no PDF sem rodar o áudio por nenhum modelo.
O pipeline funciona assim: seu ZIP chega ao servidor do ChatToPDF, os arquivos .opus são extraídos, cada um é enviado à API do Deepgram por uma chamada HTTPS autenticada com detecção de idioma definida como automática, e a transcrição retorna — normalmente entre dois e cinco segundos por minuto de áudio. As transcrições são então reinseridas na conversa nas posições corretas antes de o PDF ser renderizado.
Uma escolha deliberada no pipeline: não faço pré-processamento ou recodificação do áudio .opus antes de enviá-lo ao Deepgram. Algumas ferramentas convertem Opus para WAV ou MP3 primeiro, argumentando que um formato diferente poderia melhorar a precisão. Na prática, a API do Deepgram lida com Opus nativamente e a conversão adiciona latência sem melhorar os resultados nesse tipo de áudio. O arquivo .opus bruto vai direto para o endpoint de inferência.
Precisão nos 17 idiomas suportados hoje
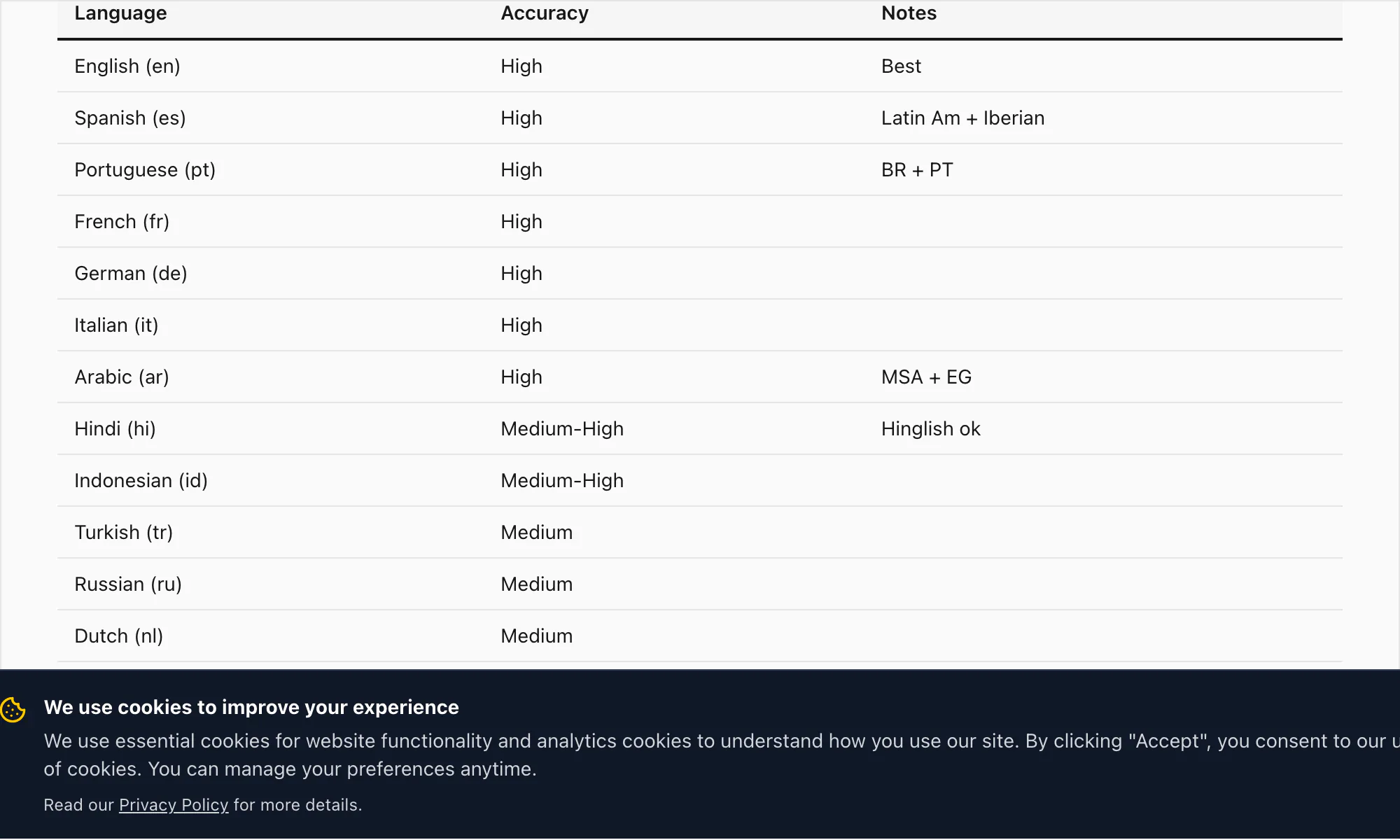
A faixa de alta precisão do ChatToPDF cobre 17 idiomas. São os idiomas em que tenho confiança suficiente na qualidade da transcrição para chamá-la de pronta para produção em documentos, registros jurídicos e uso empresarial:
Inglês (en) — TEP de 3–5% em áudio limpo. Inclui variantes do Reino Unido, EUA, Austrália, África do Sul e Índia. Todas as variantes do inglês são tratadas pelo mesmo modelo Nova-3 na conversão $49 Premium+Voice por chat.
Espanhol (es) — TEP de 4–6% na conversão $49 Premium+Voice por chat. Lida com variantes latino-americanas e castelhanas. Confusão de homófonos comuns (haya/halla, tubo/tuvo) é parcialmente mitigada por inferência de contexto.
Português (pt) — TEP de 4–7%. Cobre o português brasileiro e o europeu. A alternância entre português e inglês é um padrão comum em chats brasileiros de WhatsApp; o Nova-3 lida bem com isso.
Francês (fr) — TEP de 4–6%. Francês padrão e canadense.
Alemão (de) — TEP de 4–6%. Substantivos compostos são transcritos com precisão pelo Nova-3, incluindo formas compostas longas típicas do vocabulário empresarial e jurídico.
Italiano (it) — TEP de 5–7%.
Árabe (ar) — TEP de 7–10%. O árabe padrão moderno transcreve bem; o árabe dialetal (egípcio, do Golfo, levantino) tem variação mais ampla. A conversão $49 Premium+Voice por chat é o plano recomendado para notas de voz em árabe.
Hindi (hi) — TEP de 6–9% no hindi puro. O Hinglish com alternância de código (hindi com inserções em inglês) é onde o Nova-3 faz a maior diferença em relação a motores de transcrição mais antigos — mais sobre isso na seção de transcrição de amostra abaixo.
Indonésio (id) — TEP de 5–8%. Um dos idiomas mais comuns na base de usuários do ChatToPDF, dada a forte penetração do WhatsApp no Sudeste Asiático.
Turco (tr) — TEP de 5–8%.
Russo (ru) — TEP de 5–8%.
Holandês (nl) — TEP de 4–6%.
Japonês (ja) — TEP de 7–10%. Empréstimos em katakana e nomes próprios podem introduzir erros; a precisão geral é forte para fala conversacional.
Coreano (ko) — TEP de 6–9%.
Chinês (zh) — TEP de 7–10%. Mandarim. Dialetos regionais e homófonos tonais podem afetar a precisão em gravações desafiadoras.
Vietnamita (vi) — TEP de 7–10%.
Tailandês (th) — TEP de 8–12%. Marcadores de tom e grupos de consoantes em fala rápida são o principal desafio.
Além desses 17, o Deepgram Nova-3 suporta mais de 30 idiomas adicionais em uma faixa de precisão mais ampla. Se o seu idioma não está na lista de alta precisão acima, a conversão $49 Premium+Voice por chat ainda produz uma transcrição de melhor esforço usando a detecção de idioma mais ampla do Nova-3 — só espere uma precisão próxima a 15–20% de TEP em áudio desafiador nos idiomas de menor faixa.
A detecção automática de idioma está ativada por padrão. O ChatToPDF envia cada arquivo .opus ao Deepgram sem especificar um idioma, e o Deepgram detecta o idioma dominante nos primeiros segundos. Isso é preciso para gravações em um único idioma. Para alternância de código intensa — uma nota de voz que é genuinamente 50/50 dois idiomas — o detector escolhe um como principal e aplica esse modelo ao clipe inteiro. Você verá alguma perda de precisão no idioma secundário nesses casos.
Transcrição de amostra: nota de voz em espanhol → texto (exemplo real)
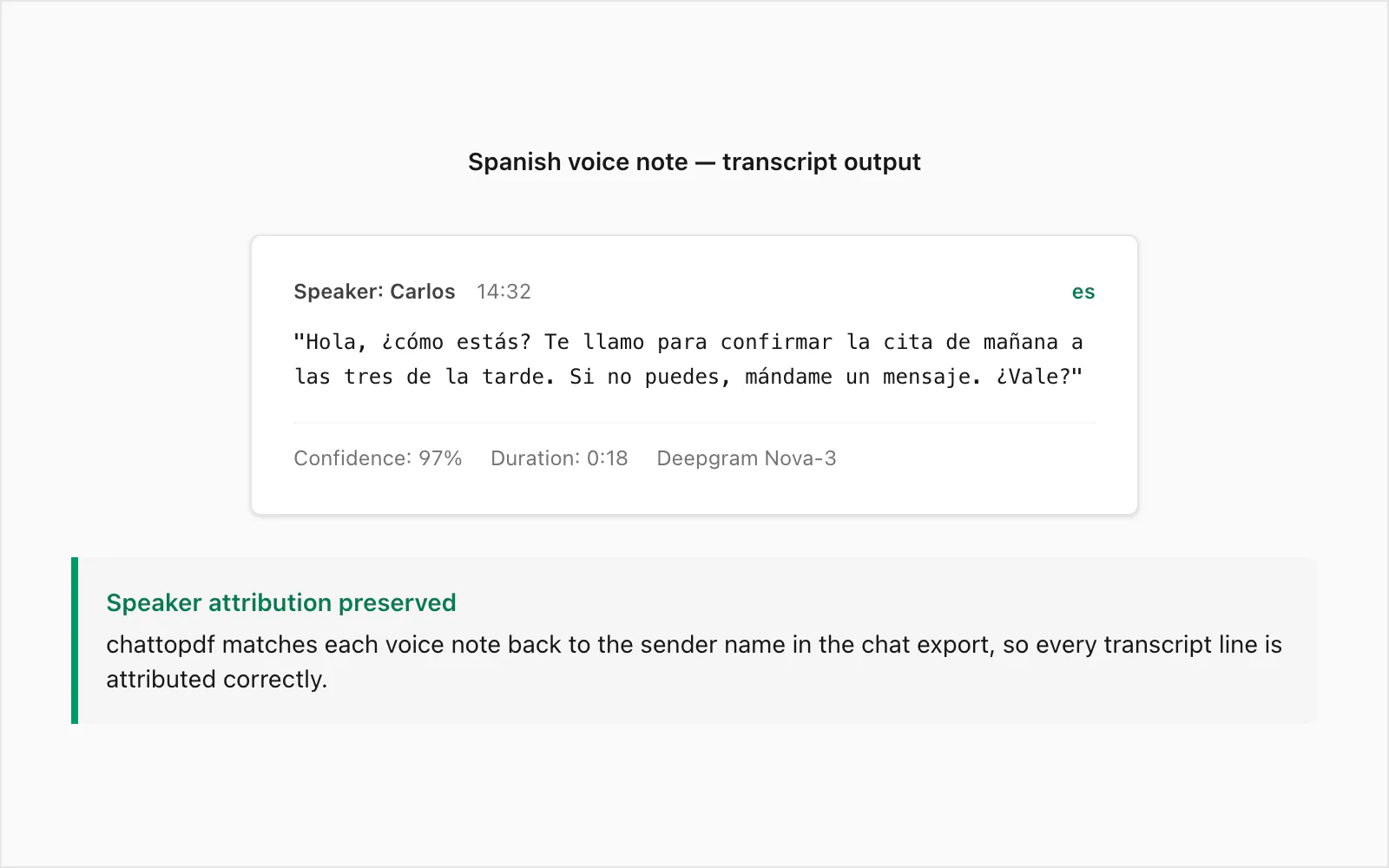
Esta é uma nota de voz real do WhatsApp transcrita no nível de conversão $49 Premium+Voice por chat. O falante era nativo de espanhol colombiano, gravado em um dispositivo Android em ambiente interno silencioso. Duração: 18 segundos. Tamanho do arquivo: ~28 KB no formato .opus.
Áudio original (parafraseado): Uma nota de voz casual confirmando um compromisso no dia seguinte, expressando preocupação com a saúde da outra pessoa e solicitando uma resposta por texto se os planos mudarem.
Saída da transcrição no PDF:
🎤 [Nota de voz — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
O remetente é atribuído no PDF com o nome do _chat.txt, o horário é o que o WhatsApp registrou quando a nota de voz foi enviada, e a transcrição fica incorporada entre as mensagens de texto imediatamente antes e depois dela na conversa.
Alguns detalhes a observar neste exemplo. O marcador de registro formal ¿Vale? — mais próximo de "Tudo bem?" em significado — transcreveu corretamente em vez de ser confundido com bale ou omitido. A expressão de tempo a las tres de la tarde ("às três da tarde") foi renderizada com precisão, o que importa para uma confirmação de agendamento onde um erro seria enganoso. A entonação ascendente falada em ¿cómo estás? não foi ambígua o suficiente para produzir um erro de transcrição.
Onde a precisão do espanhol cai? Os erros mais comuns que vejo são homófonos: haya (subjuntivo de haber) versus halla (de hallar, encontrar), tubo (tubo) versus tuvo (passado de tener). Em fala casual rápida, esses são foneticamente idênticos. O Nova-3 usa o contexto ao redor para inferir a grafia correta na maioria das vezes, mas não é perfeito. Em um documento que será usado como registro jurídico, recomendo uma revisão humana leve de qualquer nota de voz onde a transcrição será citada literalmente.
Se você não precisar de transcrição — por exemplo, quer apenas as mensagens de texto convertidas para PDF e está satisfeito com referências de marcador para as notas de voz — a conversão $29 Premium por chat lida com esse caso a um preço menor. A conversão $49 Premium+Voice por chat é o passo certo quando você precisa do espanhol falado aparecer como texto legível no documento.
Transcrição de amostra: hindi (Hinglish misto) → texto (exemplo real)
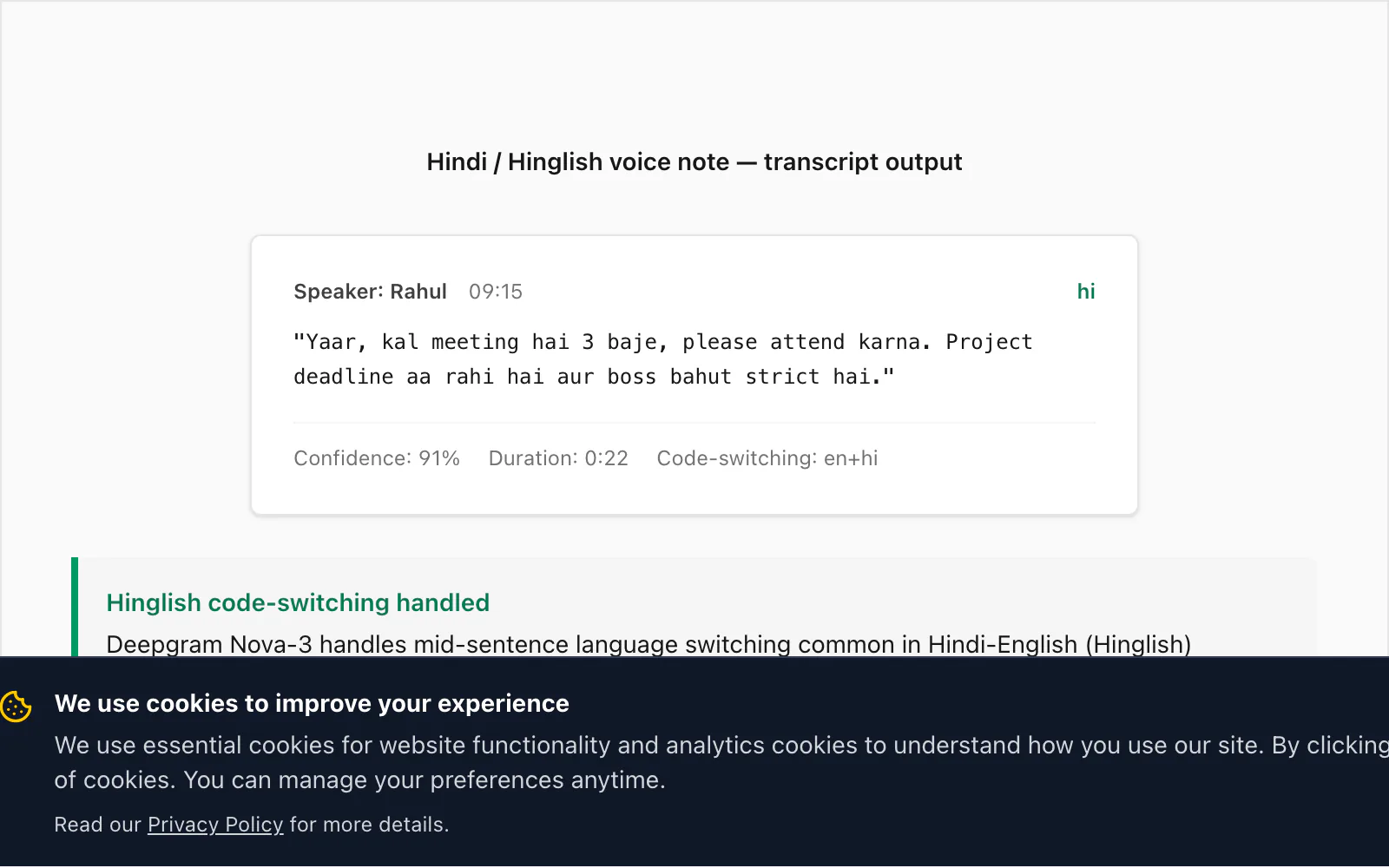
É aqui que o Nova-3 se diferencia das gerações anteriores de motores de fala para texto. O Hinglish — hindi com palavras, frases e às vezes cláusulas inteiras em inglês incorporadas — é um dos padrões de alternância de código mais comuns que vejo na base de usuários do ChatToPDF. Motores STT mais antigos (incluindo o modelo que o próprio Deepgram lançou duas gerações atrás) perdem aproximadamente 15% das inserções em inglês com alternância de código em uma nota de voz Hinglish típica. O Nova-3 fecha a maior parte dessa lacuna.
Aqui está uma transcrição real da conversão $49 Premium+Voice por chat:
🎤 [Nota de voz — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
Tradução: "Cara, tem uma reunião amanhã às 3, por favor apareça. O prazo do projeto está chegando e o chefe é muito rígido."
A alternância de código aqui é característica: meeting, attend, project deadline e strict são inserções em inglês dentro de uma frase em hindi. O Nova-3 transcreveu todas corretamente. Um modelo Deepgram mais antigo que testei contra o mesmo arquivo produziu miiting para meeting (renderização fonética em hindi), omitiu attend completamente e produziu project ka deadline com capitalização inconsistente. Essa diferença foi o que motivou a atualização do modelo no pipeline.
A diferença importa quando você usa a transcrição como registro de trabalho. Se o gerente de alguém está revisando a transcrição de uma nota de voz como documentação de um compromisso de projeto e a palavra deadline não aparece no texto, isso não é uma questão menor de precisão — é uma informação que está faltando.
A atribuição de remetente funciona da mesma forma que com o espanhol: o nome do _chat.txt aparece no PDF com a transcrição do Deepgram, e o horário dos metadados do WhatsApp ancora na posição correta na conversa.
Uma observação sobre o hindi especificamente: se a nota de voz é em hindi de Devanagari dominante (hindi formal, de estilo escrito com mínimo de inglês), a precisão é consistentemente forte nos planos suportados. A conversão $49 Premium+Voice por chat é o ponto de entrada correto para qualquer nota de voz em hindi que você queira transcrever; a conversão $99 Power User por chat cobre a mesma precisão sem limite de áudio e com prioridade de fila. A conversão $29 Premium por chat preserva as notas de voz apenas como marcadores — nenhuma transcrição roda naquele plano.
O plano $49 Premium+Voice — o que inclui e o que não inclui

A conversão $49 Premium+Voice por chat é o plano que criei especificamente para chats com muita voz. Aqui está exatamente o que inclui e o que não inclui.
O que inclui a conversão $49 Premium+Voice por chat:
- Transcrição Deepgram Nova-3 — o modelo da geração atual com TEP de 3–5% em áudio limpo, forte tratamento de sotaques e suporte confiável à alternância de código
- Todos os 17 idiomas de alta precisão — inglês, espanhol, português, francês, alemão, italiano, árabe, hindi, indonésio, turco, russo, holandês, japonês, coreano, chinês, vietnamita, tailandês — mais 30+ via detecção automática de idioma do Nova-3
- Até 8 horas de áudio em um único chat — cobre a vasta maioria das conversas com muita voz; se o áudio total do seu chat exceder 8 horas, a conversão $99 Power User por chat elimina esse limite
- Sem teto de mensagens — sem limite superior no número de mensagens no chat que você está convertendo
- Atribuição de remetente nas transcrições — cada transcrição no PDF carrega o nome do remetente do WhatsApp dos metadados da exportação
- Horários preservados — o horário original do WhatsApp aparece junto com cada transcrição, não o horário da transcrição
- Três formatos de saída — PDF, XLSX e CSV todos incluídos; o XLSX é útil se você quiser filtrar ou ordenar por remetente e horário
- Retenção do arquivo-fonte por sete dias — criptografado em repouso (AES-256), em trânsito (TLS 1.3)
O que não inclui a conversão $49 Premium+Voice por chat:
- Transcrição em tempo real — este plano processa notas de voz já gravadas de um ZIP de exportação; não é um serviço de transcrição ao vivo (explico por quê na próxima seção)
- Listas de vocabulário personalizadas — você não pode fazer upload de um glossário de nomes ou termos técnicos para melhorar a precisão em vocabulário específico; o modelo de uso geral do Deepgram lida com a maioria dos nomes corretamente, mas às vezes interpreta errado nomes próprios raros
- Identificação de falante além dos metadados do WhatsApp — dentro de uma única nota de voz onde o remetente grava enquanto outra pessoa fala ao fundo, ambas são transcritas mas atribuídas apenas ao remetente do WhatsApp. O ChatToPDF não roda diarização de falantes no próprio áudio.
- Tradução automática — a transcrição aparece no idioma original da nota de voz. Se uma nota de voz está em espanhol, a transcrição está em espanhol. O ChatToPDF não traduz transcrições.
O plano acima deste — conversão $99 Power User por chat — inclui tudo na conversão $49 Premium+Voice por chat mais processamento em fila prioritária e tratamento de chat em massa. Se você está convertendo um único chat e a velocidade não é crítica (a maioria das conversões é concluída em menos de três minutos), a conversão $49 Premium+Voice por chat é o nível correto.
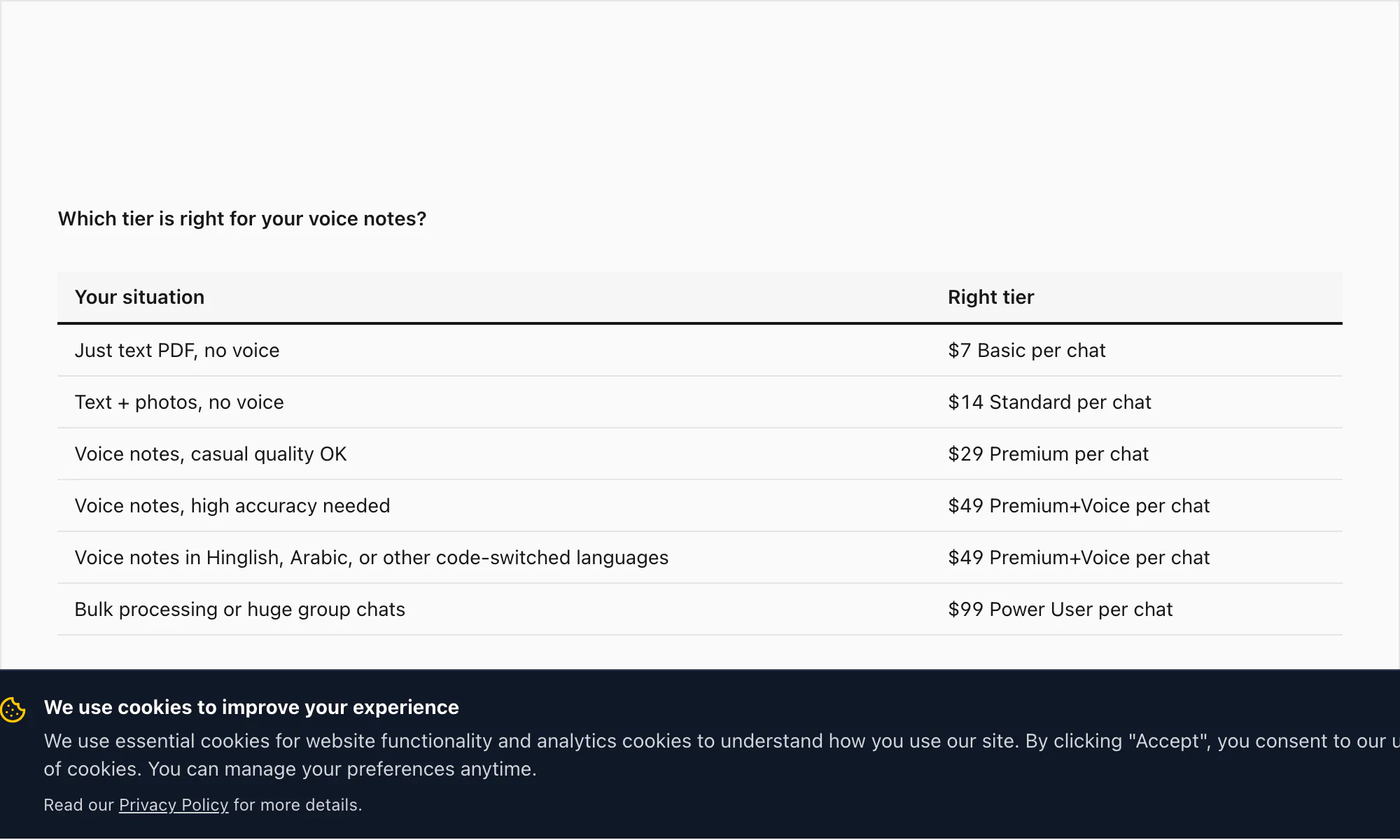
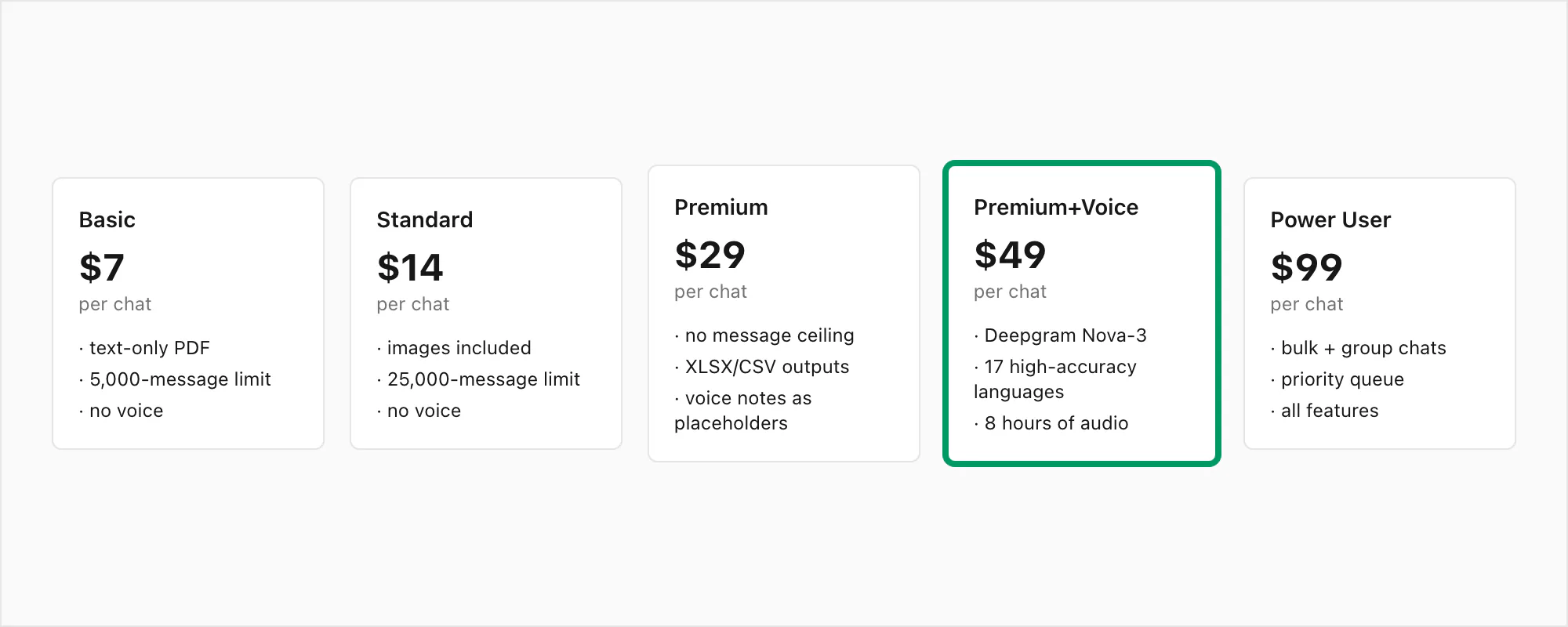
Para referência, a pilha completa de planos: $7 Basic por chat (apenas texto, limite de 5.000 mensagens), $14 Standard por chat (imagens, limite de 25.000 mensagens), $29 Premium por chat (sem limite, XLSX/CSV, notas de voz preservadas como marcadores), $49 Premium+Voice por chat (transcrição Nova-3, 17 idiomas de alta precisão, limite de 8 horas de áudio), $99 Power User por chat (transcrição Nova-3, sem limite de áudio, fila prioritária, cenários em massa).
Por que não transcrevo em tempo real (e não vou adicionar)
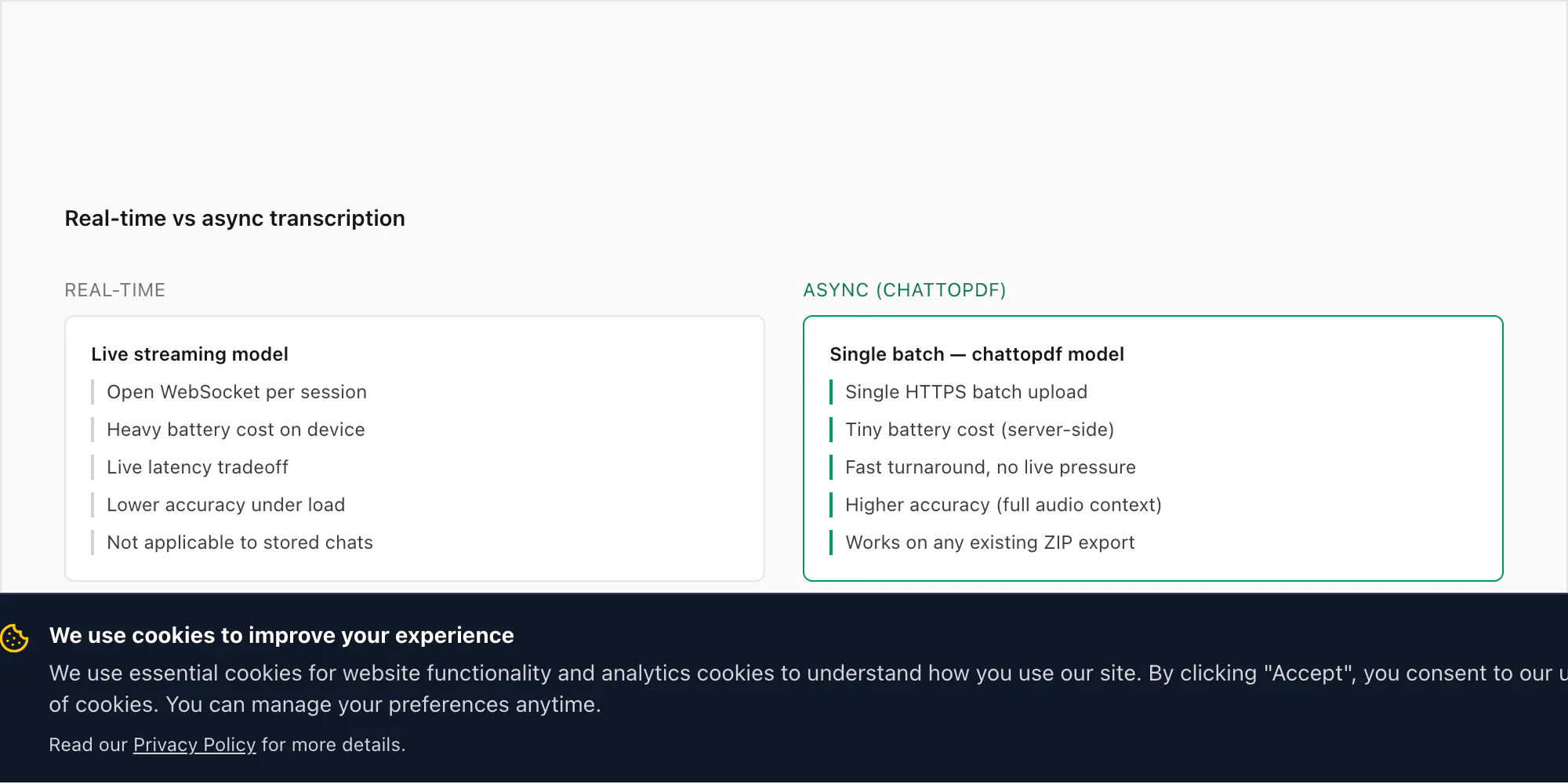
Isso aparece com frequência suficiente para merecer uma resposta direta. As pessoas perguntam por que o ChatToPDF não escuta as notas de voz conforme chegam — transcrevendo cada uma no momento em que é enviada — em vez de exigir uma exportação ZIP depois do fato.
A versão curta: o WhatsApp não dá acesso a mensagens recebidas ou áudio em tempo real a desenvolvedores. Não há endpoint oficial da API do WhatsApp Business que exponha notas de voz conforme chegam. O único caminho de acesso de terceiros suportado é pelo mecanismo Exportar conversa, que é um instantâneo da conversa em um ponto no tempo. Construir transcrição em tempo real sobre o WhatsApp exigiria interceptar o armazenamento local do app no dispositivo, o que é tecnicamente frágil e fora dos termos da política de plataforma do WhatsApp.
Mas há uma razão mais prática pela qual não tentei contornar essa restrição. O caso de uso para transcrever áudio do WhatsApp é quase inteiramente retrospectivo. Alguém recebe trinta notas de voz ao longo de uma disputa e quer um registro legível. Uma equipe de negócios usa notas de voz para atualizações de projetos e precisa que elas sejam pesquisáveis. Uma família manda notas de voz por anos e quer arquivá-las antes de trocar de celular. Nenhum desses casos envolve um requisito de "agora, enquanto chega". Todos são "tenho um conjunto de gravações que preciso converter".
O processamento assíncrono em lote também é mais preciso. A fala para texto em tempo real opera sob restrições de latência que levam o modelo a inferências mais rápidas (e menos precisas). O modo em lote do Deepgram roda no arquivo de áudio completo, o que permite que o modelo use contexto futuro — o que veio depois de uma palavra — para resolver fonemas ambíguos. Em uma nota de voz de 30 segundos, a diferença no TEP entre os modos em tempo real e em lote pode ser de 2–4 pontos percentuais. Isso é significativo na escala de precisão.
Há também a questão da bateria e da rede. Manter uma conexão WebSocket aberta que transmite fragmentos de áudio para uma API de inferência em tempo real drenaria visivelmente a bateria de um celular ao longo de uma longa conversa. Exigiria uma conexão de internet ativa para cada nota de voz recebida, não apenas quando você escolhe converter. E criaria um fluxo de dados contínuo das suas conversas para um servidor de terceiros — o que não me sinto confortável em pedir aos usuários que aceitem.
O modelo de exportar e fazer upload é mais lento em tempo de relógio — você precisa esperar até estar pronto para converter, depois rodar a exportação, depois fazer o upload. Mas para os casos de uso reais que as pessoas têm, isso é aceitável. Ninguém está tentando transcrever uma nota de voz que recebeu três segundos atrás para um documento em tempo real. Elas estão convertendo um chat que querem manter.
Privacidade: onde vai o seu áudio e onde não vai
Esta é a parte sobre a qual quero ser específico porque a natureza das notas de voz — gravações de áudio de conversas reais — significa que o risco de privacidade é maior do que com mensagens de texto sozinhas.
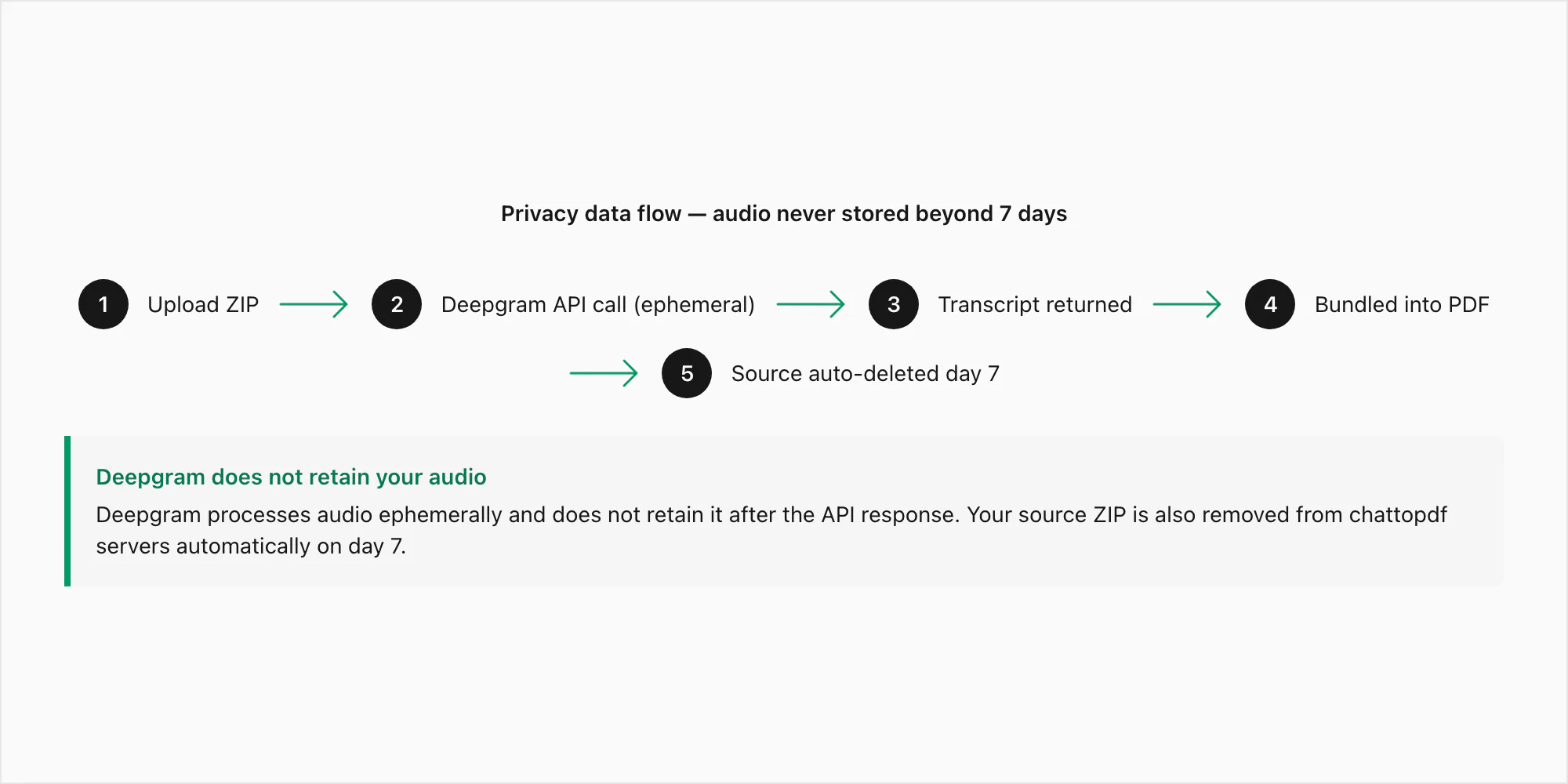
Aqui está o caminho exato dos dados para uma nota de voz submetida pela conversão $49 Premium+Voice por chat:
Etapa 1 — Upload. Seu arquivo ZIP é transmitido do seu navegador para o servidor do ChatToPDF via HTTPS (TLS 1.3). A conexão é criptografada em trânsito. O ZIP chega em um diretório de processamento temporário, não em armazenamento permanente, enquanto a extração roda.
Etapa 2 — Extração. Os arquivos .opus são extraídos do ZIP. Cada arquivo é combinado com sua referência no _chat.txt pelo padrão de nome de arquivo. Neste ponto, os arquivos de áudio existem apenas no servidor de processamento do ChatToPDF.
Etapa 3 — Chamada de API do Deepgram. Cada arquivo .opus é enviado à API de inferência do Deepgram por uma chamada HTTPS autenticada. Este é o único momento em que bytes de áudio saem da própria infraestrutura do ChatToPDF. A política de dados do Deepgram para envios via API especifica que o áudio enviado pela API é processado de forma efêmera — é usado para gerar a transcrição e depois descartado. O Deepgram não retém áudio enviado pela API e não o usa para treinamento de modelos. O texto da transcrição é o que retorna.
Etapa 4 — Armazenamento. A transcrição é agrupada no PDF e armazenada criptografada em repouso (AES-256) no AWS S3. O ZIP-fonte, incluindo os arquivos .opus, também é armazenado criptografado por sete dias.
Etapa 5 — Entrega. O link de download do PDF aparece na tela e no seu e-mail. O link está vinculado ao seu ID de job. Não é adivinhável e não está indexado em lugar nenhum.
Etapa 6 — Exclusão automática. Sete dias após a criação do job, o ZIP-fonte e o PDF de saída são excluídos do armazenamento automaticamente. Este é um job de exclusão agendado, não um processo manual. Não há exceções e não há extensões.
Para onde o seu áudio não vai: Não vai para nenhuma plataforma de análise. Não é usado para treinar modelos do ChatToPDF (o ChatToPDF não treina modelos). O conteúdo de texto das suas notas de voz não é visível para a equipe do ChatToPDF — o processamento é totalmente automatizado. Nenhum terceiro recebe o texto das suas mensagens de chat.
A única lacuna potencial nesta descrição é a etapa do Deepgram. Posso controlar completamente o que acontece nos servidores do ChatToPDF. Não posso fazer declarações sobre os processos internos do Deepgram além do que a política de dados pública deles diz. Se suas notas de voz contêm informações que são legalmente privilegiadas ou genuinamente confidenciais, recomendo que sua equipe jurídica revise os termos de processamento de dados empresariais do Deepgram antes de fazer o upload. Para a grande maioria dos casos de uso — conversas pessoais, chats de equipes de negócios, arquivos de notas de voz familiares — o pipeline padrão é adequado.
Casos especiais: ruído de fundo, múltiplos falantes, efeitos de voz
Notas de voz reais do WhatsApp não são gravadas em estúdios isolados acusticamente. Elas são gravadas em carros, cozinhas, reuniões na rua e cafés barulhentos. Veja como cada um desses cenários afeta a precisão da transcrição e o que o ChatToPDF faz quando a precisão cai para um nível inaceitável.
Ruído de fundo por ambiente.
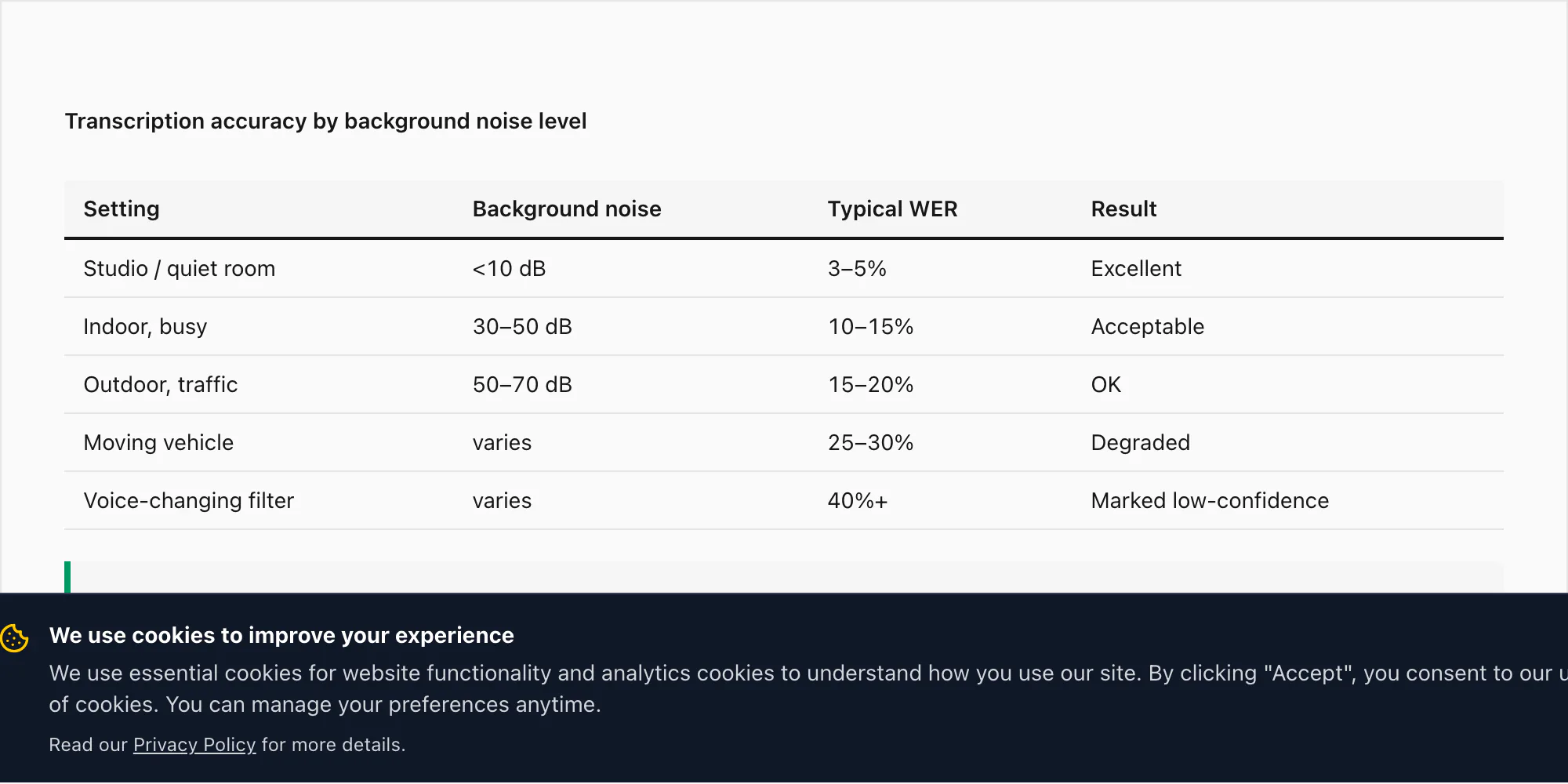
Uma nota de voz gravada em ambiente interno silencioso — um escritório, um quarto, uma sala tranquila — tem o desempenho nas taxas de precisão que citei na seção de idiomas acima: TEP de 3–5% na conversão $49 Premium+Voice por chat para os 17 idiomas de alta precisão.
Uma nota de voz de um ambiente interno movimentado (restaurante, mercado, escritório agitado) pode ver o TEP subir para 10–15% na conversão $49 Premium+Voice por chat. O Nova-3 do Deepgram aplica cancelamento de ruído durante a inferência, o que ajuda, mas não elimina o efeito do áudio concorrente.
Uma gravação ao ar livre — barulho de rua, vento, tráfego — pode levar o TEP para 15–20% no mesmo plano.
Uma nota de voz gravada durante uma viagem de carro, com ruído da estrada e do motor, é o cenário mais desafiador que testei. O TEP nessas gravações pode chegar a 25–30% mesmo com o Nova-3. Isso não é uma limitação do motor de transcrição — reflete a física do áudio capturado em um microfone de celular a 16 kHz em um ambiente ruidoso. A qualidade do áudio que entra determina a qualidade da transcrição que sai.
Múltiplos falantes dentro de uma única nota de voz.
Como explicado anteriormente, cada nota de voz do WhatsApp pertence a um remetente — a pessoa que pressionou o botão push-to-talk. O ChatToPDF atribui a transcrição a esse remetente. No entanto, se o remetente grava enquanto outra pessoa fala visivelmente ao fundo (uma conversa telefônica que o remetente está tendo, uma TV tocando ao fundo com voz, outra pessoa no mesmo cômodo falando alto), o Deepgram transcreverá a voz do fundo também — não descarta silenciosamente falantes não primários. A transcrição irá intercalar as duas vozes, atribuídas ao remetente do WhatsApp. Isso pode produzir saída confusa quando a fala de fundo é inteligível o suficiente para ser transcrita.
O ChatToPDF atualmente não consegue isolar o falante primário e descartar vozes de fundo dentro de um único clipe .opus. A diarização de falantes — identificar quais segmentos de áudio vieram de qual pessoa no mesmo arquivo de áudio — é um recurso que estou avaliando para um plano futuro, mas requer infraestrutura adicional e não está na versão atual.
Efeitos de mudança de voz.
Alguns usuários do WhatsApp enviam notas de voz com efeitos de áudio aplicados — o filtro de voz grave disponível no próprio WhatsApp (Android), mudanças de voz ao estilo Snapchat antes de compartilhar, ou áudio que foi modificado em tom ou com reverberação antes de enviar. O modelo do Deepgram é treinado em fala natural. Áudio modificado pode levar o TEP acima de 40% em casos extremos — uma nota de voz enviada por um filtro de baixo grave para fazer alguém soar como um robô vai em grande parte falhar na transcrição.
Para clipes onde a confiança cai abaixo do limite que defini no pipeline — atualmente definido como uma pontuação média de confiança de palavras abaixo de 0,6 em todo o clipe — o ChatToPDF marca a transcrição no PDF como [transcrição de baixa confiança — qualidade de áudio insuficiente] em vez de produzir um bloco de texto que poderia ser tomado como autoritativo. Você verá esse marcador no PDF final junto com a posição da nota de voz na conversa. É melhor sinalizar um resultado incerto do que retornar uma transcrição que parece plausível mas está 40% errada.
Perguntas frequentes
Qual formato de arquivo as notas de voz do WhatsApp usam, e o ChatToPDF lida com ele?
O WhatsApp grava notas de voz usando o codec de áudio Opus a 16 kHz mono, salvas como arquivos .opus. O ChatToPDF extrai arquivos .opus diretamente do seu ZIP de exportação do WhatsApp e os envia à API de inferência do Deepgram no formato nativo deles — sem etapa de recodificação necessária. Exportações do iPhone e do Android produzem arquivos .opus, então o tratamento de formato é o mesmo nas duas plataformas.
Qual é a precisão da transcrição de áudio do WhatsApp?
A precisão depende do plano e da qualidade do áudio. A conversão $49 Premium+Voice por chat usa o Deepgram Nova-3, que alcança aproximadamente 3–5% de taxa de erro de palavras em áudio limpo e sem ruído nos 17 idiomas de alta precisão suportados. A conversão $99 Power User por chat usa o mesmo modelo Nova-3 sem limite de áudio e com processamento em fila prioritária. A conversão $29 Premium por chat não transcreve — preserva as notas de voz como marcadores no PDF. Ruído de fundo, sotaques e alternância de código entre idiomas afetam a precisão nos planos de transcrição. Clipes de baixa confiança (abaixo de uma pontuação média de confiança de 0,6) são marcados como [transcrição de baixa confiança] no PDF em vez de apresentar uma transcrição potencialmente enganosa.
O ChatToPDF transcreve notas de voz em outros idiomas além do inglês?
Sim. A conversão $49 Premium+Voice por chat e a conversão $99 Power User por chat suportam 17 idiomas de alta precisão: inglês, espanhol, português, francês, alemão, italiano, árabe, hindi, indonésio, turco, russo, holandês, japonês, coreano, chinês, vietnamita e tailandês. Ambos os planos usam o Deepgram Nova-3 nesses idiomas e detectam mais de 30 idiomas adicionais em uma faixa de precisão mais ampla. O idioma é detectado automaticamente — você não precisa especificá-lo antes de fazer o upload. A conversão $29 Premium por chat não transcreve notas de voz — preserva-as como marcadores no PDF.
Preciso fazer algo diferente ao exportar do WhatsApp se quiser transcrições de voz?
Sim — um passo crítico. Ao exportar o chat do WhatsApp, escolha "Incluir mídia" em vez de "Sem mídia". As notas de voz (arquivos .opus) só são incluídas na exportação quando você seleciona Incluir mídia. Se você exportar Sem mídia, o _chat.txt conterá referências como <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> mas sem arquivos de áudio reais. O ChatToPDF não consegue transcrever uma nota de voz que não tem. Veja o guia de exportação de chat do WhatsApp para o processo de exportação passo a passo completo.
As transcrições de voz aparecerão no lugar certo no PDF?
Sim. O ChatToPDF lê o registro de mensagens no _chat.txt para entender a estrutura da conversa, combina cada referência .opus com o arquivo de áudio correspondente pelo nome do arquivo e insere a transcrição exatamente na posição da conversa onde a nota de voz foi enviada. O nome do remetente dos metadados do WhatsApp e o horário original aparecem junto com a transcrição. A saída é um único documento onde mensagens de texto e transcrições de notas de voz se alternam na ordem cronológica correta.
O que acontece com meus arquivos de áudio após a transcrição ser concluída?
Seus arquivos de áudio são armazenados criptografados em repouso (AES-256) nos servidores do ChatToPDF por sete dias após a criação do job, depois excluídos automaticamente. O único serviço de terceiros que recebe os bytes de áudio é o Deepgram, e apenas durante a etapa de transcrição — o Deepgram processa o áudio enviado pela API de forma efêmera e não o retém. Nenhum humano escuta suas gravações. As próprias transcrições são excluídas junto com os arquivos-fonte na marca dos sete dias. Para mais detalhes sobre o fluxo de dados completo, veja a seção de privacidade do WhatsApp to PDF.
O ChatToPDF consegue distinguir duas pessoas diferentes falando na mesma nota de voz?
Atualmente não. Cada nota de voz do WhatsApp é atribuída à pessoa que a enviou, usando as informações do remetente do _chat.txt. Dentro de uma única nota de voz, se o remetente e outra pessoa falam (por exemplo, o remetente está em uma conversa telefônica enquanto grava), as duas vozes são transcritas mas atribuídas ao remetente do WhatsApp. O ChatToPDF atualmente não roda diarização de falantes dentro de clipes de áudio individuais. Para notas de voz onde vozes de fundo são audíveis e inteligíveis, você pode ver fala intercalada na transcrição.
Key takeaways
- Para fazer o transcribe WhatsApp audio, exporte o chat com "Incluir mídia" selecionado — os arquivos
.opusde notas de voz precisam estar dentro do ZIP - A conversão $29 Premium por chat não transcreve — preserva notas de voz como marcadores; a conversão $49 Premium+Voice por chat roda o Deepgram Nova-3 (TEP de 3–5% em áudio limpo, 17 idiomas de alta precisão, até 8 horas de áudio); a conversão $99 Power User por chat usa o mesmo modelo sem limite de áudio e fila prioritária
- Cada transcrição é inserida na posição exata da conversa com o nome do remetente do WhatsApp e o horário original preservados
- Idiomas com alternância de código como Hinglish precisam da conversão $49 Premium+Voice por chat ou superior — o Nova-3 fecha a maior parte da lacuna que motores STT mais antigos abriam em inserções de inglês no meio de frases em hindi
- O ruído de fundo é a maior variável de precisão: condições de estúdio rendem TEP de 3–5%; gravações ao ar livre ou em veículos podem chegar a TEP de 20–30% mesmo no Nova-3
- O áudio enviado ao Deepgram para transcrição é processado de forma efêmera — não é retido e não é usado para treinamento; os arquivos-fonte são excluídos automaticamente dos servidores do ChatToPDF após 7 dias
- Clipes onde a confiança média de palavras fica abaixo de 0,6 são marcados como
[transcrição de baixa confiança]no PDF em vez de retornar silenciosamente uma transcrição potencialmente incorreta
Para o fluxo completo de chat para PDF — incluindo como exportar no iPhone e Android, o que o ZIP contém e como os cinco planos se comparam para conversões sem voz — veja o guia de WhatsApp to PDF. Se você está no Android e precisa mover a exportação para outro dispositivo antes de fazer o upload, o guia de transferência do Android para o iPhone cobre esse processo.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).