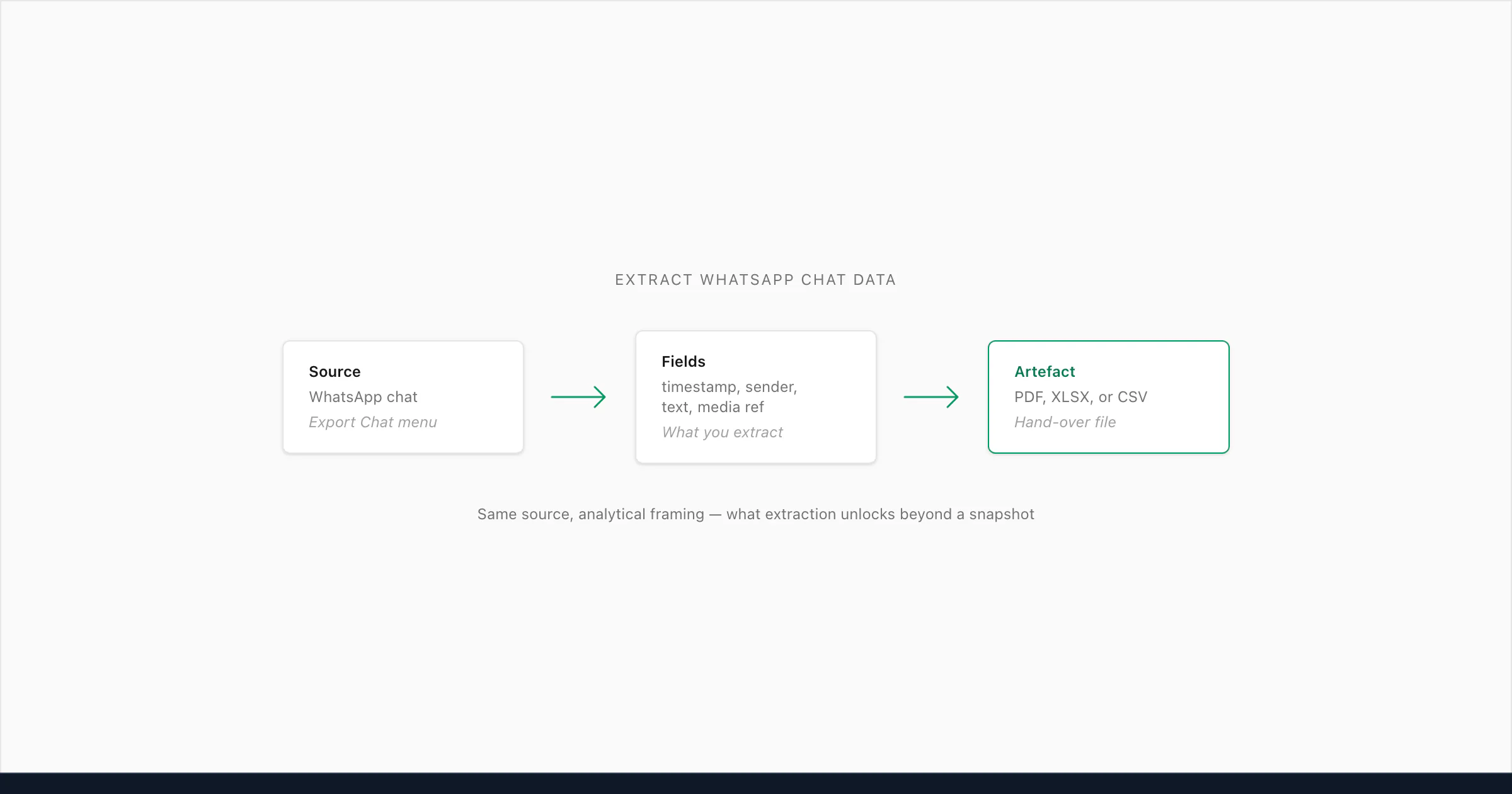
To extract WhatsApp chat data, use WhatsApp's Export Chat feature — the resulting ZIP contains _chat.txt with every field you need: message text, sender name, timestamp, and references to attached media files. There is no separate "extract" button; the export IS the extraction. From the ZIP you can parse structured data for analysis, build a spreadsheet, or upload to ChatToPDF for a paginated, sender-attributed PDF.
What "extract" means in a WhatsApp context
I get the search term "extract whatsapp" most often from people who are not casual users — analysts pulling a record together for a court matter, HR investigators working through a workplace incident, researchers wanting message data for a study, developers thinking about parsing structured fields out of a chat. The word "extract" carries an analytical edge that "export" does not. Export sounds like backup. Extract sounds like work.
I want to settle the linguistic question first: there is no separate "Extract" button anywhere in WhatsApp. The same Export Chat menu that powers the casual export flow is the only mechanism the app gives you for getting data out, as WhatsApp's own FAQ confirms. What changes between an "export" and an "extract" workflow is not the tool, it is the intent. The companion guide What "export chat" actually does on WhatsApp walks through the menu mechanics in detail, and the WhatsApp chat export pillar is the deeper reference on the file format the menu produces.
So when someone asks "how do I extract WhatsApp chat data?", I read it as three questions sitting on top of each other:
- What does the export feature actually give me to extract from?
- What discrete fields are in there — what can I pull out?
- What do I do with those fields once I have them?
The rest of this guide is structured around those three questions, with the working assumption that you arrived here because you have an analytical or evidentiary or technical use case in mind, not just casual archival.
What data you can actually extract
The Export Chat menu produces a ZIP archive. Inside that ZIP is a single plain-text file called _chat.txt plus, optionally, a flat folder of attached media (photos, voice notes, documents). The _chat.txt is the structured data — every message in the chat appears as one line, with a predictable shape that any parser or human reader can pull apart.
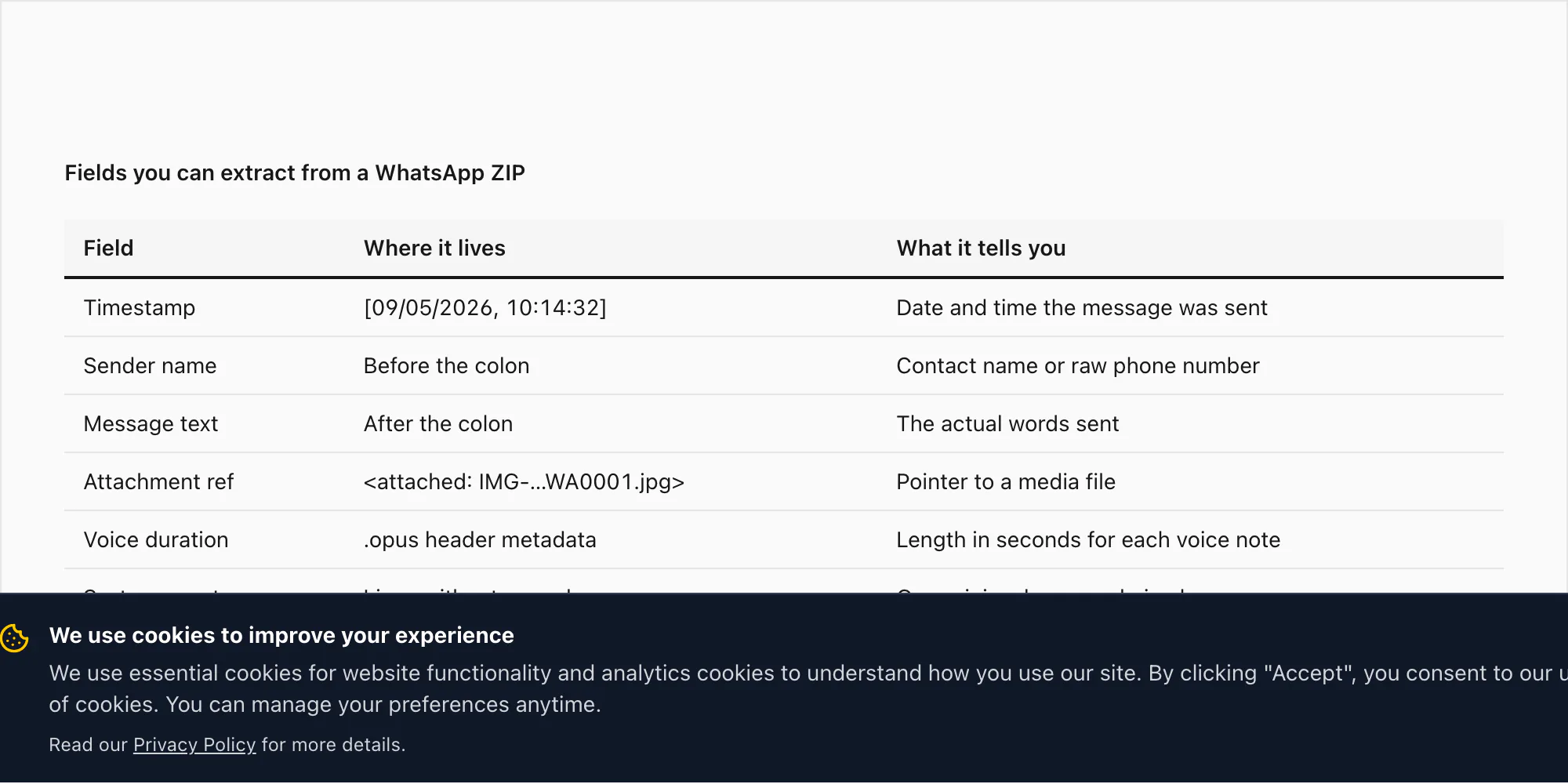
Each line in _chat.txt carries four primary fields you can extract:
| Field | Where it lives in _chat.txt | What it tells you |
|---|---|---|
| Timestamp | Square brackets at line start: [09/05/2026, 10:14:32] | Date and time the message was sent, locale-formatted |
| Sender name | After the timestamp, before the colon: Alice: | Contact name from your phonebook, or raw phone number if not saved |
| Message text | After the colon to end of line | The actual words sent — emoji, links, mentions, all preserved |
| Attachment reference | Filename in angle brackets: <attached: IMG-20260109-WA0001.jpg> | Pointer to a file in the media folder, or <Media omitted> if you exported Without Media |
Beyond those four primaries, a careful extraction pulls out several derived fields:
- Voice note duration:
.opusfiles in the media folder carry duration metadata in their headers; a voice note transcription pipeline (Deepgram Nova-3 on the chattopdf $49 Premium+Voice tier) reads that duration and the audio content together. - Chat title and participants: the very first line of
_chat.txtis a system message announcing chat creation; for groups, subsequent system lines record joins, leaves, and admin changes — these let you reconstruct the participant list and timeline. - Message type signal: WhatsApp encodes deleted messages as the literal text "This message was deleted", and edited messages as the text appended with "<This message was edited>" — both are extractable as separate categories.
- Forwarded indicator: forwarded messages show the literal text "Forwarded message" as a bracketed prefix, letting you flag relayed content.
- System events: group creation, name changes, participant adds and removes, encryption-key rotations, all appear as system-attribution lines you can filter from sender-attributed lines.
What you cannot extract from the export, no matter how careful the parser:
- Read receipts (delivery and read timestamps are not in the export)
- Reactions (emoji reactions to messages are dropped at export time)
- Stickers as images (they appear as references but the actual sticker file may not be bundled)
- Calls (voice and video calls are not recorded at all)
- Disappearing messages that have already expired
- Messages older than the most-recent 40,000 in the chat — WhatsApp caps the export there
That ceiling matters for evidence work especially. If you are extracting data from a long-running group chat, anything before message 40,001-from-the-end is not in the export, full stop. There is no workaround inside WhatsApp itself — the only way to reach further back is reading the WhatsApp database directly via a tool like Android Backup Extractor or iMazing, which requires a local backup or device-level access.
Extract vs export — same source, different framing
People who arrive at chattopdf via "extract whatsapp" search terms have a different mental model than people who arrive via "export whatsapp" terms. I treat them as the same job in the toolchain — both flows start with the same Export Chat tap on the phone — but the framing matters because the downstream artefact is different.
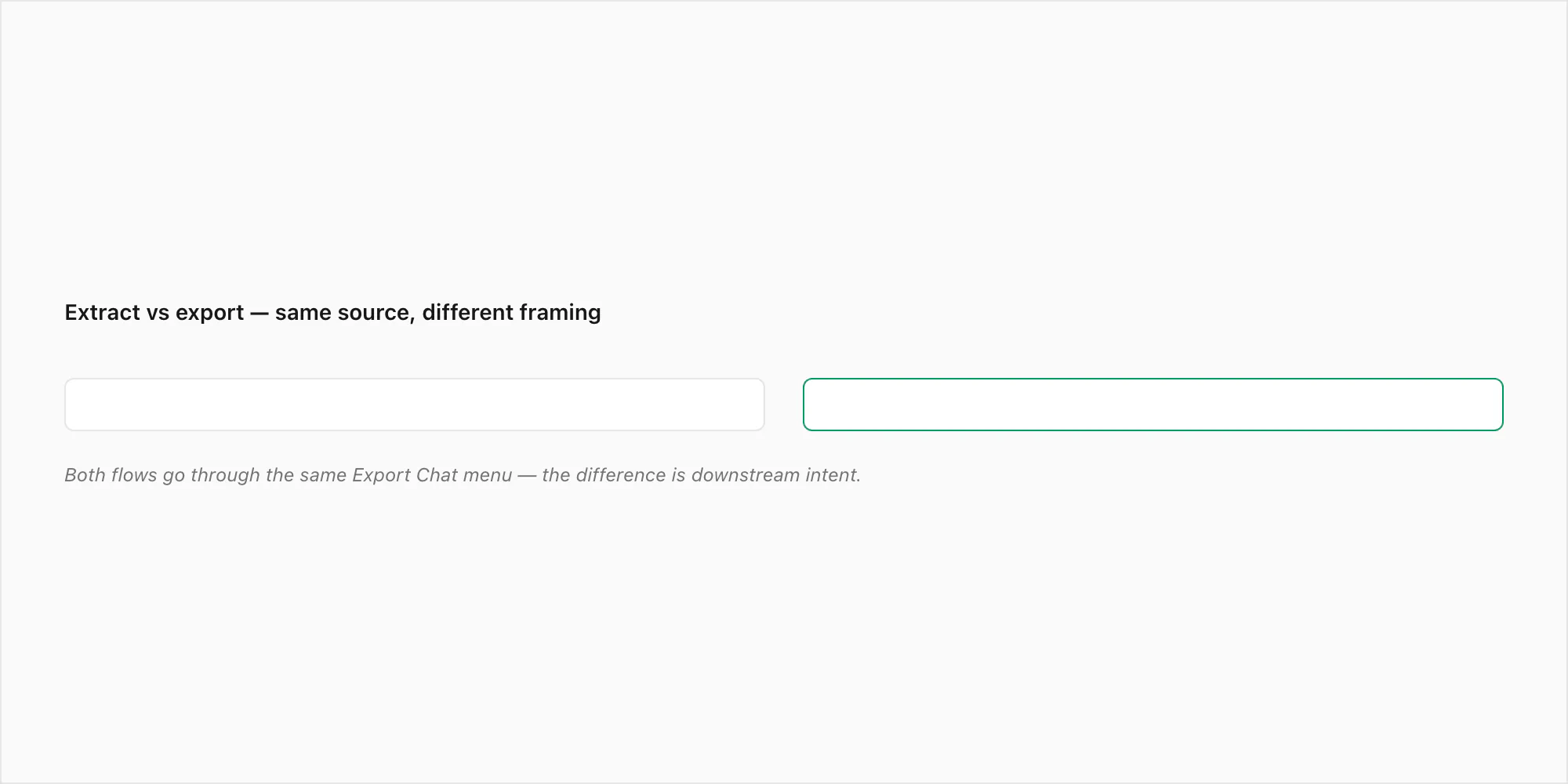
An export mindset treats the result as a snapshot. The user wants a record they can store, share, or revisit. The artefact is the ZIP itself, or a PDF, or a printout — something you set down and walk away from. The pillar WhatsApp chat export is written for that audience.
An extract mindset treats the result as raw material. The user wants to do something with the data — pull specific fields, filter by date range, count messages from one participant, build a chronology, run a search across thousands of lines, generate a structured artefact for a specific downstream use. The ZIP is not the destination, it is the input.
Both flows go through the same _chat.txt, the same media folder, the same 40,000-message ceiling. What changes is how much processing happens after the ZIP and what comes out at the end. A casual exporter ends with the ZIP itself or a printed PDF and is done. An extractor parses, filters, transforms, sometimes hands the result over to a structured artefact like an XLSX spreadsheet or a sender-attributed PDF formatted for evidence.
This is why I wrote a dedicated guide for the extract framing rather than only the export one. The mechanics are the same; the user need is not.
Why people extract — five real use cases
I see five recurring jobs people are trying to do when they search "extract whatsapp" rather than "export whatsapp". Naming them helps because each one points to a different downstream artefact and a different chattopdf tier choice.

| Use case | What gets extracted | Downstream artefact |
|---|---|---|
| Legal evidence | Date-ranged messages with sender attribution, timestamps preserved exactly, attachments inline | Sender-attributed PDF with cover page (chat metadata, participants, range) |
| HR investigation | Selected participants' messages, system events showing joins and leaves, deletion markers | PDF + XLSX so HR can filter rows alongside reading prose |
| Research / academic | Full corpus, anonymised sender names, message counts and timestamps for analysis | CSV or XLSX for spreadsheet analysis |
| Personal archival | Full chat with photos, voice notes (transcribed if meaningful), readable presentation | Paginated PDF you can email, print, or store |
| Migration to other tools | Plain text + media references in a portable format another tool can ingest | Either the raw ZIP itself, or a parsed CSV |
The legal-evidence use case is the one I see most often, especially for the whatsapp-evidence-court-pdf pillar. What an evidence-builder wants is not just the message text — it is the full provenance: sender attribution preserved, timestamps in the exact format the chat produced, attachments embedded inline so a reviewer can see what was sent without chasing separate files, and a cover page declaring chat metadata. The $14 Standard per chat tier handles that for most personal chats, and the $29 Premium per chat tier extends to longer matters and adds a structured XLSX/CSV alongside the PDF.
The HR investigation use case sits next to legal but with a tighter scope. Investigators usually want a date-bounded slice of a group chat, often filtered to specific participants, with system events visible (so they can see who joined the conversation and when). The extract here is not the full chat — it is a focused subset, often hand-selected from a larger corpus.
The research and academic use case is the one where extraction looks most like data work. The user wants the corpus as structured rows for spreadsheet or statistical analysis. The Premium tier's XLSX/CSV output is the closest fit; advanced users sometimes parse _chat.txt themselves with a Python script.
Personal archival is the most common casual use case but rarely shows up in "extract whatsapp" searches — those users usually search "export" or "save" or "convert" instead.
Migration — moving a chat into another platform or analysis tool — is rarer but real. Some users want the ZIP itself as the artefact because they will feed it into a tool that already understands WhatsApp's export format.
How to extract — tooling and the manual fallback
The mechanics of getting the data out are the same Export Chat menu I cover in the pillar guide and the export-chat-whatsapp companion. On iPhone you tap the chat title, scroll past participants, and tap Export Chat. On Android you tap the three-dot overflow icon, then More, then Export chat. WhatsApp Web mirrors the Android path. Pick Including Media if you want attachments in the artefact, Without Media if only the text matters.
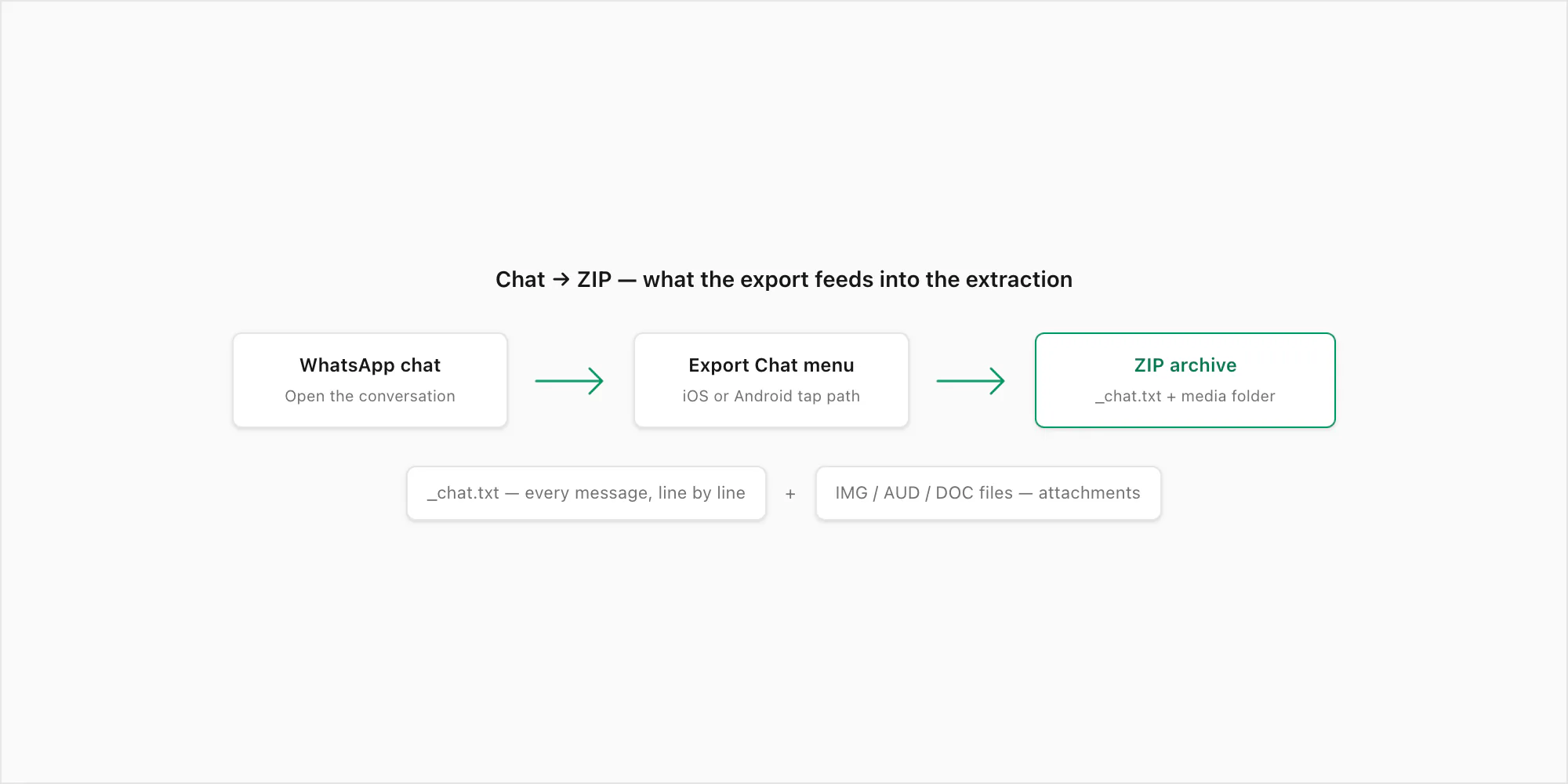
Once you have the ZIP, the actual extraction work — what fields you pull, what shape they end up in — is a tooling choice.

| Approach | What you get | Effort and tradeoffs |
|---|---|---|
| Read _chat.txt manually in a text editor | All the data, no structure | Free and immediate but unreadable past a few hundred messages |
| Custom Python or JS parser | Whatever fields you write code to pull | Total control, but you write and maintain the parser |
| chattopdf.app — paginated PDF | Sender-attributed PDF, inline photos, optional voice transcription | $14 Standard per chat, ~30 seconds, no install — what most extract-to-artefact users actually want |
| chattopdf.app — XLSX/CSV alongside PDF | Structured rows: timestamp, sender, text, attachment columns | $29 Premium per chat, both artefacts in one conversion |
The manual approach — reading _chat.txt in a text editor — is the path of last resort. It is technically free and works for any chat size, but a 5,000-message chat is roughly 250 KB of text in one continuous flow with no formatting, no line breaks between conversations, no visual hierarchy. Useful for grepping a specific phrase, useless for any kind of presentation.
The custom-parser approach is the developer route. The _chat.txt format is well-documented, dates parse predictably (with locale gotchas — see the meaning guide for the format-vs-meaning distinction), and a hundred lines of Python or JavaScript will pull out timestamp, sender, text, and attachment-reference columns. I have seen this work for academic researchers and for engineering teams building custom tooling, but it is overkill for most use cases.
The chattopdf path is what fills the middle. You upload the ZIP, the parser pulls every field automatically, and the output is a sender-attributed PDF (Standard tier) or PDF + XLSX/CSV (Premium tier). Roughly 30 seconds end to end, no code to write, no app to install.
From extracted data to a PDF you can hand over
The most common thing people want once they have extracted the data is a clean artefact they can give to someone else — a lawyer, an HR reviewer, a court, a research collaborator, an archive. PDF is the format that matches that need most often, because it is paginated, printable, and unambiguous about what was sent and when.
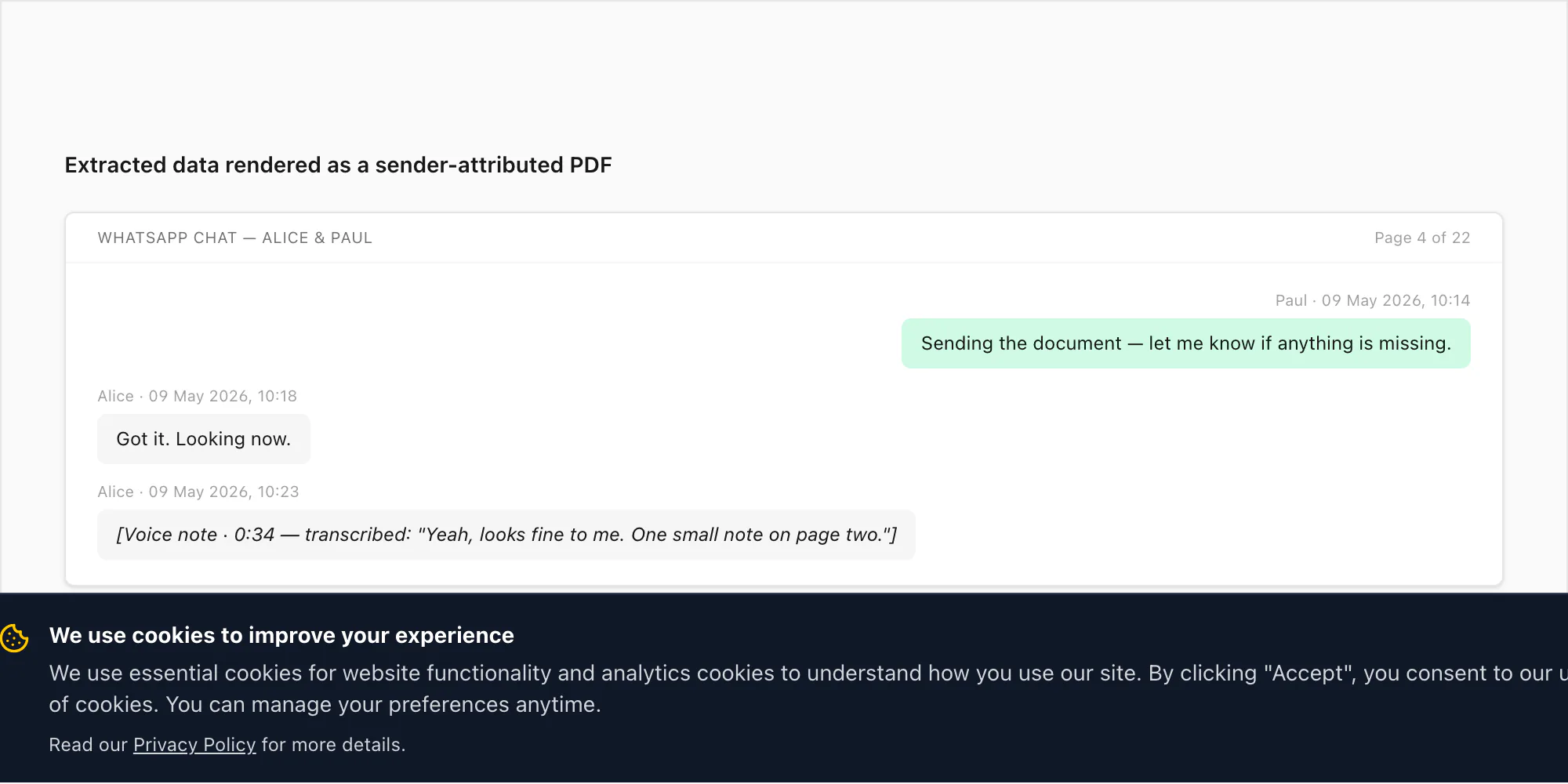
The PDF that chattopdf produces from a WhatsApp export preserves every field the underlying _chat.txt carries. Sender attribution sits above each message bubble. Timestamps appear in a predictable, locale-clean format ("Paul · 09 May 2026, 10:14"). Photos that were bundled at export time appear inline at the right point in the conversation, attributed to whoever sent them. Voice notes appear as placeholders on the Standard and Premium tiers, and as fully transcribed text on the Premium+Voice tier (using Deepgram Nova-3). The cover page carries chat metadata — participants, date range, message count — making provenance unambiguous for whoever reviews the document.
For an evidence workflow, this is the hand-over artefact. For an HR investigation, it is the read-it file alongside the XLSX for filter work. For research or archival, it is the canonical record. The full pipeline — chat → Export Chat → ZIP → chattopdf parser → PDF — runs through every field the extraction produces, including the ones that are easy to miss in a manual read (forwarded indicators, deleted-message markers, system events, edit markers).
The companion spoke Export WhatsApp chat to PDF — the real path walks the export-mindset version of this same flow. The mechanics are identical; the framing differs.
Pricing for the extract-to-PDF path
Each conversion is a single payment for a single chat. There is no recurring billing, no account-level access, no ongoing commitment — every conversion is real work against a specific snapshot of your chat data, so each conversion is priced on its own.
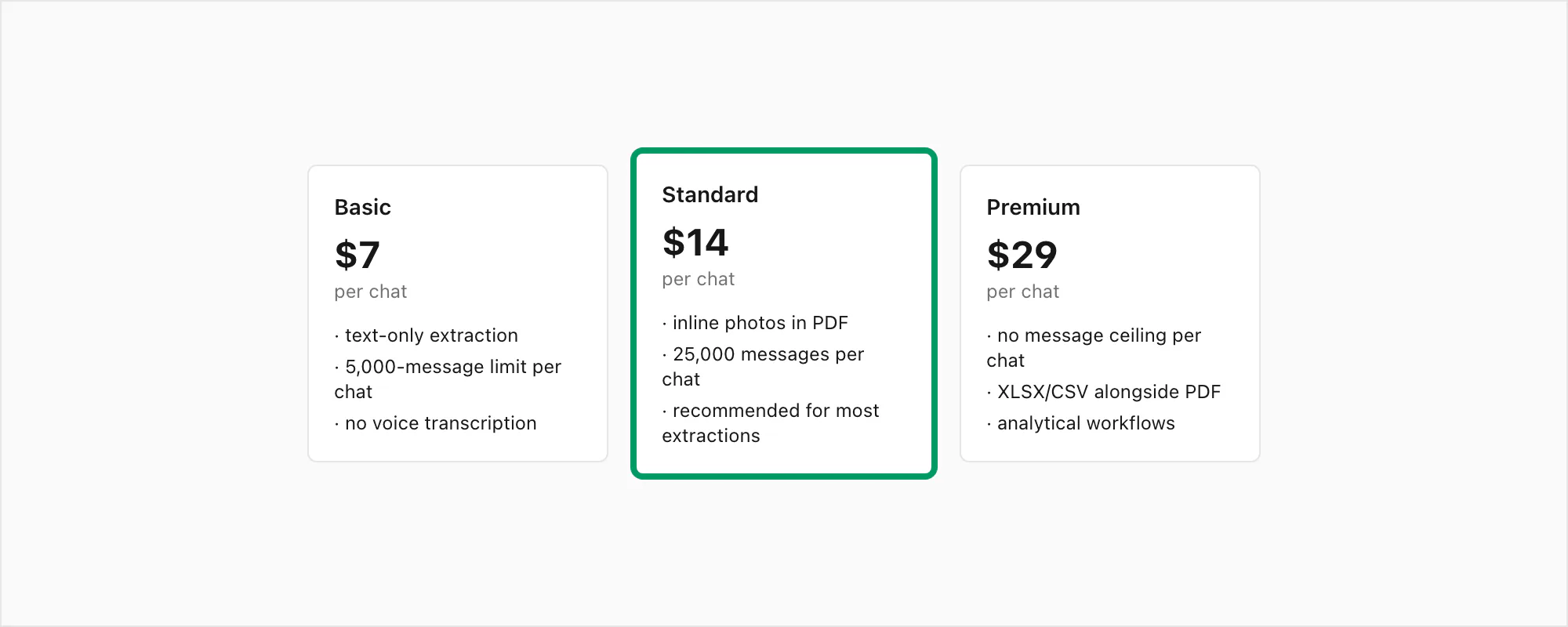
$7 Basic per chat is the entry tier. Text-only extraction, capped at 5,000 messages per chat, no embedded photos in the PDF, no voice transcription. Right when the chat is short and the message text is the only field that matters — for example, a research project that only needs the text-and-timestamp record.
$14 Standard per chat is the recommended tier for most extract-to-PDF jobs and the one I push hardest in support. The extraction includes inline photos in the PDF (assuming you exported with Including Media), the per-chat message ceiling lifts to 25,000, and voice notes appear as placeholders rather than transcribed text. This is the tier that fits most legal-evidence and personal-archival cases — the chat fits, photos appear inline, sender attribution is preserved, and the PDF reads cleanly.
$29 Premium per chat removes the per-chat message ceiling and adds an XLSX/CSV output alongside the PDF — the structured-data artefact for users who need to filter, search, or analyse rows after the extraction. Voice notes still appear as placeholders. Right when the chat is genuinely long, when the use case is HR investigation or research, or when you want both the readable PDF and the analytical spreadsheet from one conversion.
$49 Premium+Voice per chat adds Deepgram Nova-3 voice-note transcription — every voice note becomes a real text block in the PDF and the spreadsheet, with sender attribution and timestamp. Right when the chat carries meaningful audio that has to be in the artefact.
$99 Power User per chat adds priority queue processing, no per-chat message ceiling, and bulk-conversion support across multiple chats in a single session — useful when you have a folder of exports from different chats to extract.
Re-export and re-convert the same chat tomorrow and you pay again, because each conversion is real work against a different snapshot. There is no signup, no account, and no commitment beyond the single chat you upload.

Key takeaways
- "Extract WhatsApp" and "export WhatsApp" use the same underlying mechanism — the Export Chat menu — but the extract framing implies analytical work on the result, not just snapshot archival.
- The four primary fields you extract from a WhatsApp ZIP are timestamp, sender name, message text, and attachment reference — every line in
_chat.txtcarries those. - Derived fields available on careful extraction include voice-note duration, message-type signals (deleted, edited, forwarded), system events (joins, leaves), and chat metadata (title, participant list).
- The five recurring use cases for extraction are legal evidence, HR investigation, research, personal archival, and migration to other tools — each points to a different downstream artefact.
- Tooling options range from manual
_chat.txtreading (free, painful) through custom parser scripts (full control, requires code) to chattopdf.app (sender-attributed PDF in ~30 seconds, $14 Standard per chat). - The $14 Standard per chat tier is the right choice for most extract-to-PDF work; Premium ($29 per chat) adds XLSX/CSV alongside the PDF for analytical workflows.
- For the full conversion process — how chattopdf parses the extracted fields and renders them as a formatted document — see the WhatsApp to PDF guide.
FAQ
Is there a way to extract WhatsApp chat data without using the Export Chat menu?
Not for typical users. The Export Chat menu is the only sanctioned mechanism WhatsApp provides for getting message data out of the app. Tools that read the WhatsApp database directly — Android Backup Extractor, iMazing on iPhone, similar forensic utilities — exist for advanced users with local backups or device-level access, and they can reach beyond the 40,000-message export cap. For everyone else, Export Chat is the path, and the resulting ZIP is the source for any extraction work.
What fields can I extract from a WhatsApp chat export?
Every line in _chat.txt carries four primary fields: a timestamp (in square brackets at line start), a sender name (between the timestamp and the colon), the message text (after the colon), and an attachment reference if media was sent (filename in angle brackets, or <Media omitted> for Without Media exports). Derived fields include voice-note duration (read from .opus headers), message-type signals (deleted, edited, forwarded), system events (group joins, leaves, admin changes), and chat metadata (title and participant list reconstructed from the first system lines).
How do I extract WhatsApp chat data into a spreadsheet for analysis?
The fastest path is the chattopdf $29 Premium per chat tier — it runs the extraction once and produces both a sender-attributed PDF and an XLSX/CSV file with structured columns (timestamp, sender, text, attachment reference) you can filter, sort, or analyse. The DIY alternative is a custom parser script — _chat.txt is well-formed text, and a hundred lines of Python or JavaScript will produce the same row-and-column output if you prefer total control over the extraction logic. For one-off or occasional extractions, the chattopdf path saves the parser-writing effort.
Can I extract messages older than the 40,000-message export limit?
Not via the Export Chat menu — WhatsApp caps every export at the most-recent 40,000 messages, with no warning when the limit is hit. To reach older messages, you need a local-backup forensic tool: on Android, Android Backup Extractor reading a msgstore.db file from a phone backup; on iPhone, iMazing or similar reading the local iCloud backup. Both require device-level access or an existing backup, and both sit outside the official WhatsApp toolchain. For most users, the 40,000-message cap is a hard limit on what you can extract.
How long does it take to extract a WhatsApp chat to a usable artefact?
About 30 seconds end to end on a typical chat through chattopdf. Roughly: 5-15 seconds to run Export Chat on the phone, 3 seconds to upload the ZIP to chattopdf.app, 10 seconds for checkout, 15 seconds for the parser to extract every field and render the PDF (and the XLSX/CSV on Premium tier), 2 seconds to download. Very long chats with thousands of embedded photos take longer — a multi-year group chat can run up to 2 minutes for the rendering step. The DIY parser path is faster per conversion once written, but the upfront work to write and test the parser is hours.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).