ما يعنيه "transcribe WhatsApp audio" فعلًا (ولماذا هو أصعب مما يبدو)
يستخدم الناس عبارة "transcribe WhatsApp audio" للإشارة إلى ثلاثة أشياء مختلفة على الأقل. بعضهم يريد تفريغ المكالمات الصوتية المباشرة — التي لا تتيحها WhatsApp عبر أي API للمطورين وهي تقنيًا فئة منتج مستقلة عما أصفه هنا. وبعضهم يريد تحويل ملفات صوتية حفظها من WhatsApp إلى نص معاملًا ملف .opus كمدخل مستقل. وبعضهم — وهم الأغلبية — يريد تحويل كل رسالة صوتية داخل محادثة WhatsApp مُصدَّرة إلى نص مقروء ليُشكّل المحادثة كاملةً وثيقةً مفهومة.
ChatToPDF مبني لحالة الاستخدام الثالثة (وهي التي أحلّها أنا — I built it for this exact gap). المشكلة التي يحلّها محددة: تُصدّر محادثة WhatsApp تحتوي رسائل نصية ورسائل صوتية، وما تحصل عليه من WhatsApp ZIP يحتوي _chat.txt ومجلد ملفات الوسائط. يتضمن _chat.txt أسطرًا مثل <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> في موضع الرسالة الصوتية. لا شيء يحوّل هذه إلى نص مقروء ما لم تبنِ شيئًا لذلك.
هذا ما لا يخبرك به أحد (here's the part nobody tells you): حتى حين يجد الناس أداة تفريغ يصطدمون بمشكلة هيكلية. الأدوات التي تتعامل مع ملفات صوتية عامة — ارفع MP3 واحصل على نص — لا تعرف موضع ذلك الصوت في المحادثة. تُفرّغ الملف لكنها تفقد السياق. تنتهي بكتلة نص منفصلة بلا اسم مُرسِل ولا طابع زمني ولا إشارة إلى ما قيل قبلها أو بعدها. في قضية قانونية أو سجل أعمال أو أرشيف عائلي، هذا السياق هو جوهر الأمر.
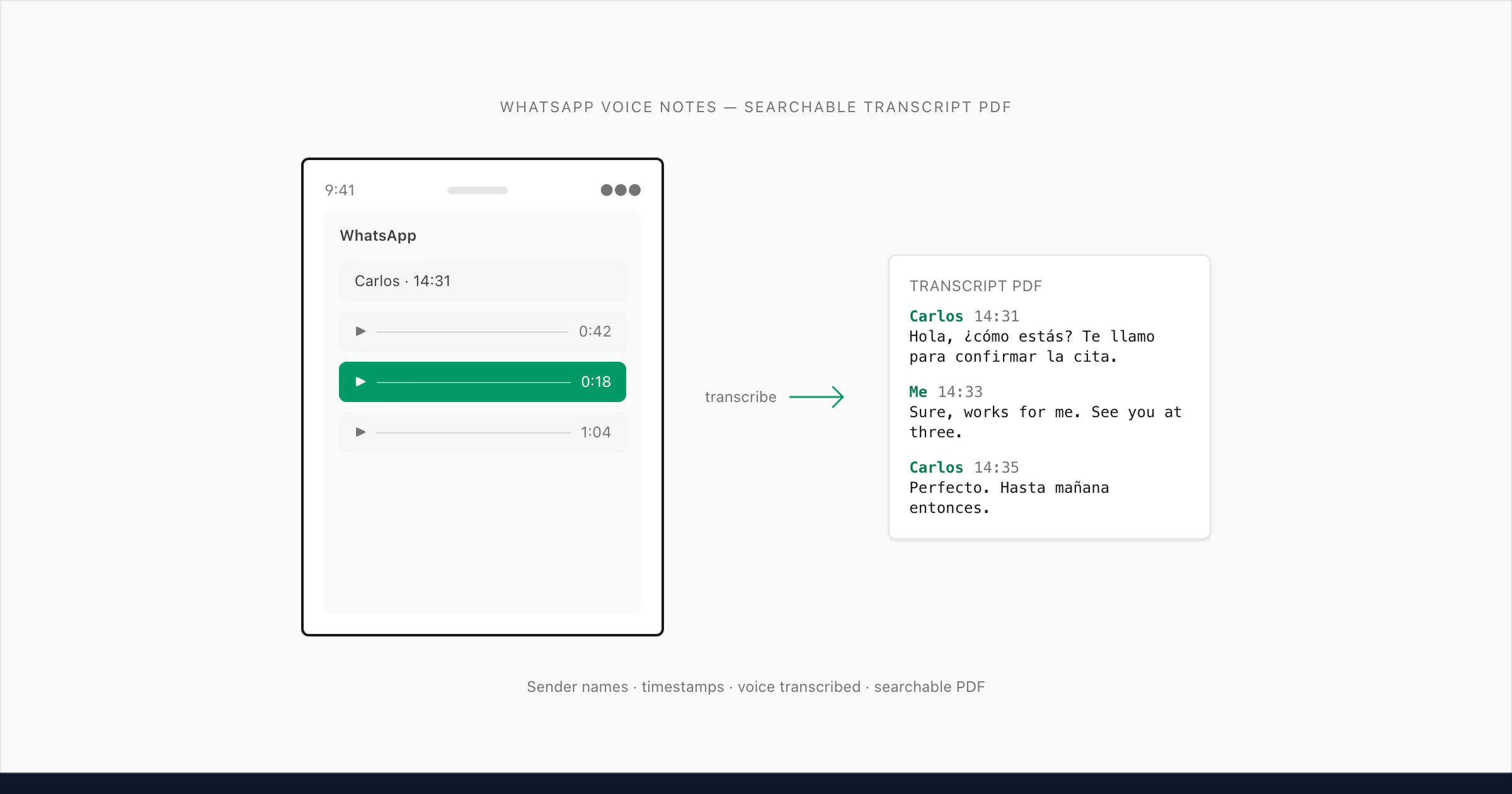
ما بنيتُه يفعل التالي: يقرأ _chat.txt ليفهم بنية المحادثة، يُطابق كل مرجع .opus مع الملف الصوتي الصحيح في ZIP، يُفرّغ الصوت، ويُدرج التفريغ في موضعه الدقيق في المحادثة — مع حفظ اسم المُرسِل والطابع الزمني الأصلي. النتيجة وثيقة PDF واحدة تتناوب فيها الرسائل النصية وتفريغات الرسائل الصوتية بشكل طبيعي، تمامًا كما جرت المحادثة.
تلك هي المشكلة التي يتناولها هذا الدليل.
الرسائل الصوتية ليست ملفات — إنها بث داخل التطبيق
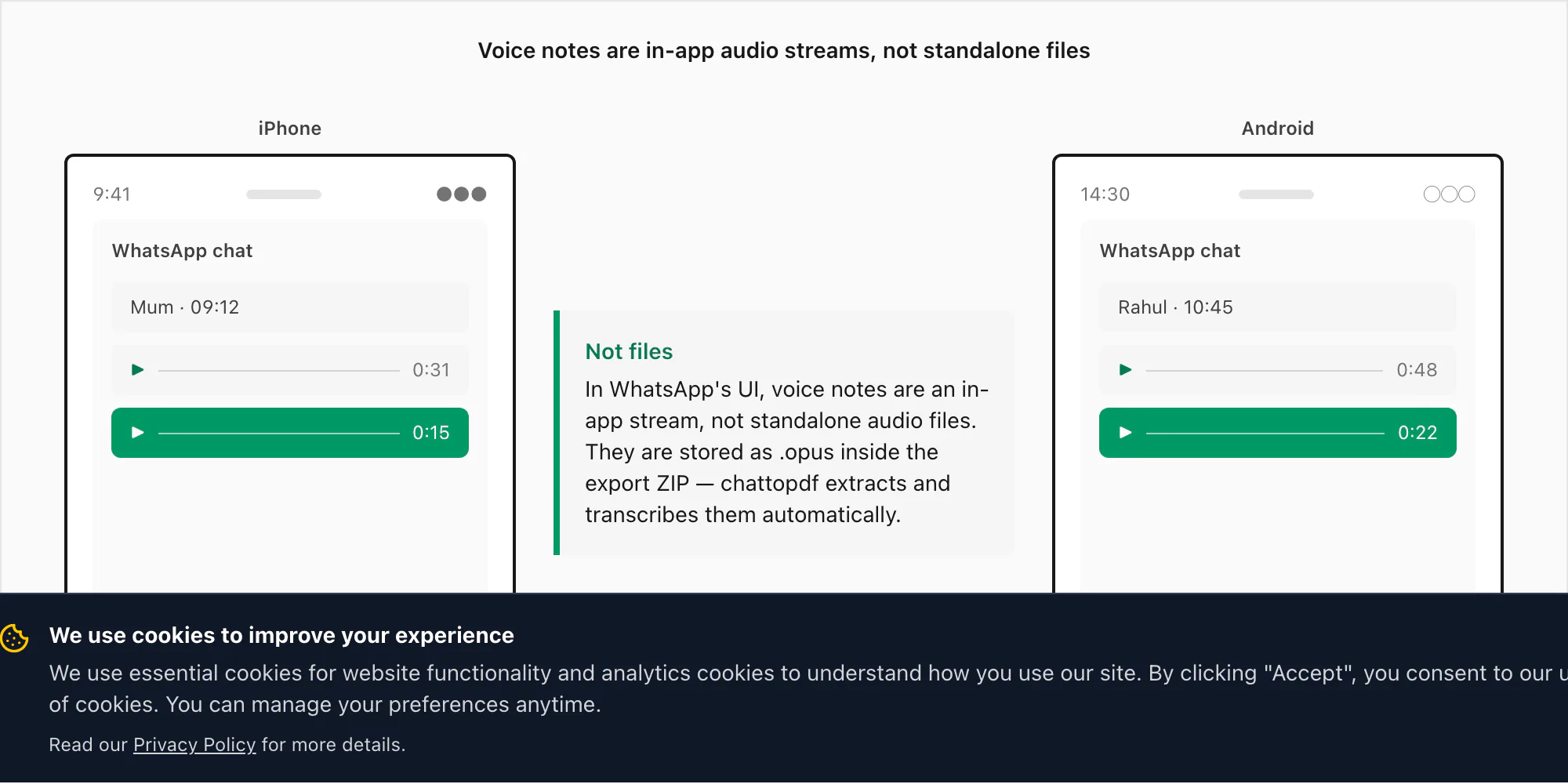
الرسائل الصوتية في WhatsApp تبدو كملفات صوتية داخل التطبيق — شريط موجي ومدة وزر تشغيل — لكنها لا تُخزَّن كما يتوقع معظم الناس. حين تسجّل رسالة صوتية في WhatsApp بالضغط على زر الميكروفون، يُشفّر WhatsApp الصوت باستخدام ترميز Opus ويحفظه كملف .opus في دليل خاص على جهازك. لا يمكن الوصول إلى هذا الدليل عبر التصفح العادي للملفات على iPhone أو Android. لا يمكنك التنقل إليه في تطبيق الملفات وتجد رسائلك الصوتية هناك.
الطريقة الوحيدة لاستخراج ملفات .opus هذه هي من خلال قائمة "تصدير الدردشة" في WhatsApp مع اختيار "تضمين الوسائط". عند التصدير بهذه الطريقة يُجمّع WhatsApp سجل رسائل _chat.txt جنبًا إلى جنب مع مجلد الوسائط — وهنا تظهر ملفات .opus. على iOS تنتهي داخل ZIP. على Android، كانت الإصدارات القديمة تُصدّر إلى مجلد في التخزين الداخلي؛ الإصدارات الأحدث تُنشئ ZIP عبر واجهة المشاركة مطابقةً سلوك iOS.
ترميز Opus يستحق فهمًا مختصرًا لأنه يُفسّر سبب تفاوت الدقة. صُمّم Opus للصوت عبر IP — زمن استجابة منخفض وضغط جيد وجودة مقبولة حتى بمعدلات بت منخفضة. يستخدم WhatsApp صوتًا أحادي القناة بـ 16 كيلوهرتز بنحو 16 كيلوبت في الثانية. الملفات الناتجة صغيرة: رسالة صوتية مدتها 60 ثانية تزن عادةً بين 80 و120 كيلوبايت. هذا فعّال لبيانات الهاتف المحمول، لكن صوت أحادي بـ 16 كيلوهرتز وـ16 كيلوبت في الثانية ليس صوتًا بجودة استوديو. إنه مُحسَّن للوضوح عبر اتصال هاتفي لا لدقة التفريغ. الضجيج الخلفي وصوت مُسجَّل أثناء القيادة أو شخص يتحدث من الجهة الأخرى من الغرفة يمكن أن يخفض الجودة الفعلية أكثر.
لهذا السبب يهم نموذج التفريغ. محرك تحويل الكلام إلى نص العام المُدرَّب على تسجيلات استوديو أو بودكاست سيواجه صعوبة مع صوت أحادي بـ 16 كيلوهرتز مضغوط بـ 16 كيلوبت في الثانية. المحرك الذي اخترته اختير تحديدًا لأنه يتعامل بشكل جيد مع هذا النوع من الصوت. المزيد حول ذلك في القسم التالي.
نقطة هيكلية أخرى: كل رسالة صوتية في WhatsApp تسجيل لمُرسِل واحد. نموذج الضغط على الزر للتحدث في WhatsApp يعني أن شخصًا واحدًا يسجّل ثم يتوقف ثم يسجّل الآخر ردّه. هذه ميزة للتفريغ — خلافًا لمكالمة هاتفية مسجّلة حيث يتداخل صوتان في نفس المسار الصوتي، كل ملف .opus في تصدير WhatsApp ينتمي لمُرسِل واحد بالضبط. يستخدم ChatToPDF البيانات الوصفية من _chat.txt لنسب كل تفريغ للشخص الصحيح، وهذا كيف تحصل على محادثة مقروءة بوضوح حتى حين يتناوب الطرفان في الرسائل الصوتية.
محرك التفريغ الذي اخترته ولماذا
قيّمتُ عدة APIs للتفريغ قبل الاستقرار على Deepgram كمحرك خلف تفريغ الصوت في ChatToPDF. المنافسون الجديون الآخرون كانوا AssemblyAI و Whisper (نموذج OpenAI مفتوح المصدر) وعدد من واجهات API للكلام العامة من موفري السحابة. إليك المنطق الصادق وراء اختياري.
Whisper مثير للإعجاب كنموذج مجاني، لكنني أجريت اختبارات دقة على مجموعة من ملفات WhatsApp .opus الحقيقية عبر الإنجليزية والإسبانية والهندية والعربية، وأبدى نقاط ضعف متسقة في التبديل بين الكودات (رسالة صوتية تمزج لغتين في منتصف الجملة) وفي لهجات الإنجليزية غير الأمريكية. كما أنه لا يقدم اتفاقيات مستوى خدمة تجارية أو ضمانات وقت تشغيل، وهو أمر مهم حين يتظر مستخدمون دافعون لمخرجاتهم.
AssemblyAI جيد حقًا واستخدمته في نموذج أولي مبكر. الدقة على الإنجليزية كانت قابلة للمقارنة بـ Deepgram، لكن اتساع دعم اللغات واتساق استجابة API على الصوت الأحادي بصيغة Opus وـ16 كيلوهرتز جعل Deepgram أنسب لحالة الاستخدام متعددة اللغات التي كنت أبني نحوها.
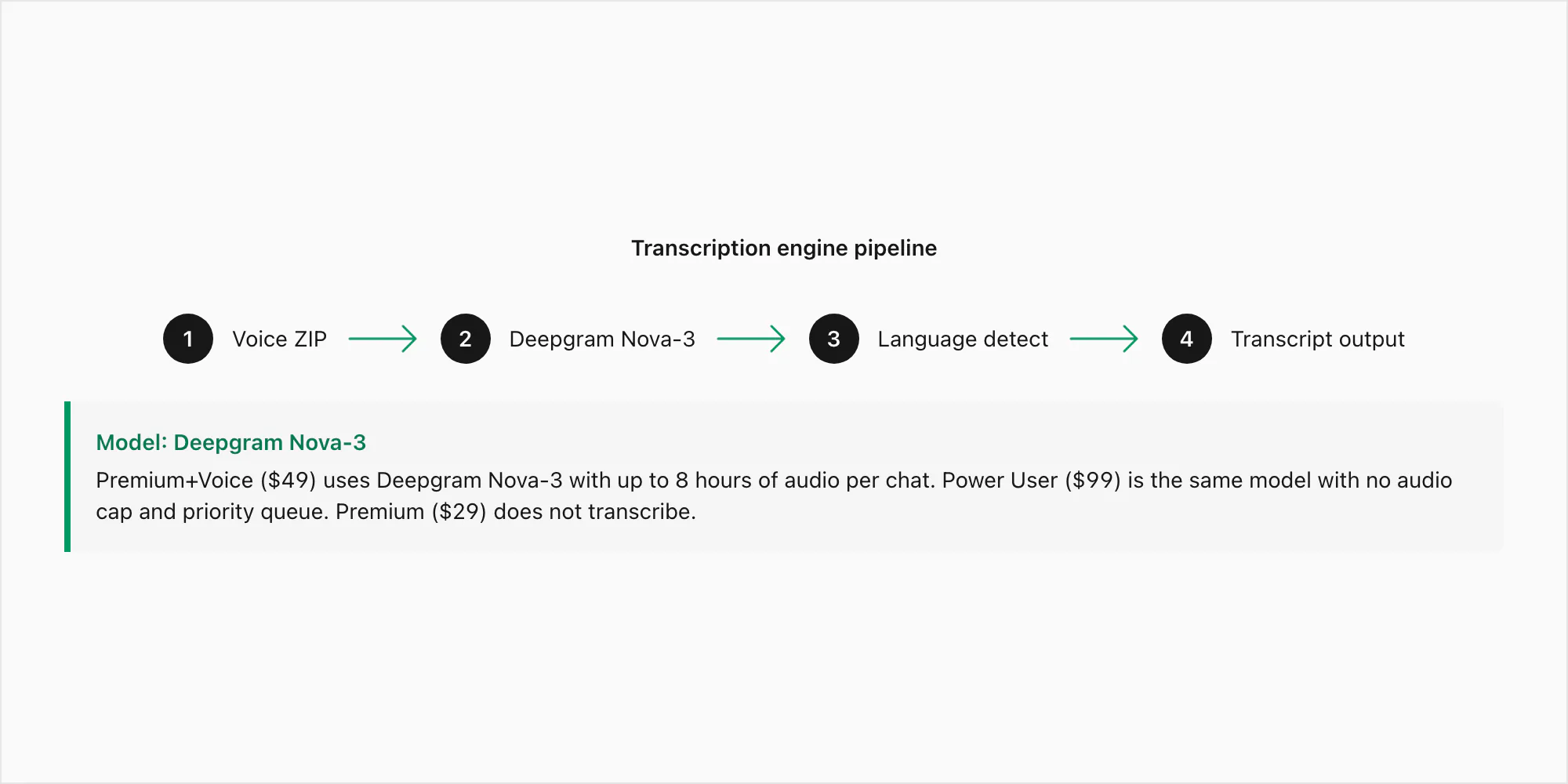
Deepgram Nova-3 هو النموذج من الجيل الحالي بمعدل خطأ الكلمة حوالي 3–5% على الصوت النظيف الخالي من الضجيج بالإنجليزية و8–15% على التسجيلات الأكثر صخبًا. هذه الأرقام تتماسك على الصوت الأحادي بـ Opus و16 كيلوهرتز، وهو الصيغة المهمة لتصديرات WhatsApp. Nova-3 هو النموذج المستخدم في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة وتحويل Power User بـ 99 دولارًا لكل دردشة — الفرق بين هذين المستويين هو حد الصوت (8 ساعات مقابل غير محدود) وأولوية القائمة، وليس النموذج.
حيث يتفوق Nova-3 بشكل واضح على محركات تحويل الكلام إلى نص الأقدم هو في ثلاثة مجالات: اللهجات الإقليمية (إنجليزية جنوب أفريقيا وإنجليزية الهند والبرتغالية البرازيلية)، والمفردات التقنية (الأسماء والعناوين ومصطلحات المنتجات التي نموذج عام قد يُخطئ سماعها)، والصوت المُبدَّل بين الكودات حيث يتنقل المُتحدث بين لغتين داخل رسالة صوتية واحدة. تلك هي أنماط الفشل المحددة التي دفعت إلى اختيار المحرك. تحويل Premium بـ 29 دولارًا لكل دردشة لا يشمل التفريغ أصلًا — يحفظ الرسائل الصوتية كمراجع عنصر نائب في PDF دون تشغيل الصوت في أي نموذج.
يعمل المسار هكذا: يصل ZIP إلى خادم ChatToPDF، تُستخرج ملفات .opus، يُرسَل كل منها إلى API Deepgram عبر استدعاء HTTPS مُوثَّق مع ضبط اكتشاف اللغة على التلقائي، ويعود التفريغ — عادةً خلال ثانيتين إلى خمس ثوانٍ لكل دقيقة صوت. تُحاك التفريغات بعد ذلك في المحادثة في المواضع الصحيحة قبل تصيير PDF.
خيار متعمد في المسار: لا أُعيد معالجة صوت .opus أو إعادة ترميزه قبل إرساله إلى Deepgram. بعض الأدوات تُحوّل Opus إلى WAV أو MP3 أولًا مستدلةً بأن صيغة مختلفة قد تحسّن الدقة. من الناحية العملية، API Deepgram يتعامل مع Opus بشكل أصلي والتحويل يزيد الكمون دون تحسين النتائج على هذا النوع من الصوت. ملف .opus الخام يذهب مباشرةً إلى نقطة نهاية الاستنتاج.
الدقة في الـ 17 لغة التي يدعمها ChatToPDF اليوم
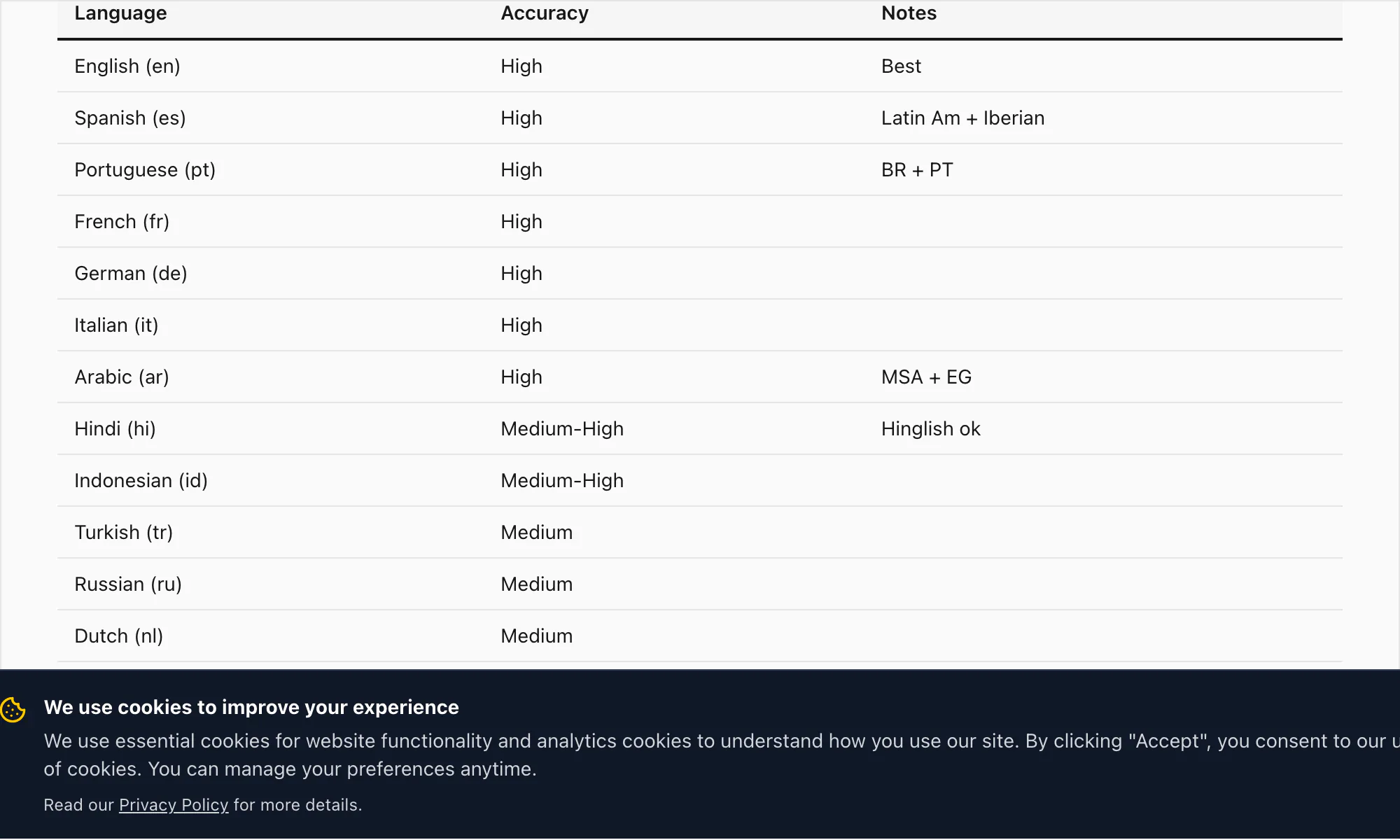
مستوى اللغات عالية الدقة في ChatToPDF يغطي 17 لغة. هذه اللغات التي أثق بجودة تفريغها بما يكفي لأسميها جاهزة للإنتاج في الوثائق والسجلات القانونية واستخدام الأعمال:
الإنجليزية (en) — معدل خطأ الكلمة 3–5% على الصوت النظيف. تشمل اللهجات البريطانية والأمريكية والأسترالية والجنوب أفريقية والهندية. جميع متغيرات الإنجليزية تُعالَج بنفس نموذج Nova-3 في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة.
الإسبانية (es) — معدل خطأ الكلمة 4–6% في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة. يتعامل مع لهجات أمريكا اللاتينية والقشتالية. ارتباك المترادفات الشائعة (haya/halla، tubo/tuvo) تخفّفه جزئيًا الاستنتاجات السياقية.
البرتغالية (pt) — معدل خطأ الكلمة 4–7%. تغطي البرتغالية البرازيلية والأوروبية. التبديل بين البرتغالية والإنجليزية نمط شائع في محادثات WhatsApp البرازيلية؛ Nova-3 يتعامل معه بشكل جيد.
الفرنسية (fr) — معدل خطأ الكلمة 4–6%. الفرنسية القياسية والكندية.
الألمانية (de) — معدل خطأ الكلمة 4–6%. الأسماء المركبة تُفرَّغ بدقة على Nova-3 بما فيها الصيغ المركبة الطويلة المعتادة في المفردات القانونية والتجارية.
الإيطالية (it) — معدل خطأ الكلمة 5–7%.
العربية (ar) — معدل خطأ الكلمة 7–10%. العربية الفصحى تُفرَّغ بشكل جيد؛ العربية العامية (المصرية والخليجية والشامية) ذات تباين أوسع. تحويل Premium+Voice بـ 49 دولارًا لكل دردشة هو المستوى الموصى به للرسائل الصوتية العربية.
الهندية (hi) — معدل خطأ الكلمة 6–9% للهندية النقية. الهنجلش المُبدَّلة بين الكودات (الهندية مع إدراجات إنجليزية) هي حيث يُحدث Nova-3 أكبر فرق عن محركات التفريغ الأقدم — مزيد من التفاصيل في قسم نموذج التفريغ أدناه.
الإندونيسية (id) — معدل خطأ الكلمة 5–8%. إحدى أكثر اللغات شيوعًا في قاعدة مستخدمي ChatToPDF نظرًا للانتشار الكبير لـ WhatsApp في جنوب شرق آسيا.
التركية (tr) — معدل خطأ الكلمة 5–8%.
الروسية (ru) — معدل خطأ الكلمة 5–8%.
الهولندية (nl) — معدل خطأ الكلمة 4–6%.
اليابانية (ja) — معدل خطأ الكلمة 7–10%. الكلمات الدخيلة بالكاتاكانا والأسماء الخاصة قد تُسبّب أخطاء؛ الدقة الإجمالية قوية للكلام التحادثي.
الكورية (ko) — معدل خطأ الكلمة 6–9%.
الصينية (zh) — معدل خطأ الكلمة 7–10%. الماندرين. اللهجات الإقليمية والمترادفات التونية قد تؤثر في الدقة على التسجيلات الصعبة.
الفيتنامية (vi) — معدل خطأ الكلمة 7–10%.
التايلاندية (th) — معدل خطأ الكلمة 8–12%. علامات النبر ومجموعات الحروف الساكنة في الكلام السريع هي التحدي الرئيسي.
وراء هذه اللغات الـ 17، يدعم Deepgram Nova-3 أكثر من 30 لغة إضافية بنطاق دقة أوسع. إذا لم تكن لغتك في قائمة الدقة العالية أعلاه، يُنتج تحويل Premium+Voice بـ 49 دولارًا لكل دردشة تفريغًا بأفضل جهد ممكن باستخدام اكتشاف اللغة الأشمل لـ Nova-3 — توقع دقة تقترب من 15–20% معدل خطأ الكلمة على الصوت الصعب في اللغات ذات الدرجة الأدنى.
اكتشاف اللغة التلقائي مُفعَّل افتراضيًا. يُرسل ChatToPDF كل ملف .opus إلى Deepgram دون تحديد لغة، ويكتشف Deepgram اللغة المهيمنة في الثواني الأولى. هذا دقيق للتسجيلات أحادية اللغة. للتبديل المكثّف — رسالة صوتية بالتساوي 50/50 بين لغتين — يختار الكاشف إحداهما رئيسية ويطبّق ذلك النموذج على المقطع كاملًا. ستشاهد بعض فقدان الدقة في اللغة الثانوية في تلك الحالات.
نموذج تفريغ: رسالة صوتية إسبانية ← نص (مثال حقيقي)
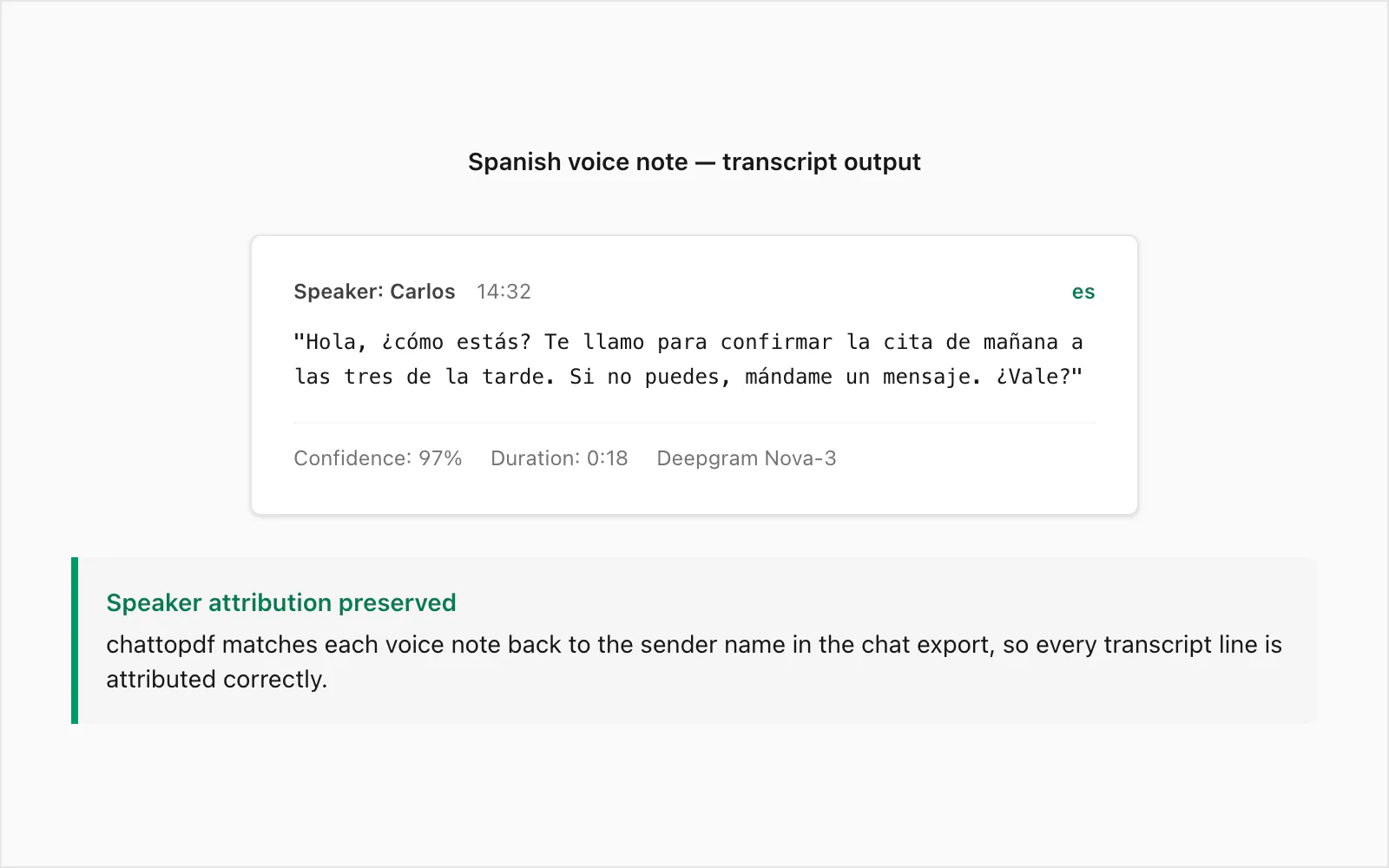
هذه رسالة صوتية حقيقية من WhatsApp مُفرَّغة في مستوى تحويل Premium+Voice بـ 49 دولارًا لكل دردشة. المُرسِل ناطق أصلي بالإسبانية الكولومبية، مسجّلة على جهاز Android في بيئة داخلية هادئة. المدة: 18 ثانية. حجم الملف: ~28 كيلوبايت بصيغة .opus.
الصوت الأصلي (مُختصَر): رسالة صوتية غير رسمية تُؤكّد موعدًا في اليوم التالي وتُعرب عن القلق على صحة الطرف الآخر وتطلب ردًا نصيًا إذا تغيّرت الخطط.
مخرج التفريغ في PDF:
🎤 [رسالة صوتية — 0:18] "Hola, ¿cómo estás? Te llamo para confirmar la cita de mañana a las tres de la tarde. Si no puedes, mándame un mensaje. ¿Vale?"
يُنسب المُرسِل في PDF باسمه من _chat.txt، الطابع الزمني هو الذي سجّلته WhatsApp حين أُرسلت الرسالة الصوتية، والتفريغ يقع مضمّنًا بين الرسائل النصية قبله وبعده مباشرةً في المحادثة.
بعض ما يلفت الانتباه في هذا المثال. علامة الأسلوب الرسمي ¿Vale? — الأقرب في المعنى إلى "حسنًا؟" — فُرّغت بشكل صحيح دون الخلط بـ bale أو حذفها. عبارة الوقت a las tres de la tarde ("في الثالثة بعد الظهر") صيغت بدقة، وهو ما يهم في تأكيد موعد حيث الخطأ يكون مُضلِّلًا. التصاعد المنطوق في نبرة ¿cómo estás? لم يكن غامضًا بما يكفي لإنتاج خطأ في التفريغ.
أين تتراجع دقة الإسبانية؟ الأخطاء الأكثر شيوعًا التي أراها هي المترادفات: haya (منصوب haber) مقابل halla (من hallar، يجد)، tubo (أنبوب) مقابل tuvo (ماضي tener). في الكلام غير الرسمي السريع هذه متطابقة صوتيًا. يستخدم Nova-3 السياق المحيط للاستنتاج بالتهجئة الصحيحة في معظم الأحيان، لكنه غير مثالي. في وثيقة ستُستخدم كسجل قانوني، أوصي بمراجعة بشرية خفيفة لأي رسائل صوتية سيُستشهد بتفريغها حرفيًا.
إذا لم تكن تحتاج التفريغ أصلًا — مثلًا تريد فقط تحويل الرسائل النصية إلى PDF وأنت مرتاح بمراجع العنصر النائب للرسائل الصوتية — يتعامل تحويل Premium بـ 29 دولارًا لكل دردشة مع تلك الحالة بسعر أقل. تحويل Premium+Voice بـ 49 دولارًا لكل دردشة هو الخطوة الصحيحة حين تحتاج ظهور الإسبانية المنطوقة فعلًا كنص مقروء في الوثيقة.
نموذج تفريغ: هندية (هنجلش مختلطة) ← نص (مثال حقيقي)
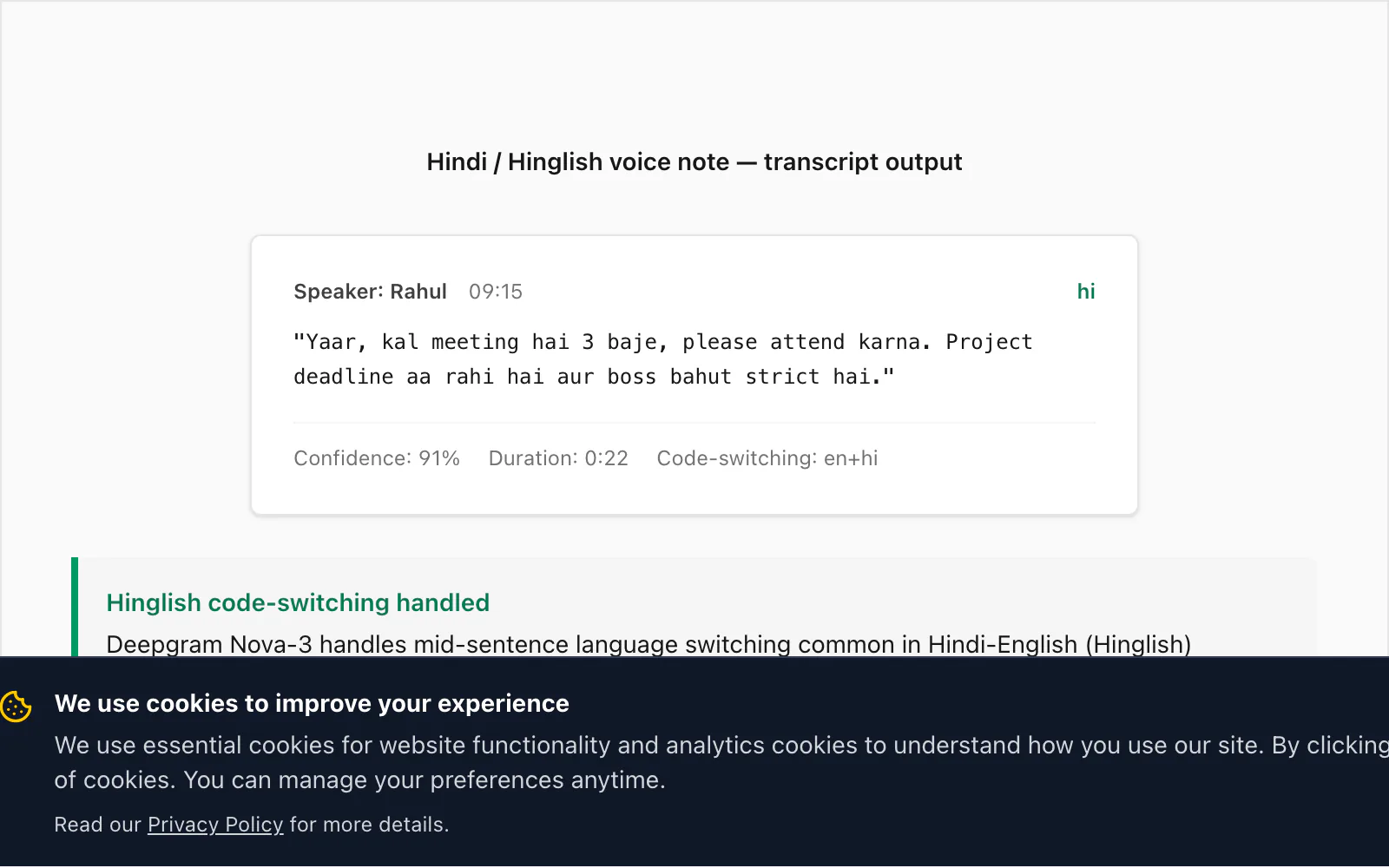
هنا يتميز Nova-3 عن الأجيال السابقة من محركات تحويل الكلام إلى نص. الهنجلش — الهندية مع كلمات وجمل وأحيانًا جمل كاملة بالإنجليزية — أحد أكثر أنماط التبديل بين الكودات شيوعًا في العالم الحقيقي التي أراها في قاعدة مستخدمي ChatToPDF. المحركات القديمة (بما فيها النموذج الذي شحنته Deepgram ذاتها قبل جيلين) تُفوّت نحو 15% من الإدراجات الإنجليزية المُبدَّلة بين الكودات في رسالة صوتية هنجلش نموذجية. Nova-3 يُغلق معظم هذه الفجوة.
إليك تفريغًا حقيقيًا من تحويل Premium+Voice بـ 49 دولارًا لكل دردشة:
🎤 [رسالة صوتية — 0:22] "Yaar, kal meeting hai 3 baje, please attend karna. Project deadline aa rahi hai aur boss bahut strict hai."
الترجمة: "يا صاح، غدًا اجتماع الساعة 3، رجاءً احضر. الموعد النهائي للمشروع يقترب والمدير صارم جدًا."
التبديل بين الكودات هنا مميَّز: meeting و attend و project deadline و strict إدراجات إنجليزية داخل جملة هندية سوى ذلك. فرّغ Nova-3 جميعها بشكل صحيح. نموذج Deepgram الأقدم الذي اختبرته على الملف ذاته أنتج miiting لـ meeting (تحويل صوتي هندي)، وحذف attend كليًا، وأنتج project ka deadline بتحويل حالات غير متسق. هذا الفرق هو ما دفع إلى ترقية النموذج في المسار.
الفرق مهم حين تستخدم التفريغ كسجل في مكان العمل. إذا كان مدير شخص ما يراجع تفريغ رسالة صوتية كتوثيق لالتزام بمشروع وكلمة deadline لا تظهر في النص، فهذه ليست اعتراض دقة بسيط — إنها معلومة مفقودة.
نسب المُرسِل يعمل كما مع الإسبانية: الاسم من _chat.txt يظهر في PDF مع تفريغ Deepgram، والطابع الزمني من بيانات WhatsApp الوصفية يربطه بالموضع الصحيح في المحادثة.
ملاحظة عن الهندية تحديدًا: إذا كانت الرسالة الصوتية بالهندية المهيمنة بالديوناغري (الهندية الرسمية بأسلوب الكلام المكتوب مع إدراجات إنجليزية ضئيلة)، تكون الدقة قوية باستمرار عبر المستويات المدعومة. تحويل Premium+Voice بـ 49 دولارًا لكل دردشة هو نقطة الدخول الصحيحة لأي رسائل صوتية هندية تريد تفريغها؛ تحويل Power User بـ 99 دولارًا لكل دردشة يغطي نفس الدقة بلا حد للصوت وأولوية القائمة. تحويل Premium بـ 29 دولارًا لكل دردشة يحفظ الرسائل الصوتية كعناصر نائبة فقط — لا تفريغ يعمل في ذلك المستوى.
مستوى Premium+Voice بـ 49 دولارًا — ما يشمله وما لا يشمله

تحويل Premium+Voice بـ 49 دولارًا لكل دردشة هو المستوى الذي بنيتُه تحديدًا للمحادثات الثقيلة بالرسائل الصوتية. إليك بالضبط ما يشمله وما لا يشمله.
ما يشمله تحويل Premium+Voice بـ 49 دولارًا لكل دردشة:
- تفريغ Deepgram Nova-3 — النموذج من الجيل الحالي بمعدل خطأ الكلمة 3–5% على الصوت النظيف ومعالجة قوية للهجات ودعم موثوق للتبديل بين الكودات
- جميع اللغات الـ 17 عالية الدقة — الإنجليزية والإسبانية والبرتغالية والفرنسية والألمانية والإيطالية والعربية والهندية والإندونيسية والتركية والروسية والهولندية واليابانية والكورية والصينية والفيتنامية والتايلاندية — بالإضافة إلى أكثر من 30 لغة عبر اكتشاف اللغة التلقائي لـ Nova-3
- ما يصل إلى 8 ساعات صوتية في دردشة واحدة — يغطي الغالبية العظمى من المحادثات الثقيلة بالصوت؛ إذا تجاوزت دردشتك 8 ساعات إجمالية من الصوت المسجَّل يرفع تحويل Power User بـ 99 دولارًا لكل دردشة هذا الحد
- لا حد للرسائل — لا سقف لعدد الرسائل في الدردشة التي تحوّلها
- نسب المُرسِل في التفريغات — كل تفريغ في PDF يحمل اسم مُرسِل WhatsApp من بيانات التصدير الوصفية
- الطوابع الزمنية محفوظة — الطابع الزمني الأصلي لـ WhatsApp يظهر جنبًا إلى جنب مع كل تفريغ لا وقت التفريغ
- ثلاثة صيغ مخرجات — PDF و XLSX و CSV جميعها مشمولة؛ XLSX مفيد إذا أردت التصفية أو الترتيب حسب المُرسِل والطابع الزمني
- احتفاظ بالملف المصدر لسبعة أيام — مُشفَّر في وضع الراحة (AES-256) وأثناء النقل (TLS 1.3)
ما لا يشمله تحويل Premium+Voice بـ 49 دولارًا لكل دردشة:
- التفريغ الفوري — هذا المستوى يعالج الرسائل الصوتية المُسجَّلة مسبقًا من ZIP تصدير؛ إنه ليس خدمة تفريغ مباشر (أشرح السبب في القسم التالي)
- قوائم المفردات المخصصة — لا يمكنك رفع قاموس من الأسماء أو المصطلحات التقنية لتحسين الدقة على مفردات محددة؛ نموذج Deepgram للأغراض العامة يتعامل مع معظم الأسماء بشكل صحيح لكنه يُخطئ أحيانًا في الأسماء الخاصة النادرة
- تعرّف المُتحدث بما يتجاوز بيانات WhatsApp الوصفية — داخل رسالة صوتية واحدة يُسجّل فيها المُرسِل بينما يتحدث شخص آخر في الخلفية، يُفرَّغ الاثنان لكن يُنسبان فقط لمُرسِل WhatsApp. ChatToPDF لا يُجري تمييز المُتحدثين على الصوت نفسه.
- الترجمة التلقائية — يظهر التفريغ باللغة المصدر للرسالة الصوتية. إذا كانت رسالة صوتية بالإسبانية، التفريغ بالإسبانية. ChatToPDF لا يُترجم التفريغات.
المستوى الأعلى — تحويل Power User بـ 99 دولارًا لكل دردشة — يشمل كل ما في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة بالإضافة إلى معالجة ذات أولوية في القائمة والتعامل مع الدردشات المتعددة. إذا كنت تحوّل دردشة واحدة والسرعة ليست حرجة (تكتمل معظم التحويلات في أقل من ثلاث دقائق)، تحويل Premium+Voice بـ 49 دولارًا لكل دردشة هو المستوى الصحيح.
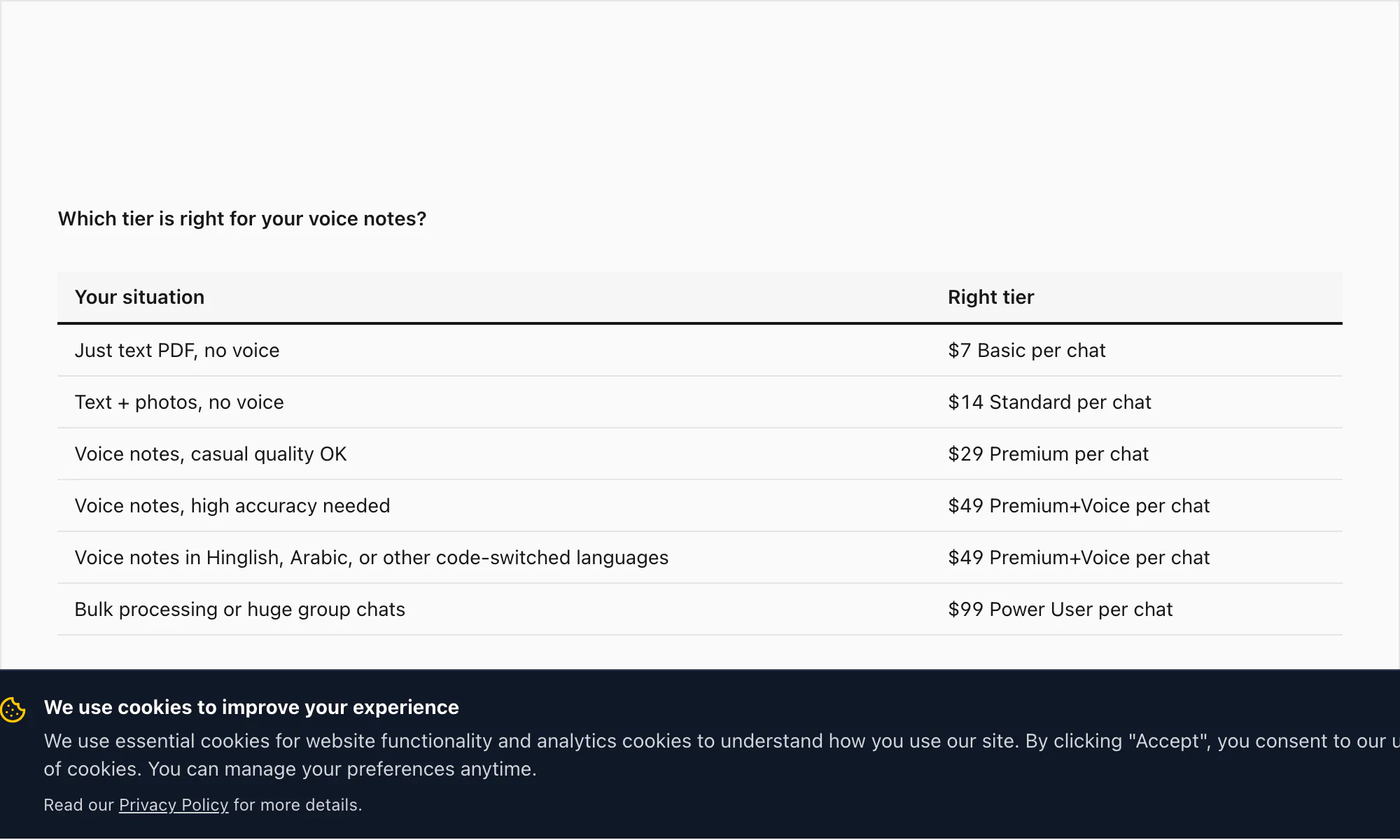
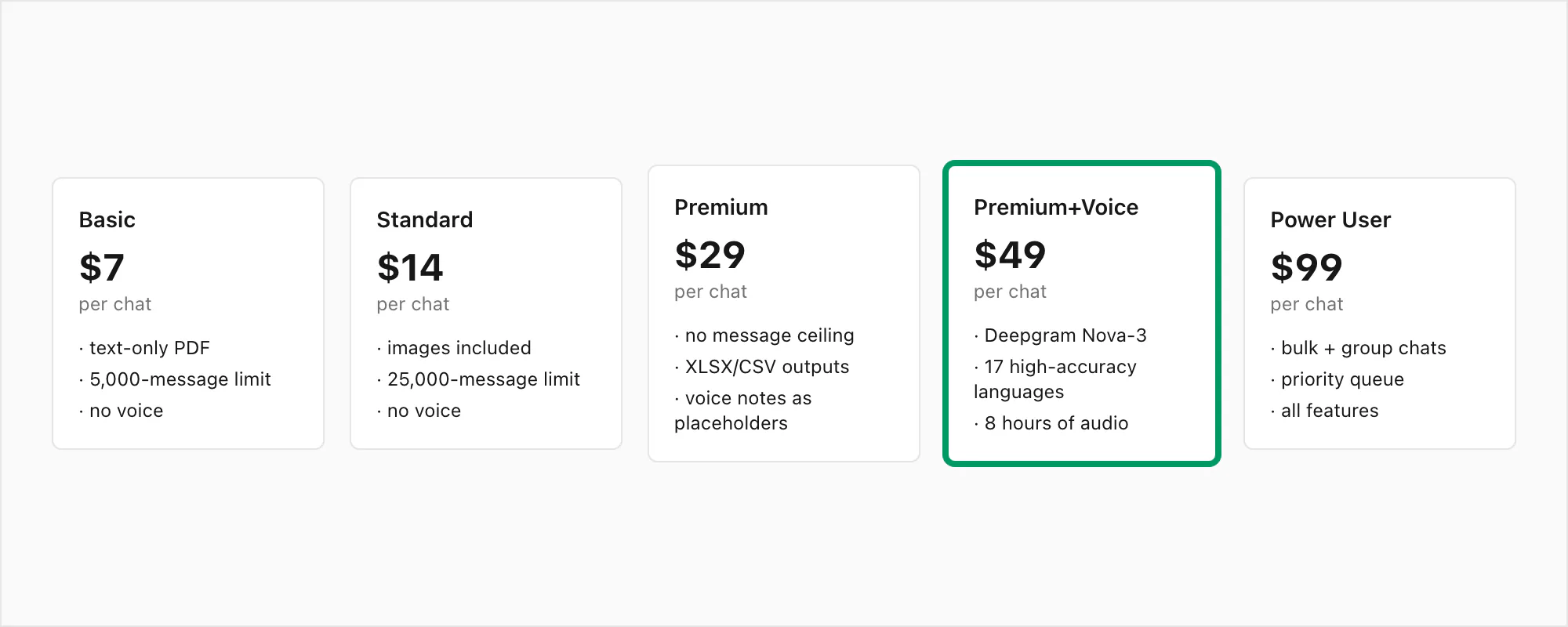
للمرجعية، مكدّس المستويات الكامل: تحويل Basic بـ 7 دولارات لكل دردشة (نصي فقط، حد 5,000 رسالة)، تحويل Standard بـ 14 دولارًا لكل دردشة (صور، حد 25,000 رسالة)، تحويل Premium بـ 29 دولارًا لكل دردشة (بلا حد، XLSX/CSV، الرسائل الصوتية كعناصر نائبة)، تحويل Premium+Voice بـ 49 دولارًا لكل دردشة (تفريغ Nova-3، 17 لغة عالية الدقة، حد 8 ساعات صوتية)، تحويل Power User بـ 99 دولارًا لكل دردشة (تفريغ Nova-3، بلا حد للصوت، قائمة أولوية، سيناريوهات جماعية).
لماذا لا أُفرّغ بشكل فوري (ولن أُضيفه)
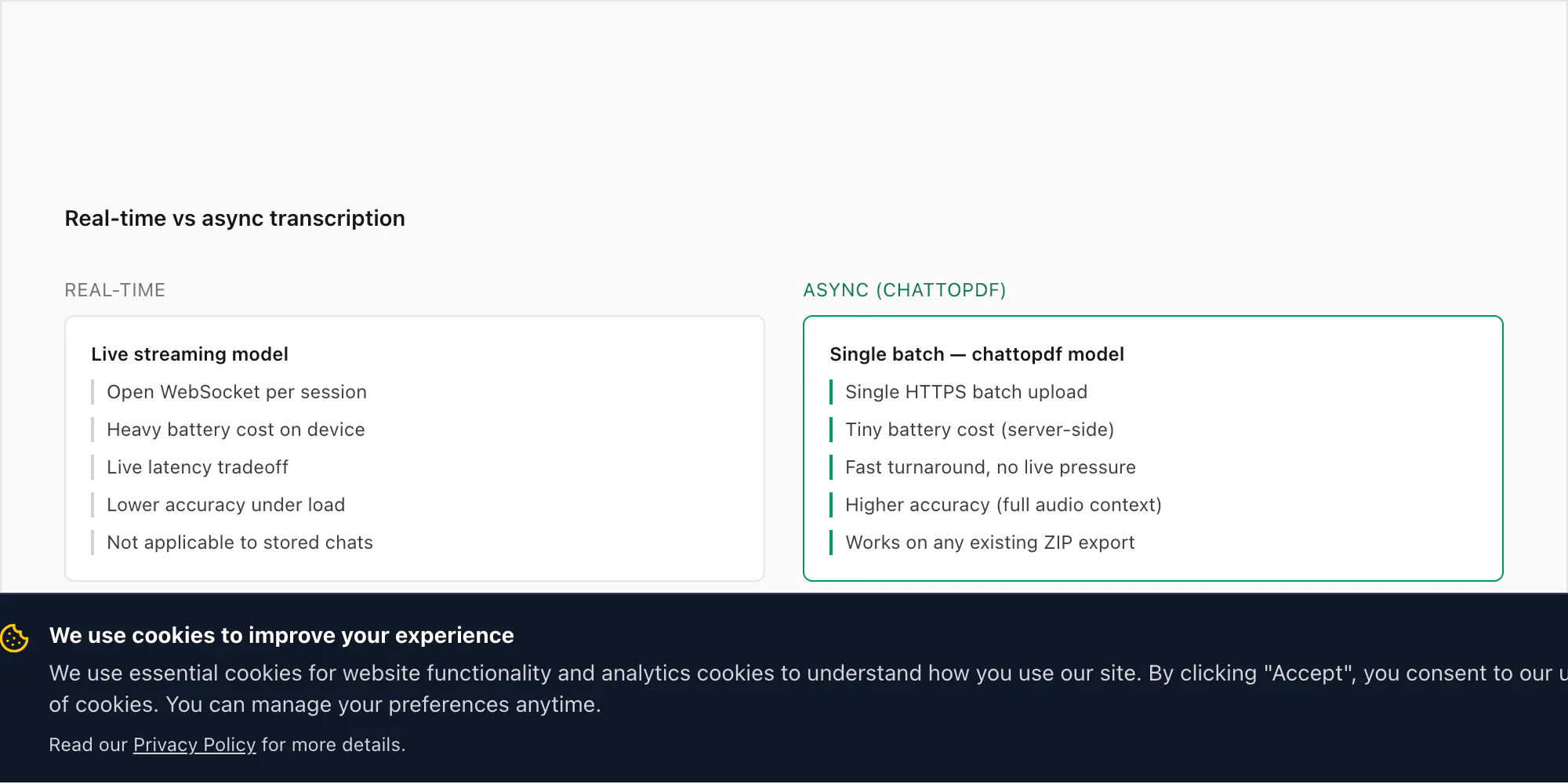
هذا يطرح بما يكفي من التكرار لأستحق إجابة مباشرة. يسأل الناس لماذا لا يستمع ChatToPDF للرسائل الصوتية حين تصل — مُفرِّغًا كل منها في لحظة إرسالها — بدلًا من اشتراط تصدير ZIP بعد الواقعة.
الجواب المختصر: WhatsApp لا يُتيح للمطورين الوصول إلى الرسائل الواردة أو الصوت بشكل فوري. لا يوجد نقطة نهاية رسمية في WhatsApp Business API تُظهر الرسائل الصوتية حين وصولها. مسار الوصول الوحيد المدعوم من طرف ثالث هو من خلال آلية "تصدير الدردشة"، وهي لقطة زمنية لسجل المحادثة. بناء تفريغ فوري على WhatsApp سيتطلب اعتراض التخزين المحلي للتطبيق على الجهاز، وهو هش تقنيًا وخارج شروط سياسات منصة WhatsApp.
لكن ثمة سبب أكثر عملية لعدم محاولتي البناء حول هذا القيد. حالة الاستخدام لتفريغ صوت WhatsApp هي بأكملها تقريبًا استرجاعية. شخص استقبل ثلاثين رسالة صوتية خلال نزاع ويريد سجلًا مقروءًا. فريق عمل يستخدم الرسائل الصوتية لتحديثات المشاريع ويحتاجها قابلة للبحث. عائلة ترسل الرسائل الصوتية لسنوات وتريد أرشفتها قبل تغيير الهاتف. لا شيء من هذا يتضمن متطلب "الآن، حال وصوله". جميعها "لديّ مجموعة تسجيلات أحتاج تحويلها".
المعالجة الدفعية غير المتزامنة أيضًا أكثر دقة. تعمل تحويل الكلام إلى نص الفوري تحت قيود الكمون التي تدفع النموذج نحو استنتاج أسرع (وأقل دقة). يعمل وضع الدفعات في Deepgram على الملف الصوتي كاملًا، مما يسمح للنموذج باستخدام السياق المستقبلي — ما جاء بعد كلمة — لحل الصوتيات الغامضة. في رسالة صوتية مدتها 30 ثانية، الفرق في معدل خطأ الكلمة بين الوضع الفوري والدفعي يمكن أن يصل إلى 2–4 نقاط مئوية. هذا ذو معنى على مقياس الدقة.
ثمة أيضًا سؤال البطارية والشبكة. تشغيل اتصال WebSocket مفتوح يُدفق مقاطع صوتية إلى API استنتاج بشكل فوري سيُنهك بطارية الهاتف بشكل ملحوظ خلال محادثة طويلة. سيتطلب اتصالًا إنترنتيًا نشطًا لكل رسالة صوتية مستقبَلة لا فقط حين تختار التحويل. وسيُنشئ تدفقًا مستمرًا لبيانات محادثاتك إلى خادم طرف ثالث — وهو ما لا أشعر بالارتياح لطلب قبول المستخدمين به.
نموذج التصدير والرفع أبطأ في وقت الساعة — يجب أن تنتظر حتى تصبح جاهزًا للتحويل ثم تُجري التصدير ثم ترفع. لكن لحالات الاستخدام الفعلية لدى الناس، هذا بخير. لا أحد يحاول تفريغ رسالة صوتية استلمها قبل ثلاث ثوانٍ لوثيقة فورية. إنهم يحوّلون محادثة يريدون الاحتفاظ بها.
الخصوصية: أين يذهب صوتك وأين لا يذهب
هذا الجزء الذي أريد التحديد فيه لأن طبيعة الرسائل الصوتية — تسجيلات صوتية لمحادثات حقيقية — تعني أن مخاطر الخصوصية أعلى من الرسائل النصية وحدها.
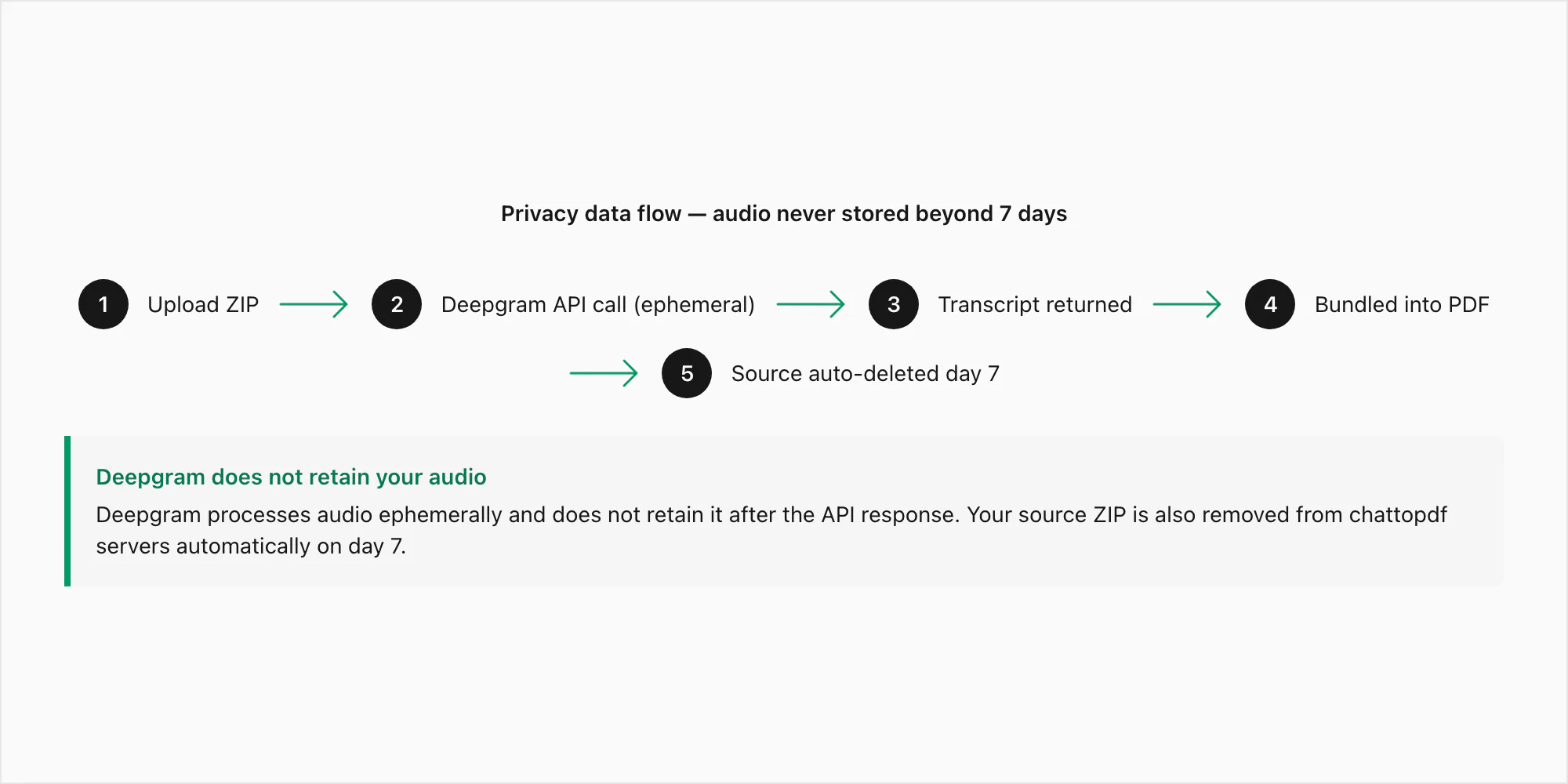
إليك مسار البيانات الدقيق لرسالة صوتية مُقدَّمة عبر تحويل Premium+Voice بـ 49 دولارًا لكل دردشة:
الخطوة 1 — الرفع. يُنقل ملف ZIP من متصفحك إلى خادم ChatToPDF عبر HTTPS (TLS 1.3). الاتصال مُشفَّر أثناء النقل. يصل ZIP إلى دليل معالجة مؤقت لا في التخزين الدائم أثناء الاستخراج.
الخطوة 2 — الاستخراج. تُستخرج ملفات .opus من ZIP. يُطابق كل ملف مع مرجعه في _chat.txt حسب نمط اسم الملف. في هذه المرحلة الملفات الصوتية موجودة فقط على خادم معالجة ChatToPDF.
الخطوة 3 — استدعاء API Deepgram. يُرسَل كل ملف .opus إلى API استنتاج Deepgram عبر استدعاء HTTPS مُوثَّق. هذه هي اللحظة الوحيدة التي تغادر فيها بيانات الصوت البنية التحتية لـ ChatToPDF نفسها. تنص سياسة بيانات Deepgram لإرسالات API على أن الصوت المُقدَّم عبر API يُعالَج بشكل مؤقت — يُستخدم لتوليد التفريغ ثم يُتخلص منه. لا يحتفظ Deepgram بالصوت المُقدَّم عبر API ولا يستخدمه للتدريب. ما يعود هو النص المُفرَّغ.
الخطوة 4 — التخزين. يُجمَّع التفريغ في PDF ويُخزَّن مُشفَّرًا في وضع الراحة (AES-256) في AWS S3. ZIP المصدر بما يشمل ملفات .opus يُخزَّن أيضًا مُشفَّرًا لسبعة أيام.
الخطوة 5 — التسليم. رابط تنزيل PDF يظهر على الشاشة وفي بريدك الإلكتروني. الرابط مرتبط بمعرّف عملك. غير قابل للتخمين وغير مفهرس في أي مكان.
الخطوة 6 — الحذف التلقائي. بعد سبعة أيام من إنشاء العمل يُحذف كل من ZIP المصدر و PDF الناتج من التخزين تلقائيًا. هذا وظيفة حذف مجدولة لا عملية يدوية. لا استثناءات ولا تمديدات.
أين لا يذهب صوتك: لا يذهب إلى أي منصة تحليلات. لا يُستخدم لتدريب نماذج ChatToPDF (ChatToPDF لا يُدرّب نماذج). محتوى نص رسائلك الصوتية غير مرئي لموظفي ChatToPDF — المعالجة آلية بالكامل. لا يتلقى أي طرف ثالث نص رسائل محادثتك.
الفجوة المحتملة الوحيدة في هذا الوصف هي خطوة Deepgram. يمكنني السيطرة الكاملة على ما يحدث في خوادم ChatToPDF. لا يمكنني التصريح بشأن العمليات الداخلية لـ Deepgram بما يتجاوز ما تنص عليه سياسة بياناتهم العامة. إذا كانت رسائلك الصوتية تحتوي معلومات ذات امتياز قانوني أو سرية حقيقية، أوصيك بأن يراجع فريقك القانوني شروط معالجة البيانات المؤسسية لـ Deepgram قبل الرفع. لغالبية حالات الاستخدام — المحادثات الشخصية ودردشات فرق العمل وأرشيفات الرسائل الصوتية العائلية — المسار القياسي مناسب.
الحالات الحدية: الضجيج ومتعددو المُتحدثين والتأثيرات الصوتية
الرسائل الصوتية الحقيقية في WhatsApp لا تُسجَّل في استوديوهات معزولة صوتيًا. تُسجَّل في السيارات والمطابخ والاجتماعات في الشارع والمقاهي الصاخبة. إليك كيف يؤثر كل من هذه السيناريوهات في دقة التفريغ، وما يفعله ChatToPDF حين تنخفض الدقة إلى مستوى غير مقبول.
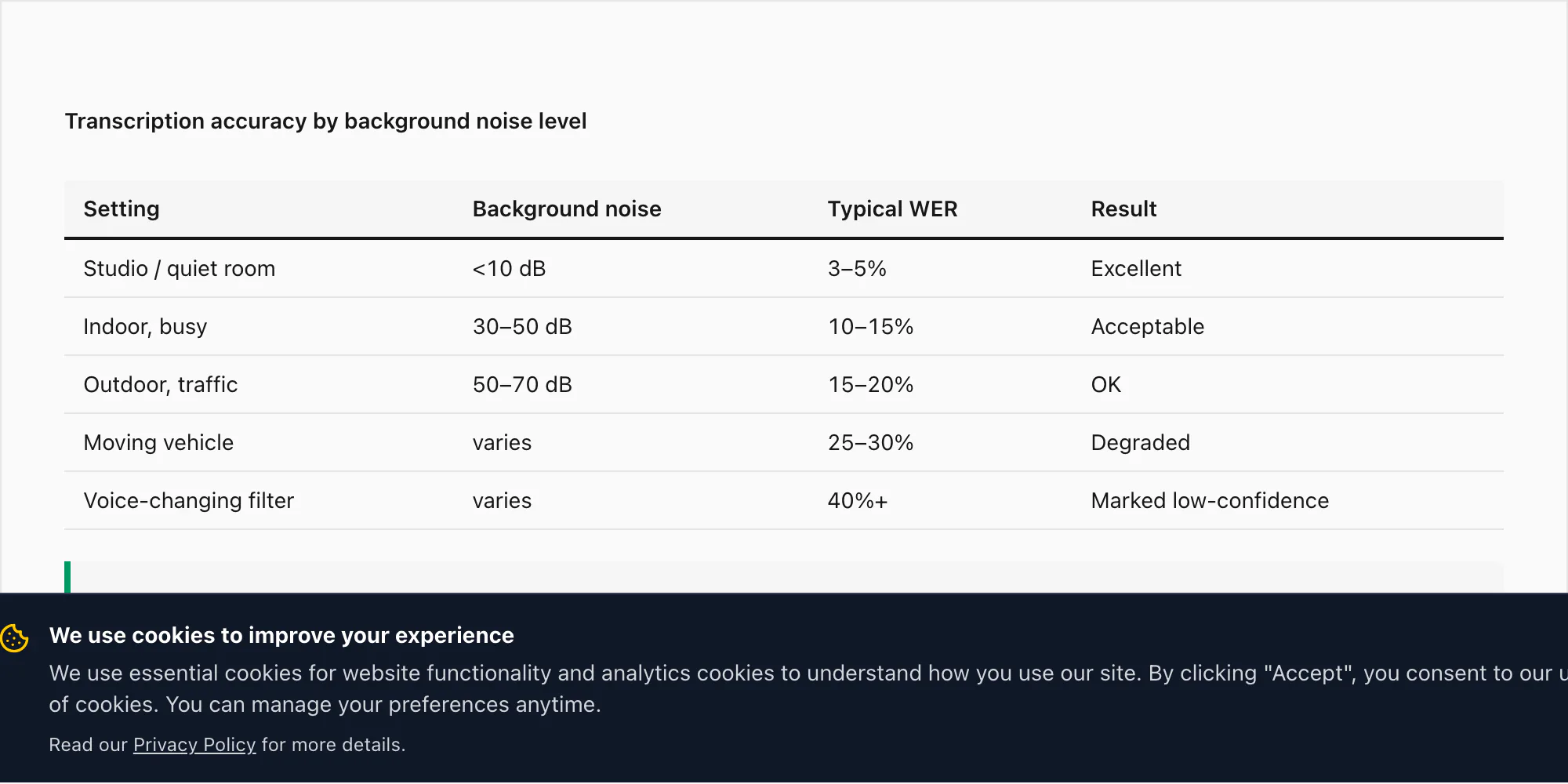
الضجيج الخلفي حسب البيئة.
رسالة صوتية مُسجَّلة في بيئة داخلية هادئة — مكتب أو غرفة نوم أو غرفة ساكنة — تُحقق معدلات الدقة التي ذكرتها في قسم اللغة أعلاه: 3–5% معدل خطأ الكلمة في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة للغات الـ 17 عالية الدقة.
رسالة صوتية من بيئة داخلية مزدحمة (مطعم أو سوق أو مكتب مزدحم) قد ترى ارتفاع معدل خطأ الكلمة إلى 10–15% في تحويل Premium+Voice بـ 49 دولارًا لكل دردشة. يطبّق Nova-3 من Deepgram إلغاء الضجيج أثناء الاستنتاج مما يُساعد، لكنه لا يُلغي تأثير الصوت المتنافس.
التسجيل الخارجي — ضجيج الشارع والريح والمرور — قد يرفع معدل خطأ الكلمة إلى 15–20% للمستوى ذاته.
رسالة صوتية مُسجَّلة أثناء رحلة في مركبة متحركة مع ضجيج الطريق والمحرك هي أصعب سيناريو فردي اختبرته. يمكن أن يصل معدل خطأ الكلمة فيها إلى 25–30% حتى مع Nova-3. هذا ليس قيدًا في محرك التفريغ — إنه يعكس فيزياء الصوت المُلتقط بميكروفون هاتف بـ 16 كيلوهرتز في بيئة صاخبة. جودة الصوت في الإدخال تحدد جودة التفريغ في المخرج.
متعددو المُتحدثين داخل رسالة صوتية واحدة.
كما شرحت سابقًا، كل رسالة صوتية في WhatsApp تنتمي لمُرسِل واحد — الشخص الذي ضغط زر الضغط للتحدث. ينسب ChatToPDF التفريغ لذلك المُرسِل. ومع ذلك، إذا سجّل المُرسِل بينما يتحدث شخص آخر بشكل مسموع في الخلفية (محادثة هاتفية يُجريها المُرسِل أو تلفاز يعمل في الخلفية بصوت أو شخص آخر في الغرفة ذاتها يتحدث بصوت عالٍ)، سيُفرّغ Deepgram الصوت الخلفي أيضًا — لا يتجاهل المُتحدثين غير الرئيسيين بصمت. سيتشابك التفريغ من كلا الصوتين منسوبًا لمُرسِل WhatsApp. يمكن أن يُنتج هذا مخرجات مُربِكة حين يكون الكلام الخلفي مفهومًا بما يكفي للتفريغ.
لا يستطيع ChatToPDF حاليًا عزل المُتحدث الرئيسي وتجاهل الأصوات الخلفية داخل مقطع .opus واحد. تمييز المُتحدثين — تحديد مقاطع الصوت التي جاءت من أي شخص في الملف الصوتي ذاته — ميزة أقيّمها لمستوى مستقبلي، لكنها تتطلب بنية تحتية إضافية وليست في الإصدار الحالي.
التأثيرات الصوتية.
يُرسل بعض مستخدمي WhatsApp رسائل صوتية بتأثيرات صوتية مُطبَّقة — مرشّح الصوت العميق المتاح في WhatsApp نفسه (Android)، أو تغييرات صوتية بنمط Snapchat قبل المشاركة، أو مجرد صوت خُفِّض طبقته أو أُضيف إليه صدى قبل الإرسال. نموذج Deepgram مُدرَّب على الكلام الطبيعي. الصوت المُعدَّل يمكن أن يرفع معدل خطأ الكلمة فوق 40% في الحالات القصوى — رسالة صوتية مُرسَلة عبر مرشّح صوت عميق لإسماع شخص ما كربوت ستفشل إلى حد كبير في التفريغ.
للمقاطع التي تنخفض فيها الثقة دون العتبة التي حددتها في المسار — مُعرَّفة حاليًا بمتوسط درجة ثقة الكلمة أقل من 0.6 عبر المقطع — يُعلّم ChatToPDF التفريغ في PDF كـ [تفريغ منخفض الثقة — جودة الصوت غير كافية] بدلًا من إخراج كتلة نص قد تُؤخذ على أنها موثوقة. ستشاهد هذه العلامة في PDF النهائي جنبًا إلى جنب مع موضع الرسالة الصوتية في المحادثة. من الأفضل الإشارة إلى نتيجة غير مؤكدة من إعادة تفريغ يبدو معقولًا لكنه خاطئ بنسبة 40%.
الأسئلة الشائعة
ما صيغة ملف الرسائل الصوتية في WhatsApp وهل يتعامل معها ChatToPDF؟
يسجّل WhatsApp الرسائل الصوتية باستخدام ترميز Opus بـ 16 كيلوهرتز أحادي القناة ويحفظها كملفات .opus. يستخرج ChatToPDF ملفات .opus مباشرةً من ZIP تصدير WhatsApp ويُرسلها إلى API استنتاج Deepgram بصيغتها الأصلية — لا حاجة لخطوة إعادة ترميز. تصديرات كل من iPhone و Android تُنتج ملفات .opus، لذا التعامل مع الصيغة متطابق على كلتا المنصتين.
ما مدى دقة تفريغ صوت WhatsApp؟
تعتمد الدقة على المستوى وجودة الصوت. تحويل Premium+Voice بـ 49 دولارًا لكل دردشة يستخدم Deepgram Nova-3 الذي يُحقق نحو 3–5% معدل خطأ الكلمة على الصوت النظيف الخالي من الضجيج في اللغات الـ 17 المدعومة عالية الدقة. تحويل Power User بـ 99 دولارًا لكل دردشة يستخدم نفس نموذج Nova-3 بلا حد للصوت وأولوية القائمة. تحويل Premium بـ 29 دولارًا لكل دردشة لا يُفرِّغ — يحفظ الرسائل الصوتية كمراجع عنصر نائب في PDF. الضجيج الخلفي واللهجات والتبديل بين اللغات تؤثر جميعها في الدقة في المستويات المُفرِّغة. أُعلِّم المقاطع منخفضة الثقة (أقل من 0.6 متوسط درجة ثقة الكلمة) كـ [تفريغ منخفض الثقة] في PDF بدلًا من تقديم تفريغ قد يكون مُضلِّلًا.
هل يُفرّغ ChatToPDF الرسائل الصوتية بلغات غير الإنجليزية؟
نعم. تحويل Premium+Voice بـ 49 دولارًا لكل دردشة وتحويل Power User بـ 99 دولارًا لكل دردشة يدعمان 17 لغة عالية الدقة: الإنجليزية والإسبانية والبرتغالية والفرنسية والألمانية والإيطالية والعربية والهندية والإندونيسية والتركية والروسية والهولندية واليابانية والكورية والصينية والفيتنامية والتايلاندية. يستخدم كلا المستويين Deepgram Nova-3 عبر هذه اللغات ويكتشفان أكثر من 30 لغة إضافية بنطاق دقة أوسع. تُكتشف اللغة تلقائيًا — لا حاجة لتحديدها قبل الرفع. تحويل Premium بـ 29 دولارًا لكل دردشة لا يُفرّغ الرسائل الصوتية — يحفظها كمراجع عنصر نائب في PDF.
هل أحتاج فعل أي شيء مختلف عند التصدير من WhatsApp إذا أردت تفريغات صوتية؟
نعم — خطوة واحدة حرجة. حين تُصدّر محادثتك من WhatsApp اختر "تضمين الوسائط" لا "بدون وسائط". الرسائل الصوتية (ملفات .opus) تُضمَّن في التصدير فقط حين تختار "تضمين الوسائط". إذا صدّرت "بدون وسائط" سيحتوي _chat.txt مراجع مثل <attached: 00000012-AUDIO-2024-03-15-09-22-31.opus> لكن لا ملفات صوتية فعلية. ChatToPDF لا يستطيع تفريغ رسالة صوتية لا يملكها. راجع دليل تصدير محادثة WhatsApp للعملية كاملة خطوة بخطوة.
هل ستظهر التفريغات الصوتية في المكان الصحيح في PDF؟
نعم. يقرأ ChatToPDF سجل الرسائل في _chat.txt ليفهم بنية المحادثة، يُطابق كل مرجع .opus مع الملف الصوتي المقابل بالاسم، ويُدرج التفريغ في الموضع الدقيق في المحادثة حيث أُرسلت الرسالة الصوتية. اسم المُرسِل من بيانات WhatsApp الوصفية والطابع الزمني الأصلي يظهران جنبًا إلى جنب مع التفريغ. المخرج وثيقة واحدة تتناوب فيها الرسائل النصية وتفريغات الرسائل الصوتية بالترتيب الزمني الصحيح.
ماذا يحدث لملفاتي الصوتية بعد اكتمال التفريغ؟
تُخزَّن ملفاتك الصوتية مُشفَّرةً في وضع الراحة (AES-256) على خوادم ChatToPDF لسبعة أيام بعد إنشاء العمل ثم تُحذف تلقائيًا. الخدمة الوحيدة التابعة لطرف ثالث التي تتلقى بيانات الصوت هي Deepgram، وذلك فقط أثناء خطوة التفريغ — يعالج Deepgram الصوت المُقدَّم عبر API بشكل مؤقت ولا يحتفظ به. لا يستمع إنسان إلى تسجيلاتك. تُحذف التفريغات نفسها مع الملفات المصدر عند علامة الأيام السبعة. للمزيد من التفاصيل حول مسار البيانات الكامل، راجع قسم الخصوصية في WhatsApp to PDF.
هل يستطيع ChatToPDF تمييز شخصين مختلفين يتحدثان في نفس الرسالة الصوتية؟
ليس حاليًا. كل رسالة صوتية في WhatsApp تُنسب للشخص الذي أرسلها باستخدام معلومات المُرسِل من _chat.txt. داخل رسالة صوتية واحدة إذا تحدث كل من المُرسِل وشخص آخر (مثلًا المُرسِل يُجري محادثة هاتفية أثناء التسجيل)، يُفرَّغ الصوتان لكن يُنسبان لمُرسِل WhatsApp. ChatToPDF لا يُجري حاليًا تمييز المُتحدثين داخل المقاطع الصوتية الفردية. للرسائل الصوتية التي تسمع فيها أصوات خلفية ومفهومة، قد ترى كلامًا متشابكًا في التفريغ.
Key takeaways
- لـ transcribe WhatsApp audio صدّر محادثتك مع اختيار "تضمين الوسائط" — يجب أن تكون ملفات
.opusللرسائل الصوتية داخل ZIP - تحويل Premium بـ 29 دولارًا لكل دردشة لا يُفرّغ — يحفظ الرسائل الصوتية كمراجع عنصر نائب؛ تحويل Premium+Voice بـ 49 دولارًا لكل دردشة يُشغّل Deepgram Nova-3 (معدل خطأ الكلمة 3–5% على الصوت النظيف، 17 لغة عالية الدقة، حتى 8 ساعات صوتية)؛ تحويل Power User بـ 99 دولارًا لكل دردشة نفس النموذج بلا حد مع قائمة أولوية
- يُدرَج كل تفريغ في الموضع الدقيق في المحادثة مع حفظ اسم مُرسِل WhatsApp والطابع الزمني الأصلي
- اللغات المُبدَّلة بين الكودات كالهنجلش تحتاج تحويل Premium+Voice بـ 49 دولارًا لكل دردشة أو أعلى — Nova-3 يُغلق معظم الفجوة التي فتحتها محركات STT القديمة في الإدراجات الإنجليزية في منتصف الجملة الهندية
- الضجيج الخلفي هو المتغير الأكبر في الدقة: ظروف الاستوديو تُنتج 3–5% معدل خطأ الكلمة؛ التسجيلات الخارجية أو في السيارة قد تصل إلى 20–30% حتى مع Nova-3
- الصوت المُقدَّم لـ Deepgram للتفريغ يُعالَج بشكل مؤقت — لا يُحتفظ به ولا يُستخدم للتدريب؛ الملفات المصدر تُحذف تلقائيًا من خوادم ChatToPDF بعد 7 أيام
- المقاطع التي ينخفض فيها متوسط ثقة الكلمة دون 0.6 تُعلَّم كـ
[تفريغ منخفض الثقة]في PDF بدلًا من إعادة تفريغ محتمل الخطأ بصمت
لسير عمل الدردشة إلى PDF الكامل — بما يشمل كيفية التصدير على iPhone و Android وما يحتويه ZIP وكيف تقارن المستويات الخمسة للتحويلات غير الصوتية — راجع دليل WhatsApp to PDF. إذا كنت على Android وتحتاج نقل التصدير إلى جهاز مختلف قبل الرفع، يغطي دليل نقل WhatsApp من Android إلى iPhone تلك العملية.
I'm Paul. I built ChatToPDF after watching a friend try to print a 4-year-old WhatsApp chat across forty-something one-page PDFs. I write here about exporting WhatsApp chats, converting them to PDF, transcribing voice notes, and the messy edge cases nobody else writes about (40,000-message export limits, broken emojis, RTL Arabic, Samsung Secure Folder).